数据集来源于Kaggle(一个为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台),原数据集有12500只猫和12500只狗,分为训练、测试两个部分。


2、什么是Knn算法:
K最近邻(k-Nearest Neighbor,KNN)基本思想:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。

如果用比较平实的话来说,就是“我们已经存在了一个带标签的数据库,现在输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)的分类标签。”
上图中的对象可以分成两组,蓝色方块和红色三角。每一组也可以称为一个类。我们可以把所有的这些对象看成是一个城镇中房子,而所有的房子分别属于蓝色和红色家族,而这个城镇就是所谓的特征空间。(你可以把一个特征空间看成是所有点的投影所在的空间。例如在一个 2D 的坐标空间中,每个数据都两个特征 x 坐标和 y 坐标,你可以在 2D 坐标空间中表示这些数据。如果每个数据都有 3 个特征呢,我们就需要一个 3D 空间。N 个特征就需要 N 维空间,这个 N 维空间就是特征空间。在上图中,我们可以认为是具有两个特征色2D空间)。
现在城镇中来了一个新人,他的新房子用绿色圆盘表示。我们要根据他房子的位置把他归为蓝色家族或红色家族。我们把这过程成为分类。我们应该怎么做呢?因为我们正在学习看 kNN,那我们就使用一下这个算法吧。
一个方法就是查看他最近的邻居属于那个家族,从图像中我们知道最近的是红色三角家族。所以他被分到红色家族。这种方法被称为简单近邻,因为分类仅仅决定与它最近的邻居。但是这里还有一个问题。红色三角可能是最近的,但如果他周围还有很多蓝色方块怎么办呢?此时蓝色方块对局部的影响应该大于红色三角。所以仅仅检测最近的一个邻居是不足的。所以我们检测 k 个最近邻居。谁在这k个邻居中占据多数,那新的成员就属于谁那一类。如果 k 等于 3,也就是在上面图像中检测 3 个最近的邻居。他有两个红的和一个蓝的邻居,所以他还是属于红色家族。但是如果 k 等于 7 呢?他有 5 个蓝色和 2 个红色邻居,现在他就会被分到蓝色家族了。k 的取值对结果影响非常大。更有趣的是,如果 k 等于4呢?两个红两个蓝。这是一个死结。所以 k 的取值最好为奇数。这中根据 k个最近邻居进行分类的方法被称为 kNN。
在 kNN 中我们考虑了 k 个最近邻居,但是我们给了这些邻居相等的权重,这样做公平吗?以 k 等于 4 为例,我们说她是一个死结。但是两个红色三角比两个蓝色方块距离新成员更近一些。所以他更应该被分为红色家族。那用数学应该如何表示呢?我们要根据每个房子与新房子的距离对每个房子赋予不同的权重。距离近的具有更高的权重,距离远的权重更低。然后我们根据两个家族的权重和来判断新房子的归属,谁的权重大就属于谁。这被称为修改过的kNN。
那这里面些是重要的呢?
1、我们需要整个城镇中每个房子的信息。因为我们要测量新来者到所有现存房子的距离,并在其中找到最近的。如果那里有很多房子,就要占用很大的内存和更多的计算时间。
2、训练和处理几乎不需要时间
那么,KNN算法的运算复杂度,想想都很大;但是它的实现思路,却很简单直接。
算法流程
1. 准备数据,对数据进行预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
优点
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
缺点
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
可理解性差,无法给出像决策树那样的规则。
OpenCV:图像处理
Numpy 数值处理
scipy :包含致力于科学计算中常见问题的各个工具箱
Matplotlib:绘图
4、简单例子(e1.py)
举一个简单的例子,和上面一样有两个类。我们将红色家族标记为 Class-0,蓝色家族标记为 Class-1。还要再创建 25 个训练数据,把它们非别标记为 Class-0 或者 Class-1。
Numpy中随机数产生器可以帮助我们完成这个任务。
然后借助 Matplotlib 将这些点绘制出来。红色家族显示为红色三角;蓝色家族显示为蓝色方块
# -*- coding: utf-8 -*-
"""
Created on Tue Jan 28 18:00:18 2014
@author: duan
"""
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 生成待训练的数据
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# 生成待训练的标签
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# 在图中标记红色样本
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# 在图中标记蓝色样本
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
# 产生待分类数据
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
# 训练样本并产生分类
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
ret, results, neighbours, dist = knn.findNearest(newcomer, 5)
# 打印结果
print("result: ", results)
print("neighbours: ", neighbours)
print("distance: ", dist)
plt.show()运行结果
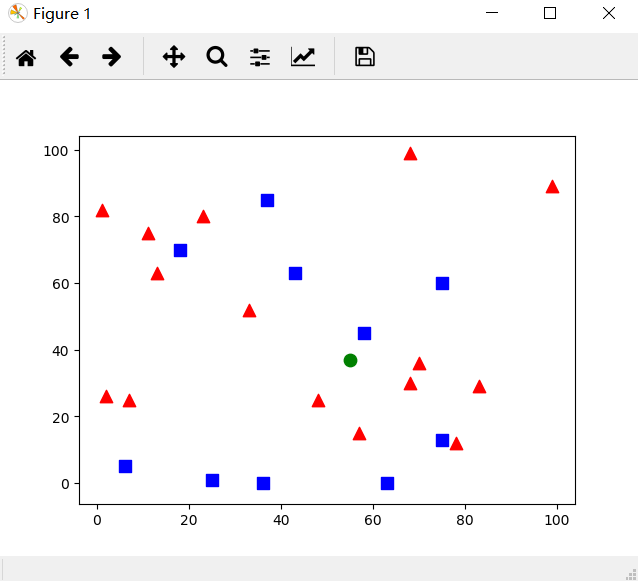
当然这是一个随机的结果,每次运行都会有一些不同。在这次运算中
绿圆旁边红色三角形居多,所以被判定为红色三角形。
5、使用 kNN 对手写数字 OCR(e2.py)
OpenCV 安装包中有一副图片(/samples/python2/data/digits.png), 其中有 5000 个手写数字(每个数字重复 500遍)
编写代码
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('E:/template/digits.png')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 每个数字是一个20x20的小图,第一步就是将这个图像分割成5000个不同的数字
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
# Make it into a Numpy array. It size will be (50,100,20,20)
x = np.array(cells)
# Now we prepare train_data and test_data.
train = x[:,:50].reshape(-1,400).astype(np.float32) # Size = (2500,400)
test = x[:,50:100].reshape(-1,400).astype(np.float32) # Size = (2500,400)
# Create labels for train and test data
k = np.arange(10)
train_labels = np.repeat(k,250)[:,np.newaxis]
//直接用训练的结果进行测试
test_labels = train_labels.copy()
# Initiate kNN, train the data, then test it with test data for k=1
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE,train_labels)
ret,result,neighbours,dist = knn.findNearest(test,k=5)
# Now we check the accuracy of classification
# For that, compare the result with test_labels and check which are wrong
matches = result == test_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print(accuracy)
#将结果打包
np.savez_compressed ('knn_data.npz',train=train, train_labels=train_labels)
# 读取已经打包的结果
with np.load('knn_data.npz') as data:
print(data.files)
train = data['train']
train_labels = data['train_labels']
最终得到的结果为
6、带自己训练集的kNN 手写数字 OCR(e3.py)
需要注意的是,运行这个例子,需要有两个摄像头,否则就需要修改
cap = cv2.VideoCapture(1)
为
cap = cv2.VideoCapture(0)
全部代码
import cv2
import numpy as np
# 这是总共5000个数据,0-9各500个,我们读入图片后整理数据,这样得到的train和trainLabel依次对应,图像数据和标签
def initKnn():
knn = cv2.ml.KNearest_create()
img = cv2.imread('E:/template/digits.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
train = np.array(cells).reshape(-1,400).astype(np.float32)
trainLabel = np.repeat(np.arange(10),500)
return knn, train, trainLabel
# updateKnn是增加自己的训练数据后更新Knn的操作。
def updateKnn(knn, train, trainLabel, newData=None, newDataLabel=None):
if newData != None and newDataLabel != None:
print(train.shape, newData.shape)
newData = newData.reshape(-1,400).astype(np.float32)
train = np.vstack((train,newData))
trainLabel = np.hstack((trainLabel,newDataLabel))
knn.train(train,cv2.ml.ROW_SAMPLE,trainLabel)
return knn, train, trainLabel
# findRoi函数是找到每个数字的位置,用包裹其最小矩形的左上顶点的坐标和该矩形长宽表示(x, y, w, h)。
# 这里还用到了Sobel算子。edges是原始图像形态变换之后的灰度图,可以排除一些背景的影响,
# 比如本子边缘、纸面的格子、手、笔以及影子等等,用edges来获取数字图像效果比Sobel获取的边界效果要好。
def findRoi(frame, thresValue):
rois = []
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray2 = cv2.dilate(gray,None,iterations=2)
gray2 = cv2.erode(gray2,None,iterations=2)
edges = cv2.absdiff(gray,gray2)
x = cv2.Sobel(edges,cv2.CV_16S,1,0)
y = cv2.Sobel(edges,cv2.CV_16S,0,1)
absX = cv2.convertScaleAbs(x)
absY = cv2.convertScaleAbs(y)
dst = cv2.addWeighted(absX,0.5,absY,0.5,0)
ret, ddst = cv2.threshold(dst,thresValue,255,cv2.THRESH_BINARY)
im, contours, hierarchy = cv2.findContours(ddst,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
x, y, w, h = cv2.boundingRect(c)
if w > 10 and h > 20:
rois.append((x,y,w,h))
return rois, edges
# findDigit函数是用KNN来分类,并将结果返回。
# th是用来手动输入训练数据时显示的图片。20x20pixel的尺寸是OpenCV自带digits.png中图像尺寸,
# 因为我是在其基础上更新数据,所以沿用这个尺寸。
def findDigit(knn, roi, thresValue):
ret, th = cv2.threshold(roi, thresValue, 255, cv2.THRESH_BINARY)
th = cv2.resize(th,(20,20))
out = th.reshape(-1,400).astype(np.float32)
ret, result, neighbours, dist = knn.findNearest(out, k=5)
return int(result[0][0]), th
# concatenate函数是拼接数字图像并显示的,用来输入训练数据。
def concatenate(images):
n = len(images)
output = np.zeros(20*20*n).reshape(-1,20)
for i in range(n):
output[20*i:20*(i+1),:] = images[i]
return output
knn, train, trainLabel = initKnn()
knn, train, trainLabel = updateKnn(knn, train, trainLabel)
cap = cv2.VideoCapture(1)
#width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
#height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
width = 426*2
height = 480
videoFrame = cv2.VideoWriter('frame.avi',cv2.VideoWriter_fourcc('M','J','P','G'),25,(int(width),int(height)),True)
count = 0
# 这是主函数循环部分,按“x”键会暂停屏幕并显示获取的数字图像,
# 按“e”键会提示输入看到的数字,在终端输入数字用空格隔开,
# 按回车如果显示“update KNN, Done!”则完成一次更新。
while True:
ret, frame = cap.read()
frame = frame[:,:426]
rois, edges = findRoi(frame, 50)
digits = []
for r in rois:
x, y, w, h = r
digit, th = findDigit(knn, edges[y:y+h,x:x+w], 50)
digits.append(cv2.resize(th,(20,20)))
cv2.rectangle(frame, (x,y), (x+w,y+h), (153,153,0), 2)
cv2.putText(frame, str(digit), (x,y), cv2.FONT_HERSHEY_SIMPLEX, 1, (127,0,255), 2)
newEdges = cv2.cvtColor(edges, cv2.COLOR_GRAY2BGR)
newFrame = np.hstack((frame,newEdges))
cv2.imshow('frame', newFrame)
videoFrame.write(newFrame)
key = cv2.waitKey(1) & 0xff
if key == ord(' '):
break
elif key == ord('x'):
Nd = len(digits)
output = concatenate(digits)
showDigits = cv2.resize(output,(60,60*Nd))
cv2.imshow('digits', showDigits)
cv2.imwrite(str(count)+'.png', showDigits)
count += 1
if cv2.waitKey(0) & 0xff == ord('e'):
pass
print('input the digits(separate by space):')
numbers = input().split(' ')
Nn = len(numbers)
if Nd != Nn:
print('update KNN fail!')
continue
try:
for i in range(Nn):
numbers[i] = int(numbers[i])
except:
continue
knn, train, trainLabel = updateKnn(knn, train, trainLabel, output, numbers)
print('update KNN, Done!')
print('Numbers of trained images:',len(train))
print('Numbers of trained image labels', len(trainLabel))
cap.release()
cv2.destroyAllWindows()
7、实现英文字母识别(e4.py)
/samples/cpp/letter-recognition.data是OpenCV中已经训练好的数据集

# -*- coding: utf-8 -*-
"""
Created on Tue Jan 28 20:21:32 2014
@author: duan
"""
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 读取英文字母数据
data= np.loadtxt('e:/template/letter-recognition.data', dtype= 'float32', delimiter = ',',
converters= {0: lambda ch: ord(ch)-ord('A')})
# 将数据分为train和test两份,每份各1000个
train, test = np.vsplit(data,2)
# 将训练数据切割 features and responses
responses, trainData = np.hsplit(train,[1])
labels, testData = np.hsplit(test,[1])
# knn建模并且训练
knn = cv2.ml.KNearest_create()
knn.train(traindata,cv2.ml.row_sample,responses)
#在测试数据上进行测试
ret, result, neighbours, dist = knn.findNearest(testData, k=5)
correct = np.count_nonzero(result == labels)
accuracy = correct*100.0/10000
print(accuracy)
结果
93.06
8、实现最终的猫狗识别(catVSdog_knn.py)
#在精简dogvscat的精简数据集上运行knn
import numpy as np
import cv2
import os
import math
from matplotlib import pyplot as plt
#全局变量
RATIO = 0.2
train_dir = 'e:/template/dogvscat1K/'
#根据Ratio获得训练和测试数据集的图片地址和标签
def get_files(file_dir, ratio):
'''
Args:
file_dir: file directory
Returns:
list of images and labels
'''
cats = []
label_cats = []
dogs = []
label_dogs = []
for file in os.listdir(file_dir):
name = file.split(sep='.')
if name[0]=='cat':
cats.append(file_dir + file)
label_cats.append(0)
else:
dogs.append(file_dir + file)
label_dogs.append(1)
print('数据集中有 %d cats
以及 %d dogs' %(len(cats), len(dogs)))
#图片list和标签list
#hstack 水平(按列顺序)把数组给堆叠起来
image_list = np.hstack((cats, dogs))
label_list = np.hstack((label_cats, label_dogs))
temp = np.array([image_list, label_list])
temp = temp.transpose()
np.random.shuffle(temp)
all_image_list = temp[:, 0]
all_label_list = temp[:, 1]
n_sample = len(all_label_list)
#根据比率,确定训练和测试数量
n_val = math.ceil(n_sample*ratio) # number of validation samples
n_train = n_sample - n_val # number of trainning samples
tra_images = []
val_images = []
#按照0-n_train为tra_images,后面位val_images的方式来排序
for index in range(n_train):
image = cv2.imread(all_image_list[index])
#灰度,然后缩放
image = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
image = cv2.resize(image,(32,32))
tra_images.append(image)
tra_labels = all_label_list[:n_train]
tra_labels = [int(float(i)) for i in tra_labels]
for index in range(n_val):
image = cv2.imread(all_image_list[n_train+index])
#灰度,然后缩放
image = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
image = cv2.resize(image,(32,32))
val_images.append(image)
val_labels = all_label_list[n_train:]
val_labels = [int(float(i)) for i in val_labels]
return tra_images,tra_labels,val_images,val_labels
#获得数据集
_train, train_labels, _val, val_labels = get_files(train_dir, RATIO)
x = np.array(_train)
train = x.reshape(-1,32*32).astype(np.float32) # Size = (1000,900)
y = np.array(_val)
test = y.reshape(-1,32*32).astype(np.float32)
# Initiate kNN, train the data, then test it with test data for k=1
knn = cv2.ml.KNearest_create()
knn.train(np.array(train), cv2.ml.ROW_SAMPLE,np.array(train_labels))
ret,result,neighbours,dist = knn.findNearest(test,k=5)
# Now we check the accuracy of classification
# For that, compare the result with test_labels and check which are wrong
np_val_labels = np.array(val_labels)[:,np.newaxis]
matches = result == np_val_labels
correct = np.count_nonzero(matches)
accuracy = correct*100.0/result.size
print(accuracy)
结果,在1000狗1000猫的数据集上,是55.55的准确率,而在全部的数据集上,是56.2的准确率。证明两点
knn是有一定用途的;但是在不对特征进行详细分析的基础上,其准确率很难得到较大提高。
Knn的例子到此告以段落。