随着学习的进行,深度学习的学习速率逐步下降 为什么比 固定的学习速率 得到的结果更加准确?
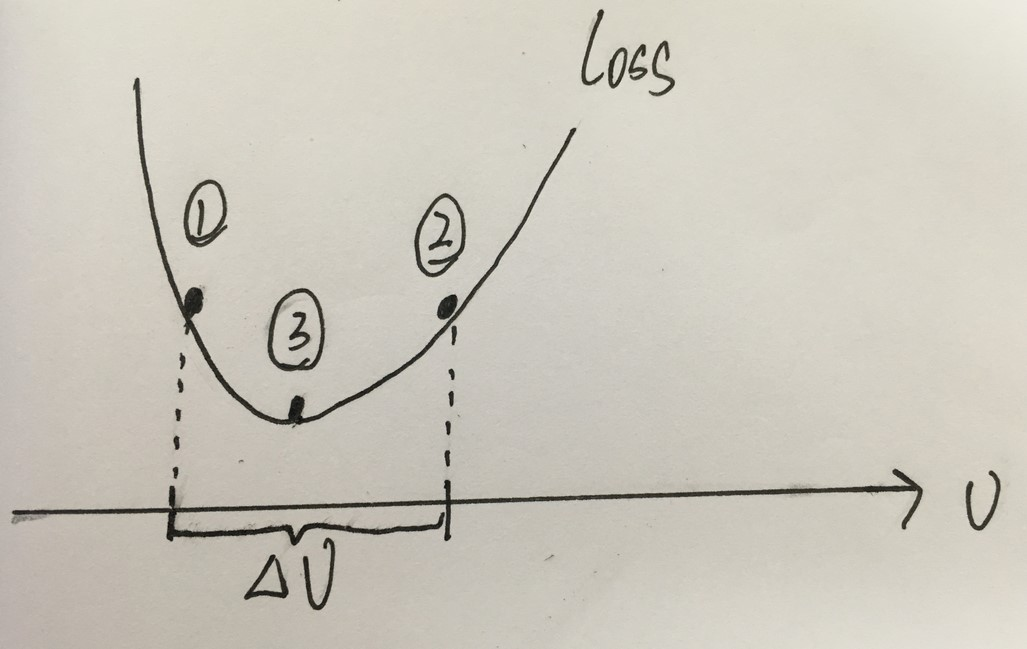
如上图所示,曲线代表损失值,小球一开始位于(1)处,假设学习速率设置为 △ v,那么根据梯度下降,损失值将在(1) (2)之间来回移动,无法到达最小值(3)处。要想到达(3),只能降低学习速率。
keras中实现方法:
learning_rate_reduction
= ReduceLROnPlateau(monitor
=
'val_acc', patience
=
3, verbose
=
1, factor
=
0.
5, min_lr
=
0.
00001)
#并且作为callbacks进入generator,开始训练
history
= model.fit_generator(datagen.flow(X_train,Y_train, batch_size
=batch_size),
epochs
= epochs, validation_data
= (X_val,Y_val),
verbose
=
2, steps_per_epoch
=X_train.shape[
0]
// batch_size
, callbacks
=[learning_rate_reduction])
文档:
ReduceLROnPlateau
keras.callbacks.ReduceLROnPlateau(monitor
=
'val_loss', factor
=
0.
1, patience
=
10, verbose
=
0, mode
=
'auto', epsilon
=
0.
0001, cooldown
=
0, min_lr
=
0)
当评价指标不在提升时,减少学习率。当学习停滞时,减少2倍或10倍的学习率常常能获得较好的效果。该回调函数检测指标的情况,如果在patience个epoch中看不到模型性能提升,则减少学习率
参数
- monitor:被监测的量
- factor:每次减少学习率的因子,学习率将以
lr = lr*factor的形式被减少 - patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
- mode:‘auto’,‘min’,‘max’之一,在
min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少。 - epsilon:阈值,用来确定是否进入检测值的“平原区”
- cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
- min_lr:学习率的下线