1 目的
一个好的过滤算法需要具备的特征有:低时间复杂度、低空间复杂度、低错误率。本算法从低时间复杂度(算法只需要读取一次文件)和空间复杂度出发,通过寻找它们的平衡点以达到低错误率。
2 原理
当需要判断一个元素是不是在一个集合中,我们通常做法是把所有元素保存下来,然后通过比较知道它是不是在集合内,链表、树都是基于这种思路,当集合内元素个数的变大,我们需要的空间和时间都线性变大,检索速度也越来越慢。 BloomFilter采用的是哈希函数的方法,将一个元素映射到一个m长度的阵列上的一个点,当这个点是 1 时,那么这个元素在集合内,反之则不在集合内。这个方法的缺点就是当检测的元素很多的时候可能有冲突,解决方法就是使用k个哈希函数对应k个点,如果所有点都是 1 的话,那么元素在集合内,如果有 0 的话,元素则不在集合内。
根据此原理可以推断出总的误判个数期望为

具体的证明可以看参考的博客链接
假设去重后总量为1亿条,可利用内存最大为1G,也就是位数组长度2^33为 ,则可预估如下表结果:
|
假设总量: |
1亿 |
|
|
|
|
|
Hash个数 |
h=3 |
h=4 |
h=5 |
h=6 |
h=7 |
|
误判数 |
1022 |
87 |
10 |
2 |
0 |
|
误判率 |
1.02E-05 |
8.70E-07 |
1.00E-07 |
2.00E-08 |
0.00E+00 |
为此,在执行中只需要将哈希函数的个数设置为7个即可保证很大程度上与真实总量一致.
3 执行步骤

4 算法的改进
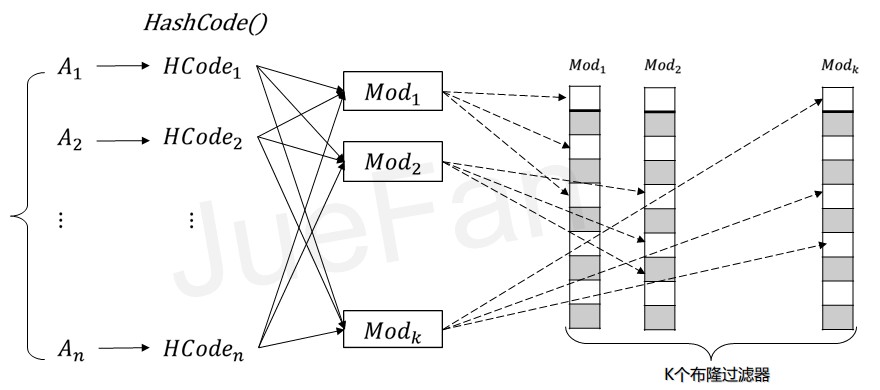
与传统的布隆过滤器相比
优势:每个字符串只进行一次数值转换,传统做法是多个Hash函数产生多个值,我们只产生一个值,利用多Mod对该值取余(等价于多Hash函数),减少多次Hash函数值转换带来的运行时间。
劣势:貌似可以证明与传统的算法的空间复杂度与准确率均相等,所以暂时说不出啥缺点
对于一个字符串,经过HashCode转换成对应的数值,分别对K个大素数进行求余操作,并查找对应的小布隆过滤器相对的位置是否为1,如果均为1则该字符串已经包含其中,否则是新字符串,既而对相应的位置数值更改为1.
本人用这套思路在java上实现了,判断1亿条数据,占用内存700M,准确率达100%
具体的实现代码可查阅本人的Github:
https://github.com/JueFan/BloomFilterTool
参考博客