下面是一个介绍基本概念的例子,参考链接Graph database concepts:
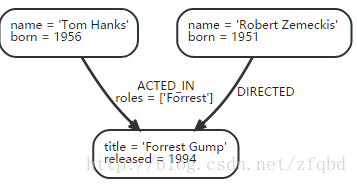
(1) Nodes(节点)
图谱的基本单位主要是节点和关系,他们都可以包含属性,一个节点就是一行数据,一个关系也是一行数据,里面的属性就是数据库里面的row里面的字段。
除了属性之外,关系和节点还可以有零到多个标签,标签也可以认为是一个特殊分组方式。
(2) Relationships(关系)
关系的功能是组织和连接节点,一个关系连接2个节点,一个开始节点和一个结束节点。当所有的点被连接起来,就形成了一张图谱,通过关系可以组织节点形成任意的结构,比如list,tree,map,tuple,或者更复杂的结构。关系拥有方向进和出,代表一种指向。
(3) Properties(属性)
属性非常类似数据库里面的字段,只有节点和关系可以拥有0到多个属性,属性类型基本和java的数据类型一致,分为 数值,字符串,布尔,以及其他的一些类型,字段名必须是字符串。
(4) Labels(标签)
标签通过形容一种角色或者给节点加上一种类型,一个节点可以有多个类型,通过类型区分一类节点,这样在查询时候可以更加方便和高效,除此之外标签在给属性建立索引或者约束时候也会用到。label名称必须是非空的unicode字符串,另外lables最大标记容量是int的最大值,近似21亿。
(5) Traversal(遍历)
查询时候通常是遍历图谱然后找到路径,在遍历时通常会有一个开始节点,然后根据cpyher提供的查询语句,遍历相关路径上的节点和关系,从而得到最终的结果。
(6) Paths(路径)
路径是一个或多个节点通过关系连接起来的产物,例如得到图谱查询或者遍历的结果。
(7) Schema(模式,类似存储数据的结构)
neo4j是一个无模式或者less模式的图谱数据库,像mongodb,solr,lucene或者es一样,你可以使用它不需要定义任何schema,
Indexes(索引)
遍历图通过需要大量的随机读写,如果没有索引,则可能意味着每次都是全图扫描,这样效率非常低下,为了获得更好的性能,我们可以在字段属性上构建索引,这样任何查询操作都会使用索引,从而大幅度提升seek性能,
构建索引是一个异步请求,并不会立刻生效,会再后台创建直至成功后,才能最终生效。如果创建失败,可以重建索引,先删除索引,在创建即可,然后从log里面找出创建失败的原因然后分析。
Constraints(约束)
约束可以定义在某个字段上,限制字段值唯一,创建约束会自动创建索引。
常用的Cypher语句:
删除节点及关系
MATCH (n)-[r]-()
DELETE n,r单纯删除所以节点,注意:如果存在关系的话,先先删关系,才能删除节点:
match (n)
delete n在使用load csv方式批量增加节点时,会考虑到以下问题:如果节点存在,更新或者增加节点属性;如果节点不存在,创建节点,并设置属性:
MERGE (n:user { id: ‘1’ })
ON CREATE SET n.name= ‘quan’
ON MATCH SET n.name= ‘quan’如何根据一个节点返回关于这个节点的所有信息
MATCH (user:User) WHERE user.id = 460
CALL apoc.path.subgraphAll(user, {maxLevel:4}) YIELD nodes, relationships
RETURN nodes, relationships;