很久以前听教学视频,里面讲到Java采用的默认编码是ISO-8859-1,一直记着。
但是最近重新看IO流的时候,惊讶地发现,在不指定字符编码的情况下,FileReader居然可以读取内容为中文的文本文件。要知道ISO-8859-1可是西欧字符集,怎么能包含中文呢?于是百度了一下关键词“IOS-8859-1显示中文”,结果很多人都有这个疑惑。
代码如下:
- package day170903;
-
- import java.io.*;
-
- public class TestDecoder {
- public static void main(String[] args) {
- FileReader fr = null;
- try {
- fr = new FileReader("G:/io/hello.txt");
- int len = 0;
- while((len=fr.read())!=-1) {
- System.out.println((char)len);
- }
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- try {
- if(fr!=null) {
- fr.close();
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- }
事情的真相是什么呢?
编码一般是在构造方法处指定的,于是查看一下FileReader的构造方法。也是奇葩,以前没怎么注意过,FileReader竟然没有可以指定字符编码的构造方法。而且仅仅是简单地从InputStreamReader继承,并没有重写或扩展任何方法。这可能是历史上最吝啬的子类,完全就是啃老族。
不过好在Java的文档注释写得很给力,在FileReader这个类的开头有下面一段文档注释(中文部分为我劣质的翻译):
/**
* Convenience class for reading character files. The constructors of this
* class assume that the default character encoding and the default byte-buffer
* size are appropriate. To specify these values yourself, construct an
* InputStreamReader on a FileInputStream.
*
*这是一个很方便的读取字符文件(文本文件)的类。
*这个类的构造方法假设默认的字符编码和默认的缓存数组大小是合适的(满足需要的)。
*假如你想自己指定字符编码和缓存数组的大小,
*请使用基于FileInputStream的InputStreamReader类。
* <p><code>FileReader</code> is meant for reading streams of characters.
* For reading streams of raw bytes, consider using a
* <code>FileInputStream</code>.
*
*FileReader是设计为用来读取字符流的。
*想要读取原始的字节流的话,可以考虑使用FileInputStream
* @see InputStreamReader
* @see FileInputStream
*
* @author Mark Reinhold
* @since JDK1.1
*/
所以,设计者已经在文档注释中讲明白了这么设计的原因。但是对于我们来说,现在比较重要的是这个所谓的默认的字符编码是什么。
这个时候我们来看一下我们使用的FileReader中的那个构造方法的具体内容。
- public FileReader(String fileName) throws FileNotFoundException {
- super(new FileInputStream(fileName));
- }
FileReader继承自InputStreamReader,调用了InputStreamReader的接受InputStream类型的形参的构造方法,也就是下面这个。
- public InputStreamReader(InputStream in) {
- super(in);
- try {
- sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object
- } catch (UnsupportedEncodingException e) {
- // The default encoding should always be available
- throw new Error(e);
- }
- }
- protected Reader(Object lock) {
- if (lock == null) {
- throw new NullPointerException();
- }
- this.lock = lock;
- }
在这里,它只是把得到的InputStream对象赋值给成员变量lock(看lock这个成员变量的文档注释的话,大概知道它是用来保证同步的),并没有说到字符编码的事。
既然通过super(in)向上查找到父类Reader的构造方法也没有发现默认字符编码的踪迹,那么这条道就到头了。接下来应该看的是super(in)下面的代码,也就是那个异常捕捉语句块。主体语句只有下面一行内容。
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);仔细看FileReader和其它IO流的代码的话会发现,很多输入流的读取功能(read及其重载方法)都是通过这个StreamDecoder完成的,这是后话。在Eclipse里面直接查看这个
StreamDecoder的源码是不行的,需要去openjdk上找。
http://grepcode.com/file/repository.grepcode.com/java/root/jdk/openjdk/6-b14/sun/nio/cs/StreamDecoder.java
上面异常捕捉语句块主体部分调用的是StreamDecoder的forInputStreamReader方法,对应的代码如下:
- public static StreamDecoder forInputStreamReader(InputStream in,
- Object lock,
- String charsetName)
- throws UnsupportedEncodingException
- {
- String csn = charsetName;
- if (csn == null)
- csn = Charset.defaultCharset().name();
- try {
- if (Charset.isSupported(csn))
- return new StreamDecoder(in, lock, Charset.forName(csn));
- } catch (IllegalCharsetNameException x) { }
- throw new UnsupportedEncodingException (csn);
- }
其实调用的时候,传递的第三个参数是字符串形式的null,这个其实就是我们要找的默认字符编码。
我们要找的是默认字符编码,其它代码不必深究。第一行是说把接收到的第三个参数赋值给csn(局部变量:字符编码),当然了,这个是被InputStreamReader的带字符编码参数的构造方法调用的时候才有意义的。没有指定字符编码的构造方法调用StreamDecoder的forInputStreamReader的时候传递是null。所以接下来的if语句判断就成立了,那么csn这个变量得到的就是Charset.defaultCharset().name(),见名知意,即默认字符编码。
接下来就要看Charset这个类的defaultCharset方法的返回值——Charset对象的name()方法的返回值是什么了。说起来有点绕,其实就是找里面的默认字符编码。
- public static Charset defaultCharset() {
- if (defaultCharset == null) {
- synchronized (Charset.class) {
- String csn = AccessController.doPrivileged(
- new GetPropertyAction("file.encoding"));
- Charset cs = lookup(csn);
- if (cs != null)
- defaultCharset = cs;
- else
- defaultCharset = forName("UTF-8");
- }
- }
- return defaultCharset;
- }
这代码看起来很费劲,而且接着又要看其它代码。最终结果是这个所谓的默认字符编码,其实就是JVM启动时候的本地编码。
这个要查看的话,就在对应的项目上点击右键,选择Properties选项,在弹出的属性窗口中,可以看到当前项目在JVM中运行时候的默认字符编码。对于咱们中国人来说,一般都是“GBK”,不过可以根据需要从下拉框选择。
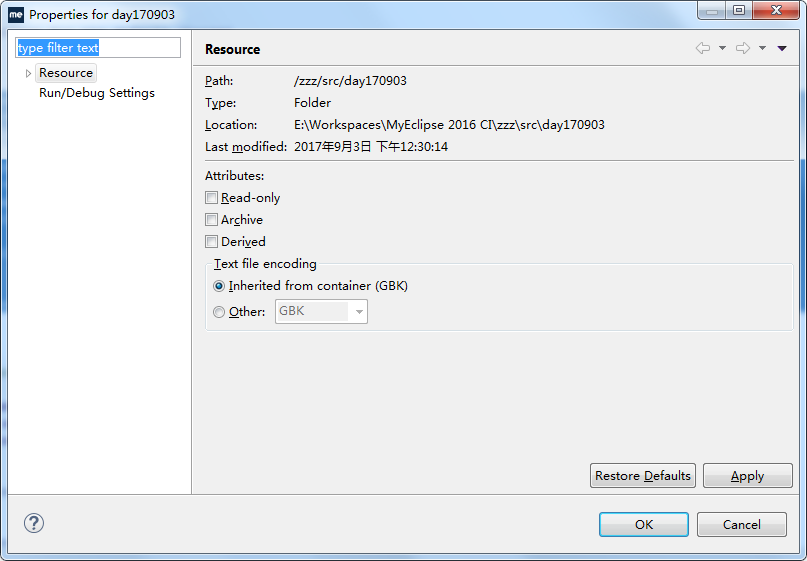
所以开头那个疑问,完全是因为不知道默认的编码其实是GBK而产生的误解。反过来测试一下就好了,先用OutputStreamWriter往文件中写入下面一句法语
Est-ce possible que tu sois en train de penser à moi lorsque tu me manques?
我在想你的时候,你会不会也刚好正在想我?
写入的时候指定字符编码为ISO-8859-1,然后用InputStreamReader读取,读取的时候不指定字符编码(即采用默认字符编码)。那么,假如不能正确还原这句话,就说明默认的字符编码并不是ISO-8859-1。
- package day170903;
-
- import java.io.*;
-
- public class TestDefaultCharEncoding {
- public static void main(String[] args) {
- InputStreamReader isr = null;
- OutputStreamWriter osw = null;
- try {
- osw = new OutputStreamWriter(new FileOutputStream("G:/io/ISO-8859-1.txt"),"ISO-8859-1");
- isr = new InputStreamReader(new FileInputStream("G:/io/ISO-8859-1.txt"));
- char[] chars = "Est-ce possible que tu sois en train de penser à moi lorsque tu me manques?".toCharArray();
- osw.write(chars);
- osw.flush();
- int len = 0;
- while((len=isr.read())!=-1) {
- System.out.print((char)len);
- }
- } catch (UnsupportedEncodingException | FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- try {
- if(isr!=null) {
- isr.close();
- }
- if(osw!=null) {
- osw.close();
- }
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- }
输出结果是:
Est-ce possible que tu sois en train de penser ? moi lorsque tu me manques?
大部分都正确还原了,因为法语中大部分也是英文字母。但是那个法语特有的(相比于英语)à 读出来以后无法识别,变成了问号。
假如默认编码真的是ISO-8859-1,那么读取是完全没有问题的。现在有问题,正好说明默认编码不是ISO-8859-1。
基本上到这儿就完事了,但是还要说一句。虽然我们可以很方便地知道在不指定字符编码的情况下,JVM将会采用什么编码,但是还是建议采用字符类的时候加上字符编码,因为写清楚字符编码可以让别人明白你的原意,而且能避免代码转手后换了一个开发工具后可能出现的编码异常问题。
-----------------------------------------------------------------------------------end
可以因为无能为力而选择视而不见,但是不要因为心知肚明而忘了开口。