scrapy 分页爬取以及xapth使用小技巧
这里以爬取www.javaquan.com为例:
1.构建出下一页的url:
很显然通过dom树,可以发现下一页所在的a标签
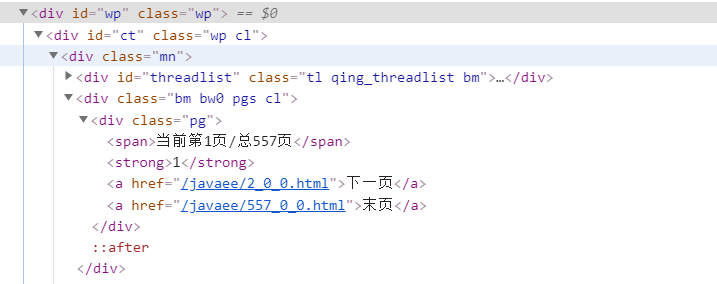
2.使用scrapy的yield scrapy.Reqeust(next_url,callback=self.parse) 构造下一页爬取的请求

Tips:使用xpath解析dom的常用处理方法:
1.查询页面上所有的div元素 : //div
2.查询页面上指定的元素 :
-通过class属性定位 例如: div[@class='xxxx']
-通过其他属性去定位 例如 div[@size='xxxxx']
-通过元素包含的文本去定位 例如: a[contains(string(),'下一页')]
3.获取标签中的文本: 例如: /a/text() 获取a标签中得到文本
4.获取标签中的属性值: 例如/a/@href
5.extract_first() 与 extract() 区别
extract_first() 解析标签的值,取第一个
extract() 解析标签的值,取所有值
6.url返回的dom结构,可能与页面显示的dom结构不一致,chrome调试时需要注意,例如tbody的问题
7.获取某个标签下的所有子标签可以使用列表 例如 response.xpath("//tbody[@id='normalthread_14']/tr")[0:-1]