

这里的想法来源于OpenVINO的一个介绍材料,具体来说就是如上图一样,能够实现人像前景的图片的背景分割,灰度化背景后重新放置回去。
这个操作实际上包含了人像分割、背景处理、图像融合等关键技术
从实现来说,主要分为两个部分,一个是“前景背景分割”,二个是“背景灰度化”。第2个部分肯定是OpenCV来做,第一个部分我尝试过使用基于EasyDL的实现(https://www.cnblogs.com/jsxyhelu/p/15509647.html),本课程分享一种基于u2net实现的方法,整个代码基于VS编译,能够离线在windows上运行,对于部署来说也是非常友好的。无论对于学习相关原理,还是部署方法,都是比较有价值的。
在本课程内容包括:
- 基于u2net的人像分割方法;
- 融合效果极好的 SeamlessClone 技术;
- 饱和度调整、颜色域等基础图像处理知识和编码技术 ;
- 最为关键的是如何结合OpenCV和libtorch,融合pytorch模型和传统图像处理算法,解决具体现实问题。
一、基础知识
1、U2net
U2net是基于unet提出的一种新的网络结构,同样基于encode-decode,作者参考FPN,Unet,在此基础之上提出了一种新模块RSU(ReSidual U-blocks) 经过测试,对于分割物体前背景取得了惊人的效果。同样具有较好的实时性,经过测试在P100上前向时间仅为18ms(56fps)。
论文:https://arxiv.org/pdf/2005.09007.pdf
2、libtorch
一般地,当我们在python框架(eg:pytorch,tensorflow等)中训练好模型,需要部署到C/C++环境,有以下方案:
CPU方案:Libtorch、OpenCV-DNN、OpenVINO、ONNX(有个runtime可以调)
GPU方案:TensorRT、OpenCV-DNN(需要重新编译,带上CUDA)其中,libtorch基本上可以理解是pytorch的c++版本,使用libtorch是调用深度学习模型的一种有效方法。
二、环境配置
1、Ubuntu环境
要在n多服务器端部署python的应用,虽然python本身是跨平台的,当时好多第三方的扩展却不一定都能做到各个版本兼容,即便是都是linux,在redhat系列和ubuntu系列之间来回导也是个很让人头痛的事.
找到这个virtualenv,整个的clone一个python环境,可以在这个虚出来的环境里面配置一番,然后整个打包发布,这样在其他linux版本上部署时就会非常简单,实在是部署python服务器端应用的必备!
使用pip安装virtualenv:
pip install virtualenv
# 新建虚拟环境
virtualenv .venv
ls
-al #查看
source .venv
/bin/activate #激活(deactivate 注销)cd .venv/
剩下的就是在这个虚拟python环境中安装配置你的服务应用,
装完后修改一下bin/activate脚本,让它自动把环境设置好,服务启动起来,有一个地方要修改:
找到设置VIRTUAL_ENV的地方,改成如下:
export VIRTUAL_ENV=`pwd`
如果你不熟悉shell,那么要注意pwd两边的不是单引号'而是`
然后就可以打包带走了,到另一台server上,只要简单的解包,然后执行
. bin/activate
就一切ok了
2、vs2017 配置libtorch 1.7
下载pytorch c++ 版本,https://pytorch.org/
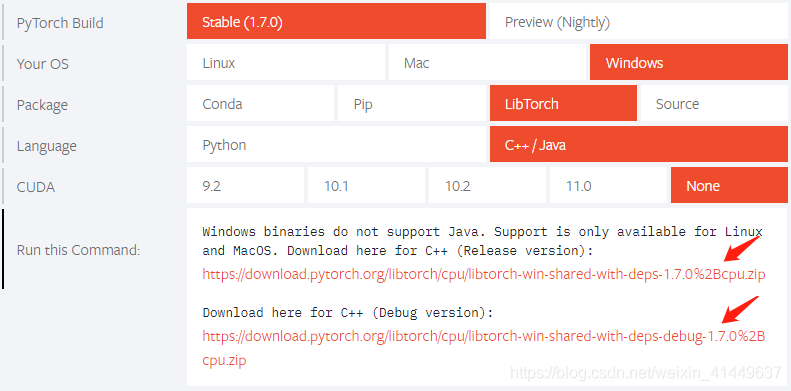
vs选择2017,编译器选择c++14

下载好的libtorch解压

设置包含目录
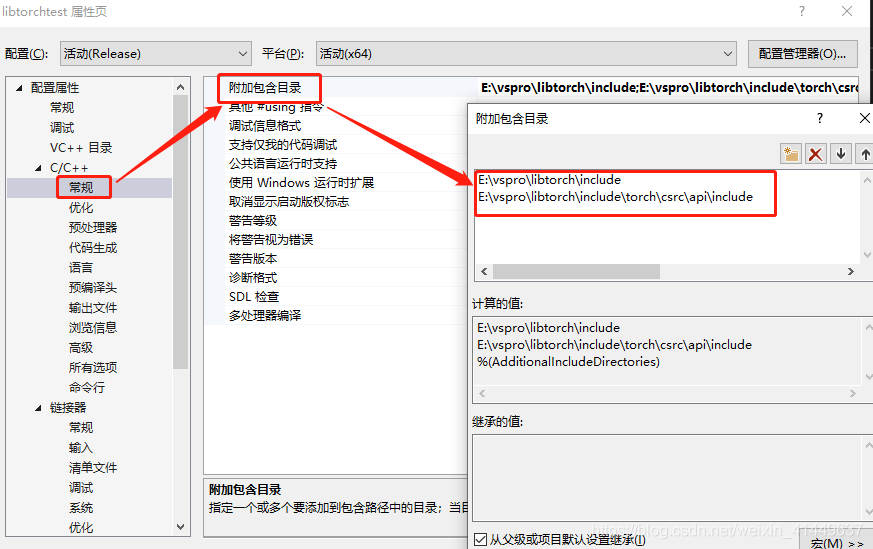
设置lib目录
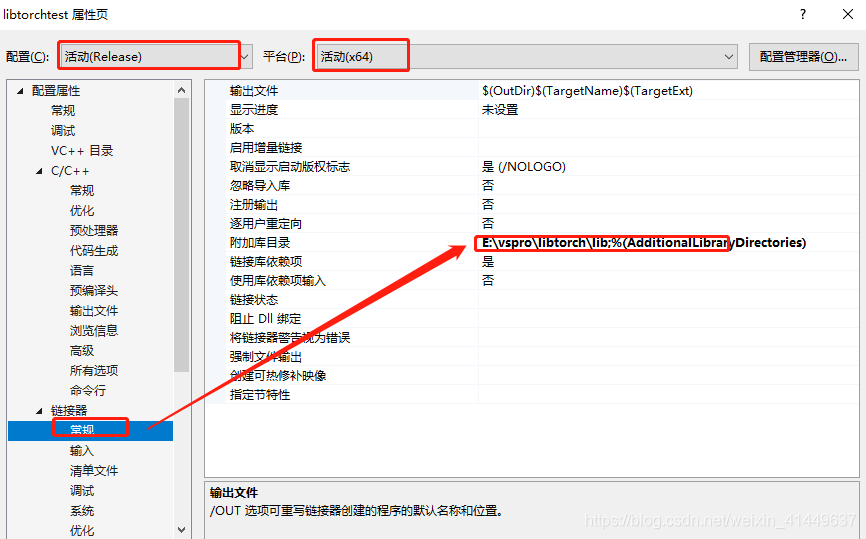
添加lib
asmjit.libc10.libcaffe2_detectron_ops.libcaffe2_module_test_dynamic.libCaffe2_perfkernels_avx.libCaffe2_perfkernels_avx2.libCaffe2_perfkernels_avx512.libclog.libcpuinfo.libdnnl.libfbgemm.libfbjni.libkineto.liblibprotobuf-lite.liblibprotobuf.liblibprotoc.libmkldnn.libpthreadpool.libpytorch_jni.libtorch.libtorch_cpu.libXNNPACK.lib还有两个地方需要修改:
第一项:属性->C/C++ ->常规->SDL检查->否。
第二项:属性->C/C++ ->语言->符号模式->否。
测试代码
#include <iostream>
#include <torch/torch.h>
int main()
{
torch::Tensor tensor = torch::rand({ 5,3 });
std::cout << tensor << std::endl;
return EXIT_SUCCESS;
}测试完成,配置成功

三、libtorch对u2net调用,获得模板
在配置好libtorch的基础上(参考第四部分),首先对下载模型进行相关处理(我比较倾向于使用ubuntu环境进行模型转换,ubuntu的环境配置参考README文件)
import os
import torch
from model import U2NET # full size version 173.6 MB
def main():
model_name = 'u2net'
model_dir = os.path.join(os.getcwd(), 'saved_models', model_name , model_name + '.pth')
print("................................................")
print(model_dir)
print("................................................")
if model_name == 'u2net':
print("...load U2NET---173.6 MB")
net = U2NET(3, 1)
net.load_state_dict(torch.load(model_dir, map_location=torch.device('cpu')))
net.eval()
# --------- model 序列化 ---------
#example = torch.zeros(1, 3, 512, 512).to(device='cuda')
example = torch.zeros(1, 3, 512, 512)
torch_script_module = torch.jit.trace(net, example)
torch_script_module.save('human2-cpu.pt')
print('over')
if __name__ == "__main__":
main()获得human2-cpu.pt模型,可以拷贝到vs下面,编写接口文件。这里接口文件的编写,一定是和u2net的网络本身关系紧密的。
torch::Tensor normPRED(torch::Tensor d)
{
at::Tensor ma, mi;
torch::Tensor dn;
ma = torch::max(d);
mi = torch::min(d);
dn = (d - mi) / (ma - mi);
return dn;
}
void bgr_u2net(cv::Mat& image_src, cv::Mat& result, torch::jit::Module& model){ //1.模型已经导入 auto device = torch::Device("cpu"); //2.输入图片,变换到320 cv::Mat image_src1 = image_src.clone(); cv::resize(image_src, image_src, cv::Size(320, 320)); cv::cvtColor(image_src, image_src, cv::COLOR_BGR2RGB); // 3.图像转换为Tensor torch::Tensor tensor_image_src = torch::from_blob(image_src.data, { image_src.rows, image_src.cols, 3 }, torch::kByte); torch::Tensor tensor_bgr = torch::from_blob(image_src1.data, { image_src1.rows, image_src1.cols,3 }, torch::kByte); tensor_image_src = tensor_image_src.permute({ 2,0,1 }); // RGB -> BGR互换 tensor_image_src = tensor_image_src.toType(torch::kFloat); tensor_image_src = tensor_image_src.div(255); tensor_image_src = tensor_image_src.unsqueeze(0); // 拿掉第一个维度 [3, 320, 320] std::cout << tensor_image_src.sizes() << std::endl; // [1, 3, 320, 320] //同样方法处理 tensor_bgr = tensor_bgr.permute({ 2,0,1 }); tensor_bgr = tensor_bgr.toType(torch::kFloat); tensor_bgr = tensor_bgr.div(255); tensor_bgr = tensor_bgr.unsqueeze(0); //4.网络前向计算 auto src = tensor_image_src.to(device); auto outputs = model.forward({ src }).toTuple()->elements(); auto pred = outputs[0].toTensor(); auto res_tensor = (pred * torch::ones_like(src)); std::cout << torch::ones_like(src).sizes() << std::endl; std::cout << src.sizes() << std::endl; res_tensor = normPRED(res_tensor); res_tensor = res_tensor.squeeze(0).detach(); res_tensor = res_tensor.mul(255).clamp(0, 255).to(torch::kU8); //mul函数,表示张量中每个元素乘与一个数,clamp表示夹紧,限制在一个范围内输出 res_tensor = res_tensor.to(torch::kCPU); //5.输出最终结果 cv::Mat resultImg(res_tensor.size(1), res_tensor.size(2), CV_8UC3); std::memcpy((void*)resultImg.data, res_tensor.data_ptr(), sizeof(torch::kU8) * res_tensor.numel()); cv::resize(resultImg, resultImg, cv::Size(image_src1.cols, image_src1.rows), cv::INTER_LINEAR); result = resultImg.clone();}完善main的其它部分,实现图片的前景模板获得。
int main(){ cv::Mat srcImg = cv::imread("e:/template/people2.jpg"); cv::Mat srcImg_; cv::resize(srcImg, srcImg_, cv::Size(512, 512)); if (srcImg_.channels() == 4) cv::cvtColor(srcImg_, srcImg_, cv::COLOR_BGRA2BGR); std::string strModelPath = "e:/template/human2-cpu.pt"; // load model of cpu torch::jit::script::Module styleModule; // load style model auto device_type = at::kCPU; if (torch::cuda::is_available()) { std::cout << "gpu" << std::endl; device_type = at::kCUDA; } try { styleModule = torch::jit::load(strModelPath); styleModule.to(device_type); } catch (const c10::Error& e) { std::cerr << "errir code: -2, error loading the model\n"; return -1; } cv::Mat dstImg; bgr_u2net(srcImg_, dstImg, styleModule); cv::imshow("dstImg", dstImg); cv::waitKey(0); return 1;}
这个就是所谓“细如发丝”的效果。
四、完成背景替换
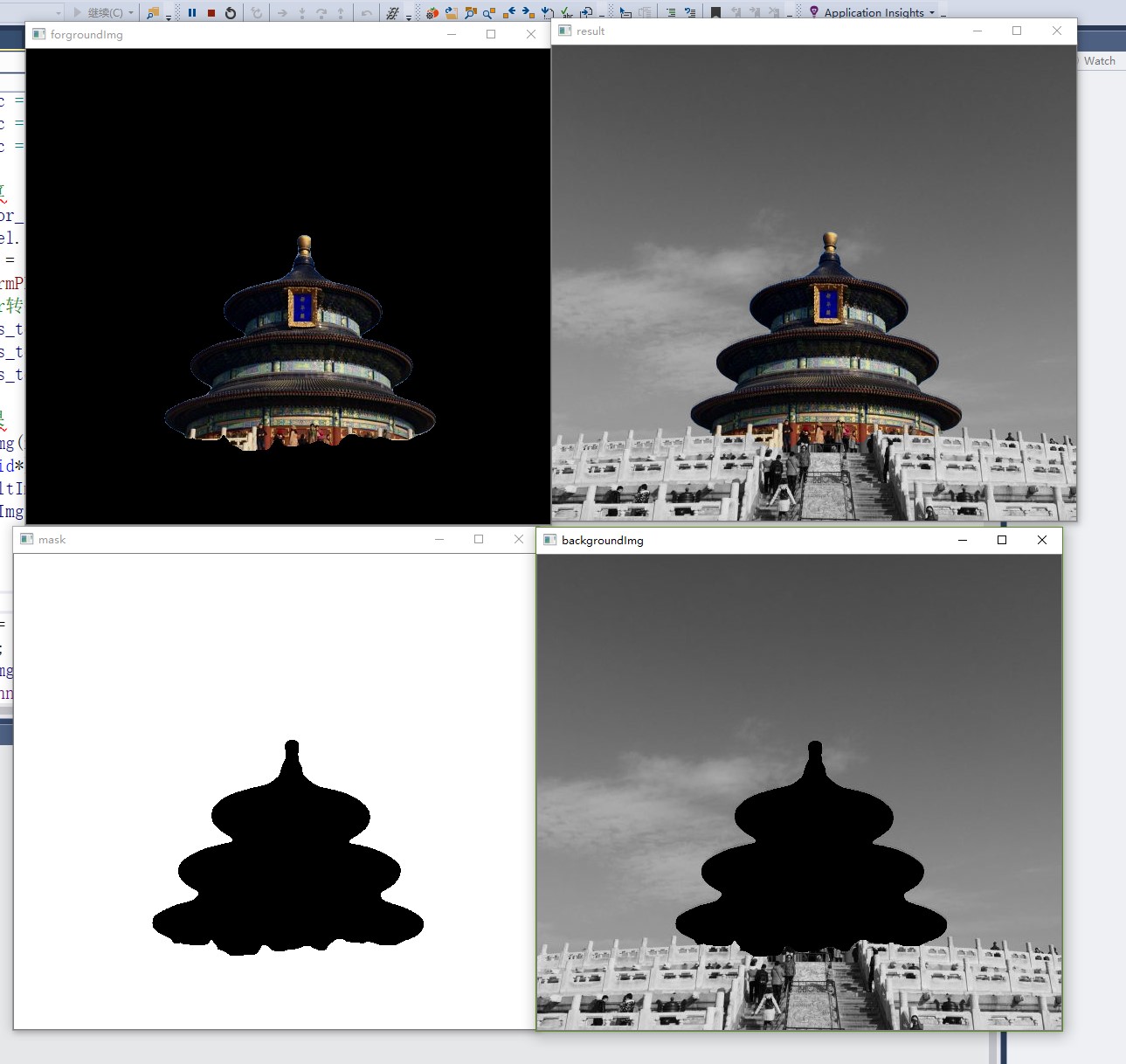
根据目前的情况作“相减、灰度、相加”操作,直接在main函数中进行相关修改。
//大小统一,获得模板
cv::resize(dstImg, dstImg, srcImg.size());
cv::Mat backgroundImg, forgroundImg,result, mask;
cv::cvtColor(dstImg, mask, cv::COLOR_BGR2GRAY);
cv::threshold(mask, mask,100,255, cv::THRESH_BINARY);
//前背景分离
srcImg.copyTo(forgroundImg, mask);
cv::bitwise_not(mask, mask);
srcImg.copyTo(backgroundImg, mask);
//处理后合并
cv::cvtColor(backgroundImg, backgroundImg, cv::COLOR_BGR2GRAY);
cv::cvtColor(backgroundImg, backgroundImg, cv::COLOR_GRAY2BGR);
result = backgroundImg + forgroundImg;
cv::imshow("mask", mask);
cv::imshow("forgroundImg", forgroundImg);
cv::imshow("backgroundImg", backgroundImg);
cv::imshow("result", result);

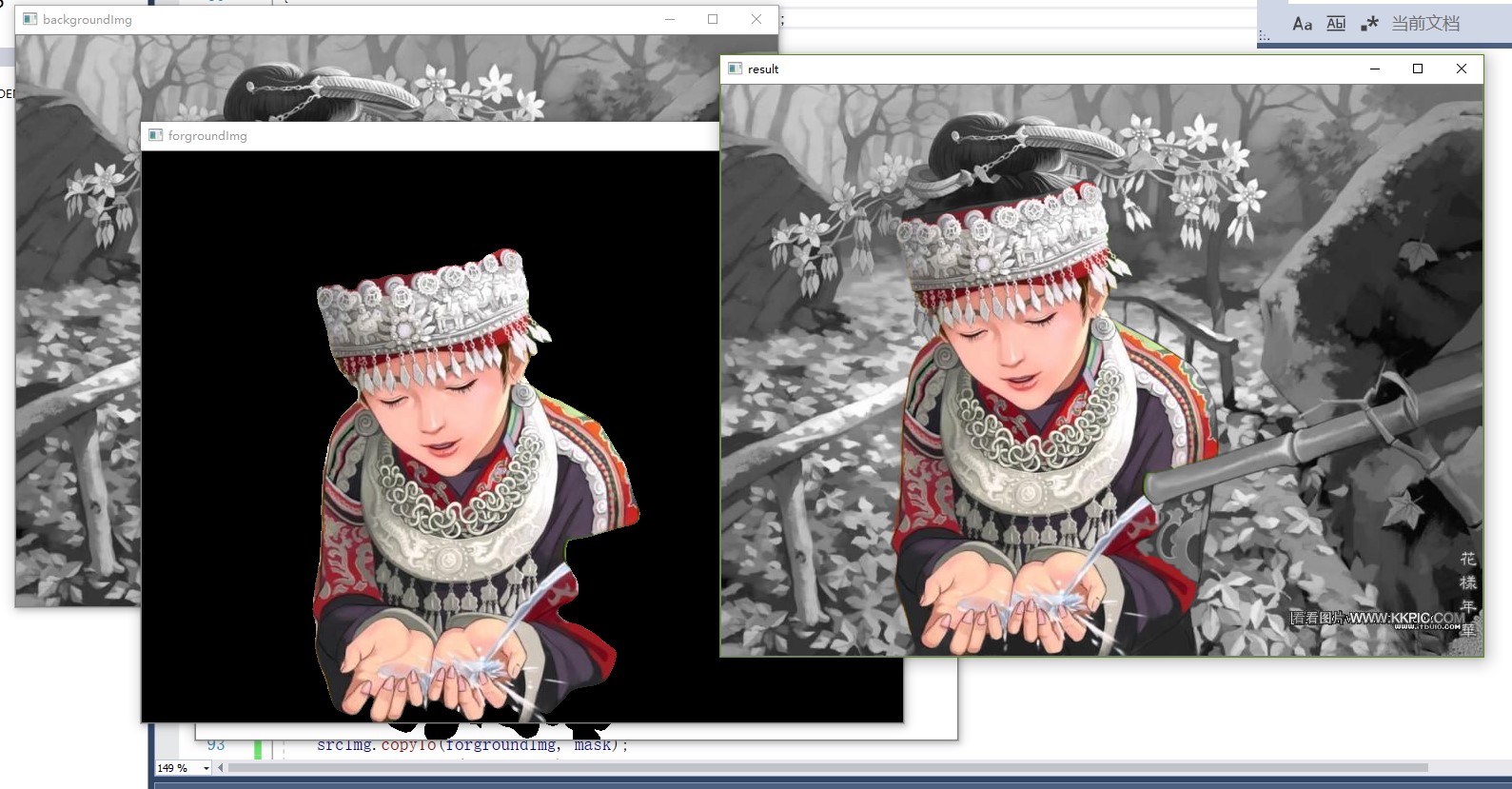
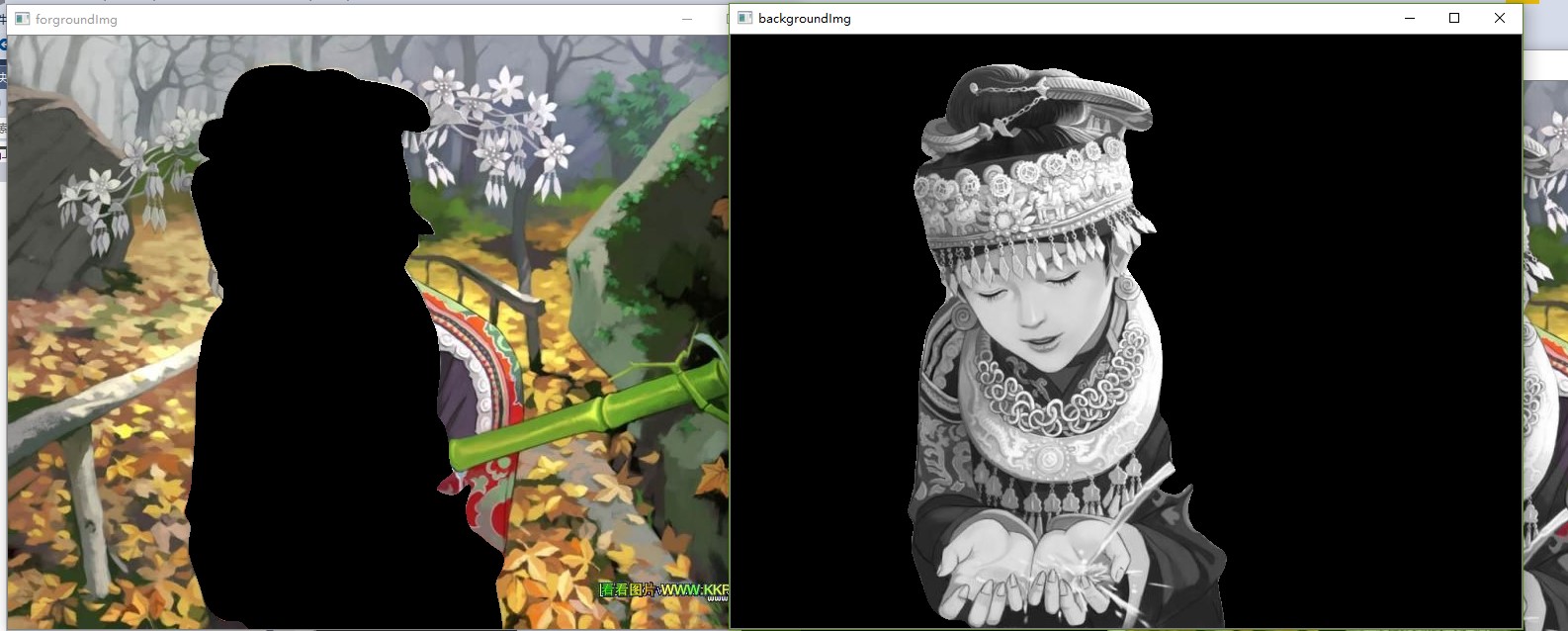
(换了一个模型,模型无法在线更新变换,也是AI自己存在的问题)


五、参考资料和继续研究
1、《vs2017 配置libtorch 1.7》 https://blog.csdn.net/weixin_41449637/article/details/109812646
2、如果u2net_converto_onnx实现转换为onnx,能否使用OpenCV直接调用;
3、如果可以自己训练u2net的数据集,那么就可以用来替换其他东西;
4、如果u2net的结果可以作为lama的输入,那么久可以实现inpaint。