参考博客:https://www.cnblogs.com/Peyton-Li/p/7620266.html
模型小型化旨在保证模型效果不会明显下降的情况下降低模型的参数量,从而提高模型的运算速度。
以下是几种模型小型化的方法:
1、修改某些卷积层的num_output
其实很多模型的参数都有冗余,有些层根本不需要很多的卷积核,所以,通过修改该参数可以降低一部分的参数量。
2、使用分离通道卷积(depthwise separable convolution)
对某些卷积层使用分离通道卷积的方法。使用分离通道卷积可以去掉一部分冗余的参数。分离通道卷积与常用卷积的不同之处在于,标准卷积操作中,每个卷积核都要对输入的所有通道的特征进行卷积,然后结合生成一个对应的特征。分离通道卷积中,分为两步,第一步使用分离通道卷积,每个卷积核只对一个通道进行卷积。第二步,使用1x1的标准卷积整合分离通道卷积输出的特征。分离通道卷积时,各个通道之间的特征信息没有交互,之后会采用一个1*1的标准卷积运算,使分离通道卷积输出的特征的通道之间的信息有了一个交互。在tensorflow中,有对应的tf.nn.depthwise_conv2d接口可以很方便地实现分离通道卷积。标准卷积和分离通道卷积的示意图如下
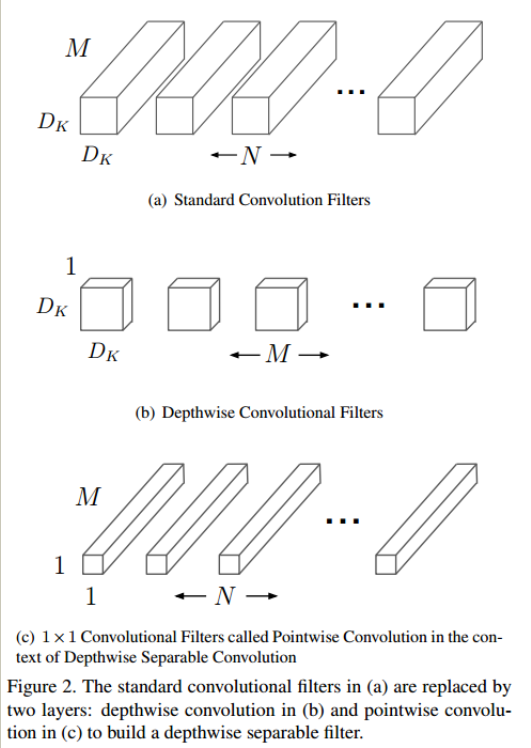
参考论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
3、使用channel shuffle方法
channel shuffle方法是在分离通道卷积方法的基础上做的改进,将分离通道卷积之后的1*1的全卷积替换为channel shuffle。
参考论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
4、使用ThiNet方法
ThiNet方法是寻找一些对输出特征贡献较小的卷积核,将其裁剪掉,从而降低参数量。属于第一种方法的延伸。
参考论文:ThiNet: A Filter Level Pruning Method for Deep Neural Network Compression
5、改变网络结构
现在常见的网络结构有:以VGG为代表的单支流网络结构,GoogLeNet的Inception类型的网络结构,ResNet的残差结构,还有DenseNet的结构(类似残差结构,把残差结构中特征的相加变为特征拼接)。在曾经的ImageNet的比赛中,GoogLeNet取得了比VGG更好的成绩,但是GoogLeNet的参数量却比VGG小很多,这说明通过改变网络结构,我们不仅可以减低模型的参数量,还可能会提升模型的效果。
前四种方法都是在原有网络上进行的操作,一般不会对网络结构造成太大改变。而第五种方法则是彻底改变了网络的结构。
我们将模型的参数量降低后,如果随机初始化,模型由于参数量较小,很难达到原有的效果,所以构造了新的网络之后还会涉及到重构。
重构其实是为了得到一个较好的初始化模型。我们一般去重构网络的倒数第二层的输出特征,因为最终的结果都是在倒数第二层的输出特征上得到的。但有时我们还会去重构其他卷积层输出的特征,比如一个较深的网络,我们单纯地去重构倒数第二层的特征也很难得到一个较好的初始化模型,因为监督信息(即重构时的loss)太靠后,前面的层很难学习到,所以有时我们可以将网络分为几个部分,依次重构,先重构前面的,然后使用重构好的模型去重构后面的部分。
使用ThiNet方法,每裁剪完一层之后都要做finetuning,然后再裁剪下一层。我们也可以每裁剪完一层之后去做重构,全部都裁剪完之后,做姿态估计训练。