相信大家都使用过redis,对redis的数据结构也有所了解。那么今天就从redis的数据结构的底层实现来研究下它为啥如此高性能。
一.字符串
1.1 redis字符串的应用场景
redis没有直接用C语言传统的字符串表示(以空字符串结尾的字符数组),而是自己创建了一种名为简单动态字符串的抽象类型(simple dynamic string,SDS)。
不过在redis里面也会用到c字符串,但是它只作为字符串字面量用在一些无须对字符串值进行修改的地方,比如日志的打印。
当redis需要的是一个可以修改的字符串值时,那么就会用SDS来表示字符串值,比如redis的数据库里,包含字符串的键值对在底层都是由SDS实现的。
比如 客户端执行
redis> set str "hello" OK
那么redis将在数据库创建一个新的键值对,其中 键值对的key是一个字符串对象,对象的底层实现是一个保存着 "str"的SDS。
键值对的value也是一个字符串对象,对象的底层实现也是一个保存着 "hello"的SDS。
又比如,客户端执行命令:
redis>rpush fruits "banana" "pair" "apple"
那么redis将在数据库创建一个新的键值对,其中
键值对的键是一个字符串对象,对象的底层实现是一个保存着 "fruits"的SDS。
键值对的value是一个列表对象,列表对象包含了都由sds实现的三个字符串对象。
除了用来保存数据库中的字符串值以外,sds还被用来用作缓冲区等模块。
1.2 sds的定义
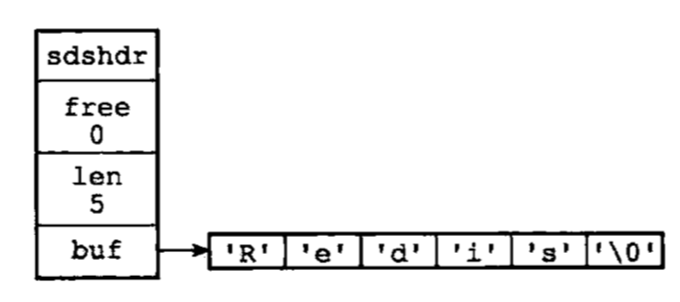
如上图所示:每个sds.h/sdshdr结构表示一个SDS值:
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于SDS所保存字符串的长度
int len;
//记录buf数组中未使用的字节数量
int free;
//字节数组,用于保存字符串
char buf[];
}
free = 0,表示这个sds没有可分配的使用空间。
len = 5,表示保存了一个5字节长的字符串。
buf属性是一个char类型的数组,数组前五个字节包存了'R','e','d','i','s'五个字符,而最后一个字节保存了空字符'�'。
SDS遵循C字符串的空字符结尾的惯例的好处是,SDS可以直接重用一部分C字符串函数库里面的函数。另外SDS里面的空字符的1字节空间不计入len属性中。
1.3 SDS与字符串的区别
(1).常熟复杂度O(1)获取字符串长度
C字符串不记录自身长度信息,所以为了获取C字符串的长度,程序必须遍历整个字符串,所以这个操作的复杂度是O(N),
而SDS通过len属性记录了自身的字符串长度,所以复杂度是O(1)。
(2).杜绝缓冲区溢出
当SDS API需要对SDS进行修改时,API会先检查SDS的空间是否满足要求,如果不满足,API将会自动将SDS的空间扩展至执行修改所需的大小,
然后才去执行实际的修改操作。
而传统的c字符串由于不知道自身的长度,当修改字符串时可能会导致缓冲区溢出问题。
(3).减少修改字符串时带来的内存重分配次数
先看看C字符串的数组进行一次内存重分配操作: -如果程序执行增常字符串操作,比如append操作,程序需要通过内存重分配来扩展底层数组的空间大小---如果忘了,会导致缓冲区溢出。 -如果程序猿执行缩短字符串操作,比如trim,如果忘记铜鼓内存重分配释放不再使用的空间,就会产生内存泄漏。 而SDS通过 空间预分配和惰性空间释放不会有以上问题。 空间预分配就是 当对SDS进行修改以后,SDS的长度(len属性值)将小于1MB,那么程序分配和len属性值同样大小的未使用空间;如果SDS的长度(len属性值)将>=1MB,那么程序分配1MB大小的未使用空间 惰性空间释放就是,SDS空间释放后,只要修改free属性的值就好
(4).二进制安全
其实就是文本信息含有多个空字符时,sds对其中的数据不做任何限制,数据写入时怎么样,读出来还是怎么样。 而C字符串不行,如下图所示,C字符串这只能读取到Redis
![]()
(5).兼容部分C字符串函数
1.3 总结
二.链表
redis列表键的底层实现之一就是链表。当一个键包含了数量较多的元素,又或者列表中包含的元素都是比较长的字符串时,redis就会使用链表作为列表键的底层实现
除了链表键以外,发布与订阅,慢查询,监视器等功能也用到了链表。
2.1 链表和链表节点的实现
每个链表节点使用一个adlist.h/listNode结构来表示
typedef struct listNode{
//前置节点
struct listNode *prev;
//后置节点
struct listNode *next;
//节点的值
void *value;
}listNode;
多个listNode通过prev和next指针组成一个双端链表,如下图所示;

虽然仅仅使用多个listNode来组成链表,但是用adlist.h/list 来操作链表要方便很多。
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void *(*free)(void *ptr);
//节点值对比函数
void *(*match)(void *ptr);
}list;
list结构为链表提供了表头指针head,表尾指针tail,以及链表长度计数器len。另外还有dup,free,match这些函数。
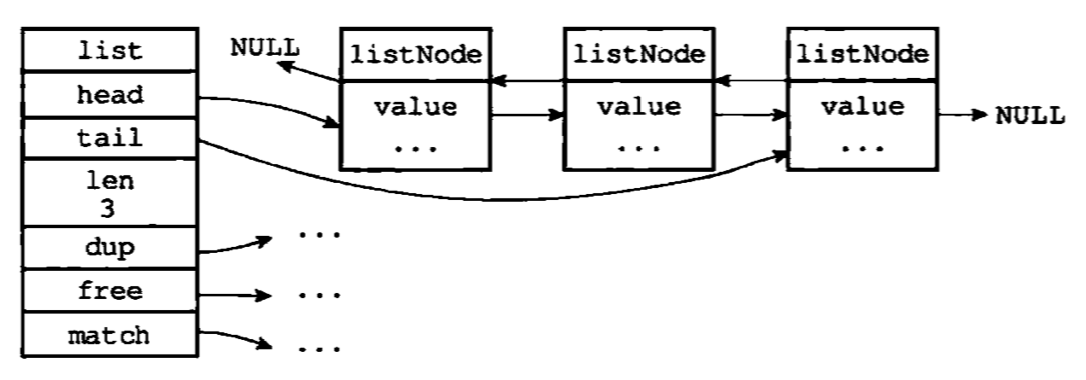
redis的链表特性可以总结如下: 1.双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)。 2.无环:表头节点的prev指针和表尾节点的next指针都指向null,对链表的访问以null为终点。 3.带表头指针和表尾指针:通过list结构的head指针和tail指针,程序获取链表的表头节点和表尾节点的复杂度是O(1)。 4.带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)。 5.多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup,free,match三个属性为节点值设置类型特定函数,所以链表可以用于保存各种不同类型的值。
三.字典
字典,又称为符号表(symbol table),关联数组(associative array)或者映射(map),是一个用于保存键值对的抽象数据结构。
redis数据库就是使用字典来作为底层实现的,对数据库的增删改查操作也是构建在对字典的操作之上的。字段还是哈希键的底层实现之一,当一个哈希键包含的键值对比较多,又或者键值对中的元素比较长的时候,redis就会使用字典作为哈希键的底层实现。
redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希节点就保存了字典中的一个键值对。
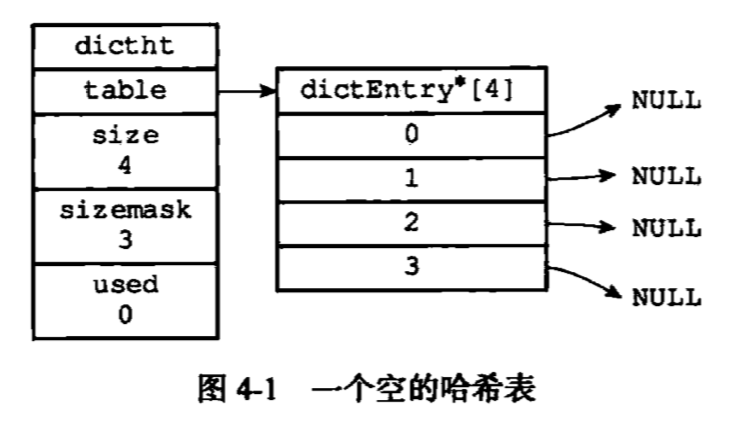
1.哈希表
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于size-1
unsigned long sizemask;
//该哈希表已有节点数量
unsigned long used;
}dictht;
table是一个数组,数组中每个元素都是一个指向dict.h/dictEntry结构的指针,每个dictEntry结构都保存着一个键值对。
2.哈希表节点
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;
key保存着键值对的键;
而v属性则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个uint64_t整数,又或者是一个int64_t整数;
next 属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,以此解决键冲突的问题。

3.字典
typedef struct dict{
//类型特定函数
dictType *type;
//私有数据
void *privdata;
//哈希表
dictht ht[2];
//rehash索引
//当rehash不在进行时,值为-1
int rehashidx;
}dict;
type和privdata属性是针对不同类型的键值对,为创建多态字典而设置的;
ht属性是包含两个项的数组,每个项都是一个dictht哈希表,一般情况下,字典桌子使用ht[0],ht[1]哈希表侄仔进行rehash时使用。还有一个属性rehashidx,记录的是rehash目前的进度。
附图看看就能理解了:

至于哈希算法和rehash操作将在下次附上。