Pandas是一个强大的分析结构化数据的工具集,主要用于数据挖掘和数据分析,同时也提供数据清洗功能。
很多初学者在数据的选取,修改和切片时经常面临一些困惑。这是因为Pandas提供了太多方法可以做同样的事情,方法选择不当,可能导致一些意想不到的错误。
Pandas切片
Pandas数据访问方式包括:df[] ,.at,.iat,.loc,.iloc(之前有ix方法,pandas1.0之后已被移除)
- df[] :直接索引
- at/iat:通过标签或行号获取某个数值的具体位置。
- loc:通过标签选取数据,即通过index和columns的值进行选取。loc方法有两个参数,按顺序控制行列选取,范围包括start和end。
- iloc:通过行号选取数据,即通过数据所在的自然行列数为选取数据。iloc方法也有两个参数,按顺序控制行列选取。
它们之间的区别不是文本重点,大家可以新建一个dataframe练习一下,本文我们主要来一个错误示范,然后给大家提一些合理的建议。
错误示范
新建一个DataFrame
df = pd.DataFrame(
{'x':[1,5,4,3,4,5],
'y':[.1,.5,.4,.3,.4,.5],
'w':[11,15,14,13,14,15]})
x y w
0 1 0.1 11
1 5 0.5 15
2 4 0.4 14
3 3 0.3 13
4 4 0.4 14
5 5 0.5 15
假设我们要查找与“x”列对应的所有DataFrame元素都大于3,并根据此更改将所有对应的“ y”值更改为50。
我们来先试一个看起来毫无问题的方法
df[df['x']>3]['y']=50
运行之后,df没有任何变化,Warning如下:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
根据提示信息,我们使用loc方法
df.loc[df['x']>3,'y']=50
x y w
0 1 0.1 11
1 5 50.0 15
2 4 50.0 14
3 3 0.3 13
4 4 50.0 14
5 5 50.0 15
得到预期结果√
这是为什么呢?这里我们就遇到了所谓的“链接索引”,具体原因是使用了两个索引器,例如: df[][]
df[df['x']>3] 导致Pandas创建原始DataFrame的单独副本
df[df['x']>3]['y'] = 50 将新值分配给“ y”列,但在此临时创建的副本上,而不是原始DataFrame上。
反转切片的顺序时,即先调用列,然后再调用我们要满足的条件,便得到了预期的结果:
df['y'][df['x']>3]=50
x y w
0 1 0.1 11
1 5 50.0 15
2 4 50.0 14
3 3 0.3 13
4 4 50.0 14
5 5 50.0 15
但是同样会给出一个Warning:
A value is trying to be set on a copy of a slice from a DataFrame
SettingWithCopyWarning 是一个警告 Warning,而不是错误 Error。
这是因为,当我们从DataFrame中仅选择一列时,Pandas会创建一个视图,而不是副本。关于视图和副本的区别,下图最为形象:
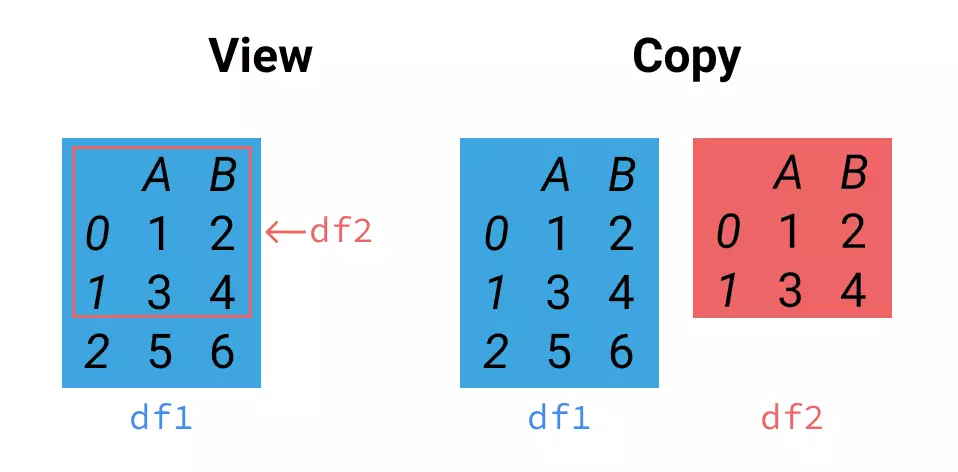
df[]方法会创建视图
df
x y w
0 1 0.1 11
1 5 0.5 15
2 4 0.4 14
3 3 0.3 13
4 4 0.4 14
5 5 0.5 15
z = df['y'] # view of column 'y'
z[z>=0.5] = 30
z
0 0.1
1 30.0
2 0.4
3 0.3
4 0.4
5 30.0
df
x y w
0 1 0.1 11
1 5 30.0 15
2 4 0.4 14
3 3 0.3 13
4 4 0.4 14
5 5 30.0 15
当我们创建了视图后,pandas就会出现warning,因为它不知道我们是否只想更改y系列(通过z)或原始值df。
如果我们要提取“z”作为独立对象怎么办?pandas提供了copy()方法,当我们将命令更新为以下所示的命令时:
z = df['y'].copy()
我们将在内存中创建一个具有其自己地址的全新对象,并且对“z”进行的任何更新df都将不受影响。
实际上有两个要点,可以使我们在使用切片和数据操作时免受任何有害影响:
- 避免链接索引。始终选择.loc/ .iloc(或.at/ .iat)方法;
- 使用copy() 创建独立的对象,并保护原始资源免遭不当操纵。
参考
https://www.jianshu.com/p/199a653e9668
https://www.kdnuggets.com/2020/04/stop-hurting-pandas.html
