
极光高级工程师——蔡祖光
前言
Spark在2018开始在极光大数据平台部署使用,历经多个版本的迭代,逐步成为离线计算的核心引擎。当前在极光大数据平台每天运行的Spark任务有20000+,执行的Spark SQL平均每天42000条,本文主要介绍极光数据平台在使用Spark SQL的过程中总结的部分实践经验,包括以下方面内容:
Spark Extension的应用实践
Spark Bucket Table的改造优化
从Hive迁移到Spark SQL的实践方案
一、Spark Extension应用实践
Spark Extension作为Spark Catalyst扩展点在SPARK-18127中被引入,Spark用户可以在SQL处理的各个阶段扩展自定义实现,非常强大高效
1.1 血缘关系解析
在极光我们有自建的元数据管理平台,相关元数据由各数据组件进行信息收集,其中对Spark SQL的血缘关系解析和收集就是通过自定义的Spark Extension实现的。
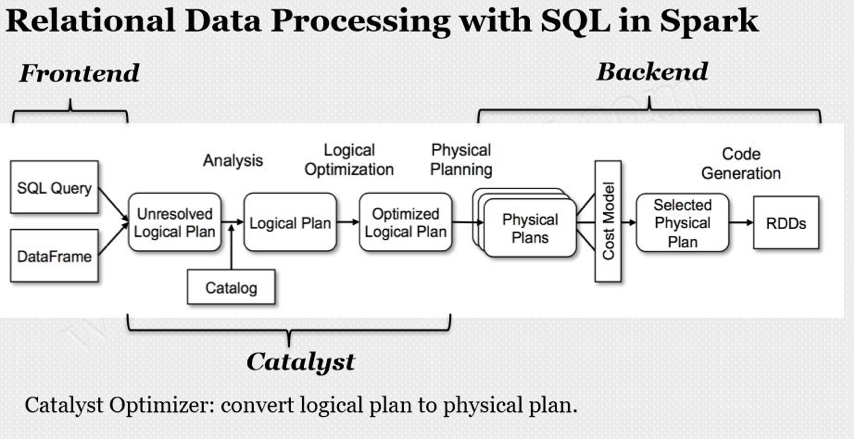
Spark Catalyst的SQL处理分成parser,analyzer,optimizer以及planner等多个步骤,其中analyzer,optimizer等步骤内部也分为多个阶段,为了获取最有效的血缘关系信息,我们选择最终的planner阶段作为切入点,为此我们专门实现了一个planner strategy进行Spark SQL物理执行计划的解析,并提取出读写表等元数据信息并存储到元数据管理平台
1.2 权限校验
在数据安全方面,极光选择用Ranger作为权限管理等组件,但在实际使用的过程中我们发现目前社区版本的Ranger主要提供的还是HDFS、HBase、Hive、Yarn的相关接入插件,在Spark方面需要自己去实现相关功能,对于以上问题我们同样选择用Spark Extension去帮助我们进行权限方面的二次开发,在实现的过程中我们借助了Ranger Hive-Plugin的实现原理,对Spark SQL访问Hive进行了权限校验功能的实现。
1.3 参数控制
随着数据平台使用Spark SQL的业务同学越来越多,我们发现每个业务同学对于Spark的熟悉程度都有所不同,对Spark配置参数的理解也有好有坏,为了保障集群整体运行的稳定性,我们对业务同学提交的Spark任务的进行了拦截处理,提取任务设置的配置参数,对其中配置不合理的参数进行屏蔽,并给出风险提示,有效的引导业务同学进行合理的线上操作。
二、Spark Bucket Table的改造优化
在Spark的实践过程中,我们也积极关注业内其它公司优秀方案,在2020年我们参考字节跳动对于Spark Bucket Table的优化思路,在此基础上我们对极光使用的Spark进行了二次改造,完成如下优化项:
Spark Bucket Table和Hive Bucket Table的互相兼容
Spark支持Bucket Num是整数倍的Bucket Join
Spark支持Join字段和Bucket字段是包含关系的Bucket Join
上述三点的优化,丰富了Bucket Join的使用场景,可以让更多Join、Aggregate操作避免产生Shuffle,有效的提高了Spark SQL的运行效率.在完成相关优化以后,如何更好的进行业务改造推广,成为了我们关心的问题。
通过对数据平台过往SQL执行记录的分析,我们发现用户ID和设备ID的关联查询是十分高频的一项操作,在此基础上,我们通过之前SQL血缘关系解析收集到的元数据信息,对每张表进行Join、Aggregate操作的高频字段进行了分析整理,统计出最为合适的Bucket Cloumn,并在这些元数据的支撑下辅助我们进行Bucket Table的推广改造。
三、Hive迁移Spark
随着公司业务的高速发展,在数据平台上提交的SQL任务持续不断增长,对任务的执行时间和计算资源的消耗都提出了新的挑战,出于上述原因,我们提出了Hive任务迁移到Spark SQL的工作目标,由此我们总结出了如下问题需求:
如何更好的定位哪些Hive任务可以迁移,哪些不可以
如何让业务部门无感知的从Hive迁移到Spark SQL
如何进行对比分析,确认任务迁移前后的运行效果
3.1 Hive迁移分析程序的实现
在迁移业务job时,我们需要知道这个部门有哪些人,由于Azkaban在执行具体job时会有执行人信息,所以我们可以根据执行人来推测有哪些job。分析程序使用了元数据系统的某些表数据和azkaban相关的一些库表信息,用来帮助我们收集迁移的部门下有多少hive job,以及该hive job有多少sql,sql语法通过率是多少,当然在迁移时还需要查看Azkaban的具体执行耗时等信息,用于帮助我们在精细化调参的时候大致判断消耗的资源是多少。
由于线上直接检测某条sql是否合乎spark语义需要具有相关的读写权限,直接开放权限给分析程序不安全。所以实现的思路是通过使用元数据系统存储的库表结构信息,以及azkaban上有采集业务job执行的sql信息。只要拥有某条sql所需要的全部库表信息,我们就能在本地通过重建库表结构分析该条sql是否合乎spark语义(当然线上环境和本地是有不同的,比如函数问题,但大多情况下是没有问题的)。
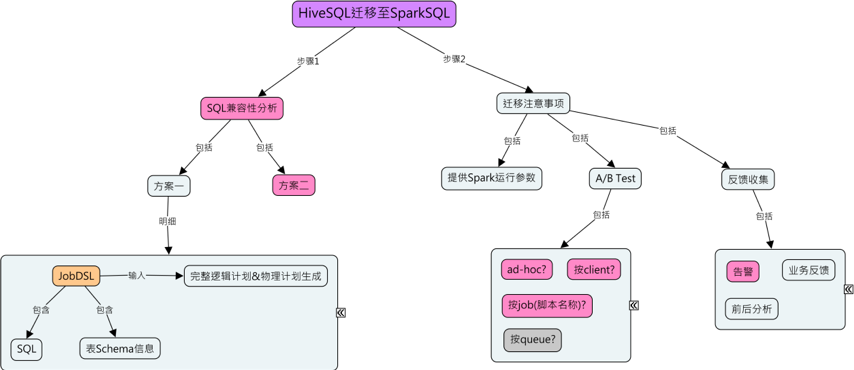
图3-1-1
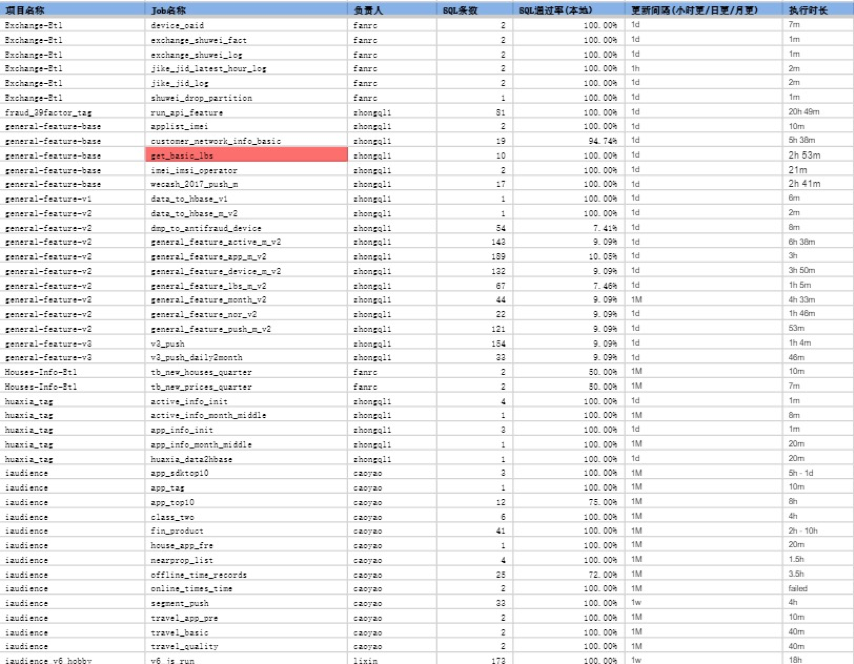
以下为某数据部通过分析程序得到的SQL通过率
3.2 SQL执行引擎的无感知切换
目前业务方使用Hive的主要方式是通过beeline去连接hiveserver2,由于livy也提供了thriftserver模块,所以beeline也可以直接连接livy。迁移的策略就是先把合乎Spark语法的SQL发往livy执行,如果执行失败再切换到Hive进行兜底执行。
beeline可获取用户SQL,启动beeline时通过thrift接口创建livy session,获取用户sql发送给livy 执行,期间执行进度等信息可以查询livy获得,同时一个job对应一个session,以及每启动一次 beeline对应一个session,当job执行完毕或者beeline被关闭时,关闭livy session。(如果spark不能成功执行则走之前hive的逻辑)
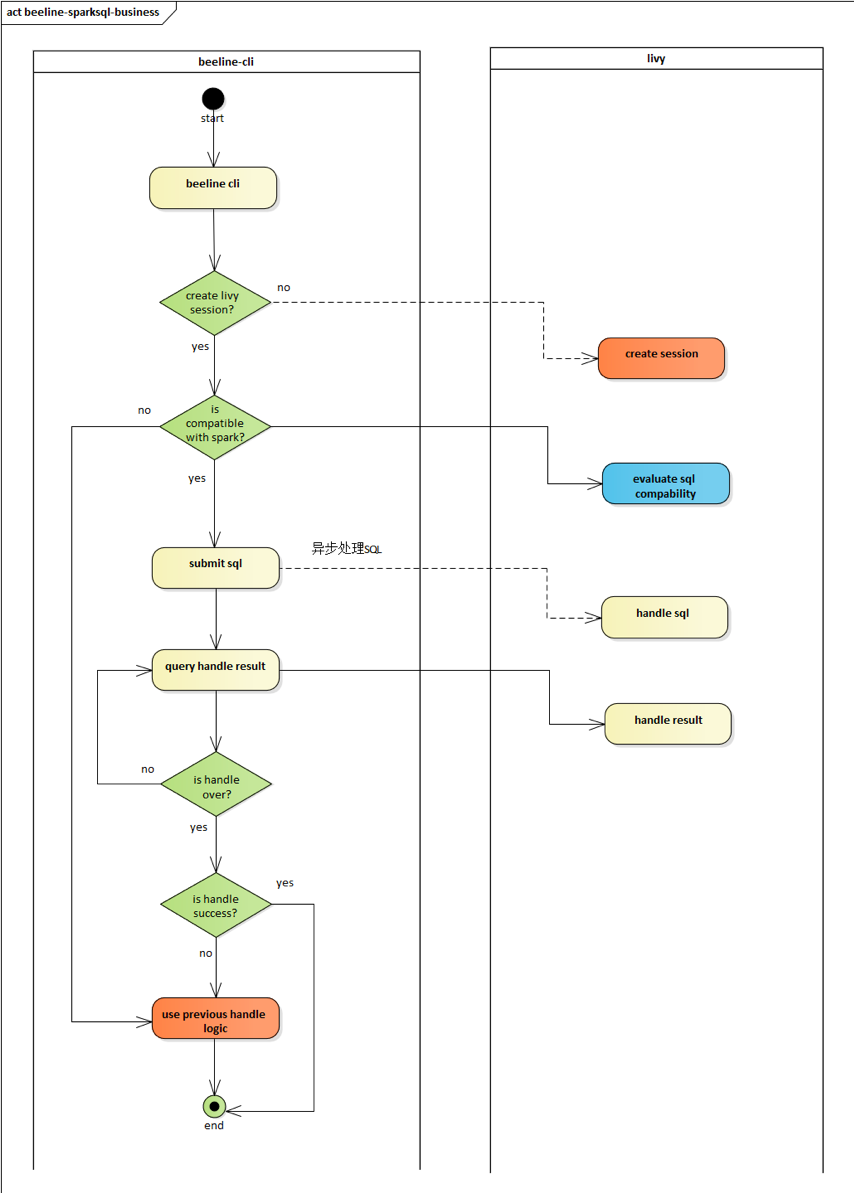
图3-2-1
有了以上切换思路以后,我们开始着手beeline程序的修改设计
beeline重要类图如图3-2-2所示, Beeline类是启动类,获取用户命令行输入并调用Commands类去 执行,Commands负责调用JDBC接口去执行和获取结果, 单向调用流程如图3-2-3所示。
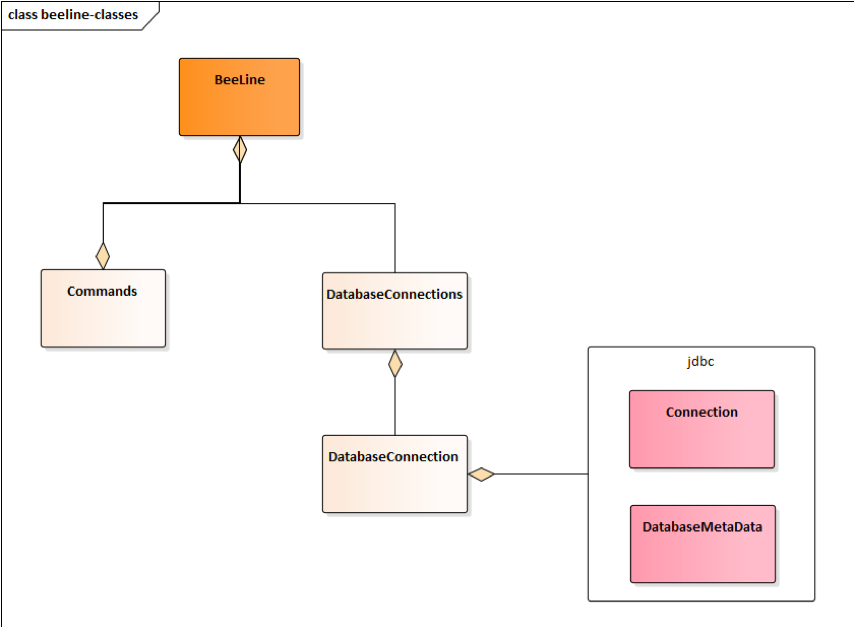
图3-2-2
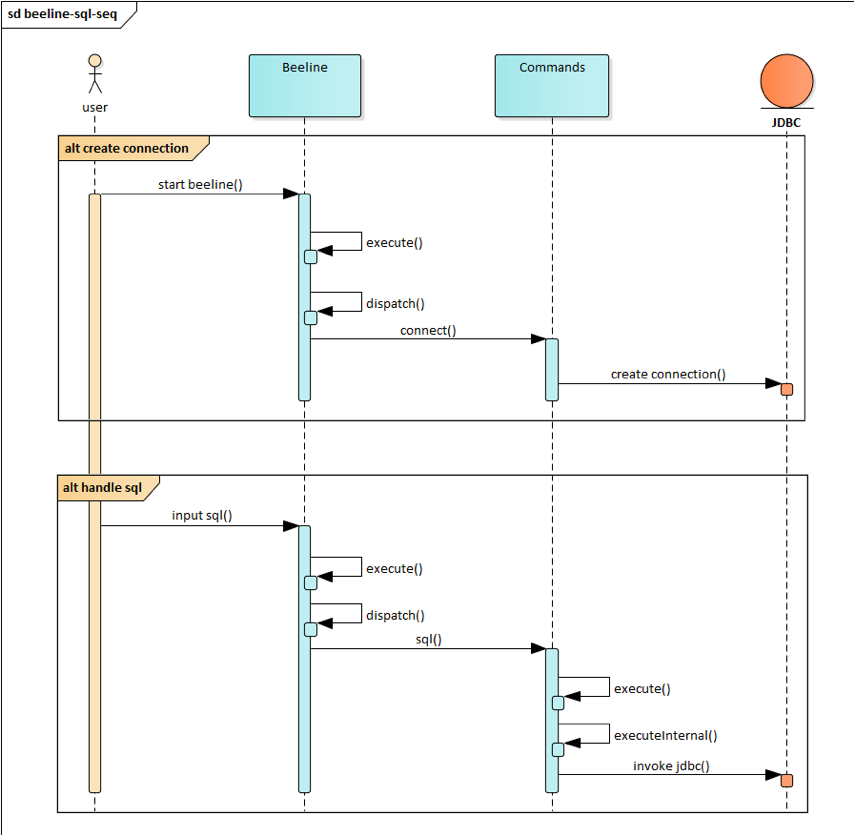
图3-2-3
由图3-2-2和图3-2-3可知,所有的操作都是通过DatabaseConnection这个对象去完成的,持有这个 对象的是DatabaseConnections这个对象,所以多计算引擎切换,通过策略适配
DatabaseConnections对象,这样就能在不修改其他代码的情况下切换执行引擎(即获取不同的 connection)

图3-2-4
3.3 任务迁移黑名单
前文有说到,当一个Hive任务用SQL分析程序走通,并且在迁移程序用livy进行Spark任务提交以后,还是会有可能执行失败,这个时候我们会用Hive进行兜底执行保障任务稳定性。但是失败的SQL会有多种原因,有的SQL确实用Hive执行稳定性更好,如果每次都先用Spark SQL执行失败以后再用Hive执行会影响任务效率,基于以上目的,我们对迁移程序开发了黑名单功能,用来保障每个SQL可以找到它真正适合的执行引擎,考虑到beeline是轻量级客户端,识别的功能应该放在livy-server侧来做,开发一个类似HBO的功能来将这样的异常SQL加入黑名单,节省迁移任务执行时间。
目标: 基于HBE(History-Based Executing)的异常SQL识别
有了上述目标以后我们主要通过如下方式进行了SQL黑名单的识别切换
SQL识别限定在相同appName中(缩小识别范围避免识别错误)
得到SQL抽象语法树的后续遍历内容后生成md5值作为该sql的唯一性标识
把执行失败超过N次的SQL信息写入黑名单
下次执行时根据赋值规则比较两条SQL的结构树特征
对于在黑名单中的SQL不进行Spark SQL切换
3.4 迁移成果
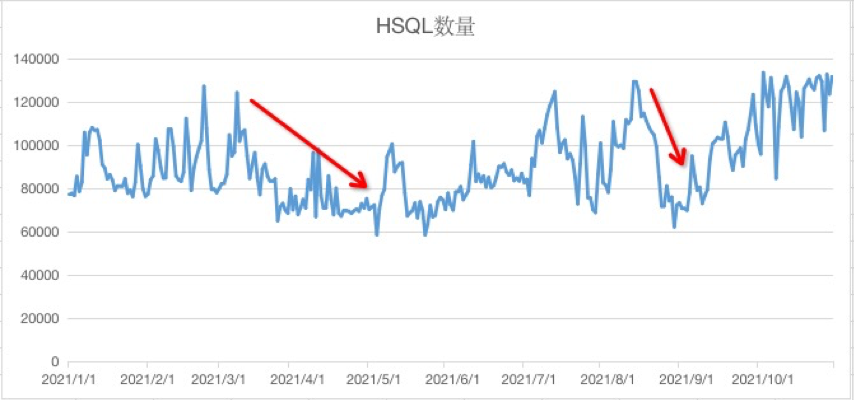
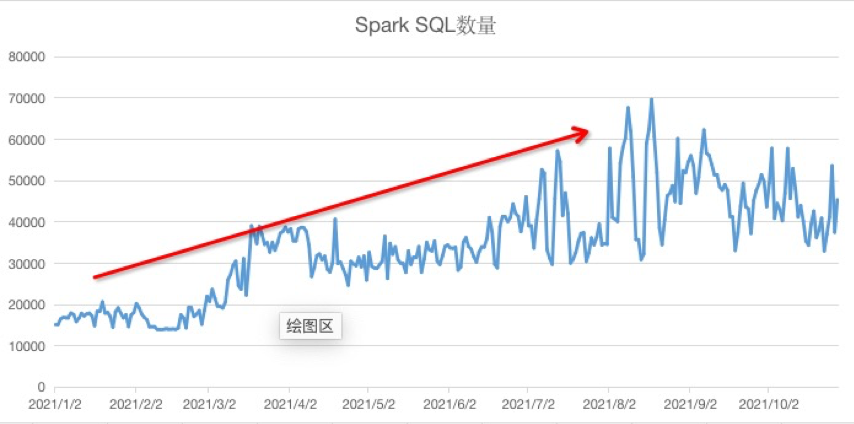
今年经过迁移程序的迁移改造,HSQL最大降幅为50%+(后随今年业务增长有所回升)
四、Spark3.0的应用
当前极光使用的Spark默认版本已经从2.X版本升级到了3.X版本,Spark3.X的AQE特性也辅助我们更好的使用Spark
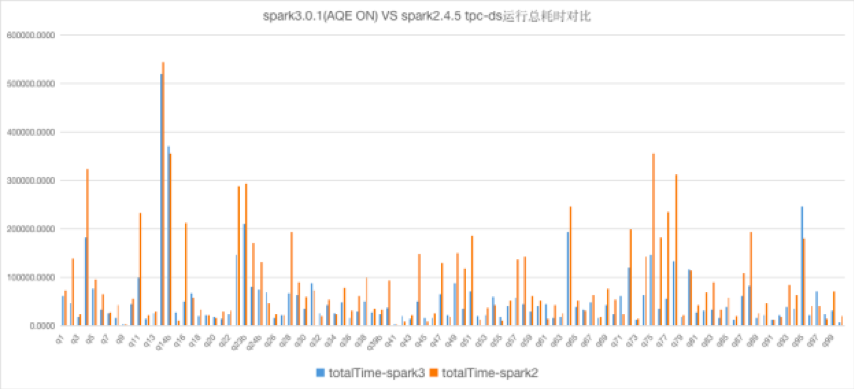
实践配置优化:
spark3.0.0参数
动态合并shuffle partitions
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.coalescePartitions.minPartitionNum 1
spark.sql.adaptive.coalescePartitions.initialPartitionNum 500
spark.sql.adaptive.advisoryPartitionSizeInBytes 128MB
动态优化数据倾斜,通过实际的数据特性考虑,skewedPartitionFactor我们设置成了1
spark.sql.adaptive.skewJoin.enabled true
spark.sql.adaptive.skewJoin.skewedPartitionFactor 1
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 512MB
五、后续规划
目前针对线上运行的Spark任务,我们正在开发一套Spark全链路监控平台,作为我们大数据运维平台的一部分,该平台会承担对线上Spark任务运行状态的采集监控工作,我们希望可以通过该平台及时定位发现资源使用浪费、写入大量小文件、存在slow task等问题的Spark任务,并以此进行有针对性的优化,让数据平台可以更高效的运行。