马士兵hadoop第一课:虚拟机搭建和安装hadoop及启动
马士兵hadoop第二课:hdfs集群集中管理和hadoop文件操作
马士兵hadoop第四课:Yarn和Map/Reduce配置启动和原理讲解
前三节课主要讲了hdfs,hdfs就是一个分鱼展的大硬盘
分:分块
鱼:冗余
展:动态扩展
接下来讲云计算,也可以理解为分布式计算,其设计原则:
移动计算,而不是移动数据
前面说过,hadoop由hdfs,yarn,map/reduce组成,
而yarn(Yet Another Resource Negotiator)是资源调度系统,yarn调配的是内存和cpu,不参入计算。
map/reduce是计算引擎。
(1)配置yarn
yarn由一台resourceManager和n台dataManager组成,resourceManager管理着n台dataManager,
resourceManager原则上应该和namenode分开,单独在一个节点上,现在是在做实验,为了演示方便,
才放在一起的,而dataManager可以和datanode放在一起,这样dataManager和数据离的近一点,
当然也可以不放在一起。
要启动yarn系统,需要先配置一些参数:
a)配置yarn-size.xml
resourceManager和dataManager每一个节点都需要配置yarn-size.xml,配置如下:

<?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property><property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
b) 配置mapred-site.xml
只需要在master的/usr/local/hadoop/etc/hadoop目录下,
复制mapred-site.xml.template,即执行命令
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
编辑mapred-site.xml,vim mapred-site.xml:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
这是配置map/reduce在哪个系统上运行,这里配置的yarn,也可以配置其他的。
(2)启动yarn
[root@master hadoop]# start-yarn.sh
使用jps查看启动情况
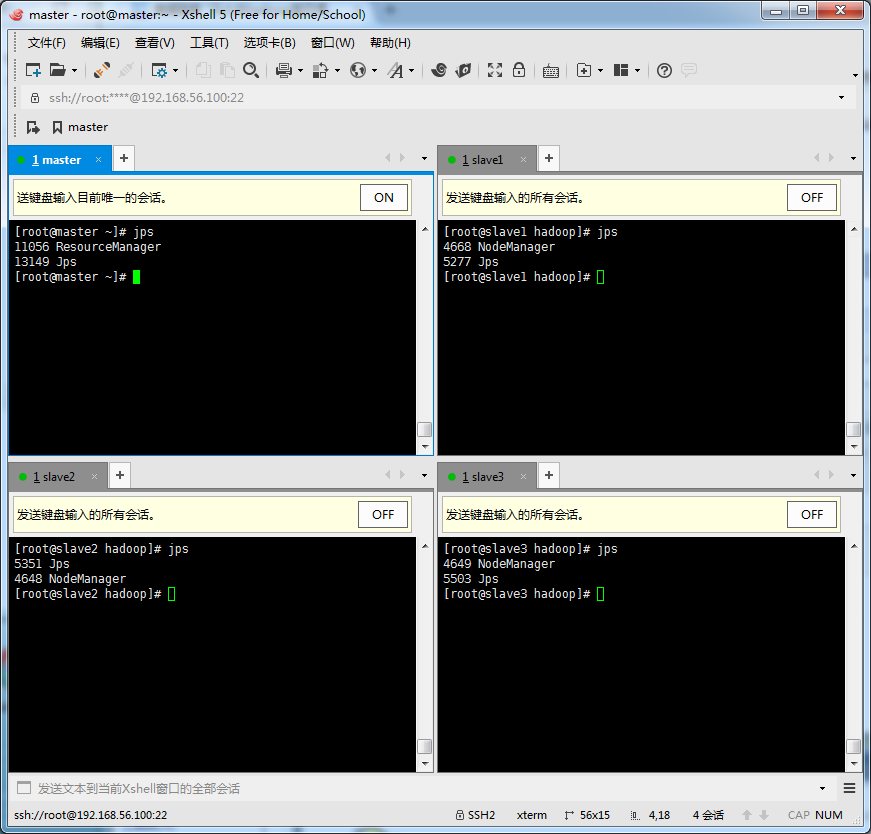
启动成功后,可在浏览器上查看web界面

(3)运行一个map/reduce示例程序
要先把hdfs也启动起来:
[root@master hadoop]# start-dfs.sh
上传一个文件到hdfs的/input目录上
#在namenode的根目录上创建input目录
[root@master hadoop]# hadoop fs -mkdir /input
#上传一个测试文件到hadoop的/input目录上
[root@master hadoop]# hadoop fs -put /root/input.txt /input
input.txt的内容如下:

find /usr/local/hadoop -name *example*.jar 查找示例程序文件
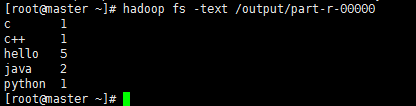
通过hadoop jar xxx.jar wordcount /input /output来运行示例程序
执行结果为: