原文出处:
https://mp.weixin.qq.com/s/p3JZERyZXnF8jR_3KKIGJA
写作本文时参考了《java并发编程实战》、《java并发编程的艺术》、java源码以及一些博客文章,力求把这个专题的知识讲的足够全面,最重要的是通俗易懂,如文中有错误请与我联系。为保证你把这些知识完全掌握,最好使用电脑观看,投机取巧是学不到东西的,对自己诚实一点哈。
任务执行的几种方式
我们先来看一个现实生活中的例子,拿银行来说,每天都会有很多的客户来办理业务,每个人办理一次业务都可以称为一个任务,为了圆满的完成这些任务,银行可以按照下边的这几种方式来安排工作。
串行执行
银行可以让等待办理业务的客户排成一道长龙,只留一个业务员来办理业务,对应到java程序里,就相当于用1个线程来依次处理所有的任务,这种执行方式我们称之为串行执行。
串行执行的劣势非常好理解,假如有一个办理业务的客户十分墨迹,将影响到后边所有排队的客户,对应到线程里,如果有一个任务里调用了某些阻塞操作,比如I/O操作,那后边的任务将需要等待很长时间,用java代码表示出来就像这个样子:
- public void process(List<Runnable> runnables) {
- for (Runnable r : runnables) {
- r.run();
- }
- }
为每个任务创建一个线程
考虑到用一个业务员来处理业务太慢了,天天遭客户投诉,新来的行长拍大腿决定每个客户都要有一个业务员单独服务,用java语言表述就是为每个任务来创建一个线程单独处理。这样一开始办理业务的客户不多的时候这一招的确听有效,客户们不用再排队了,也不用因为前边的某个客户十分墨迹而影响到后边客户的处理效率了,所以银行一天能接待的客户也明显增多了。用java语言描述,就是程序的响应性和吞吐量明显提高了,接下来用java代码表示一下这个过程:
- public void process(List<Runnable> runnables) {
- for (Runnable r : runnables) {
- new Thread(r).start();
- }
- }
但是随着办理业务的人越来越多,这种模式的弊端慢慢的暴露出来了,比如需要很多的业务员,每个业务员上岗前都要培训就浪费了很多时间,然后银行的柜台渐渐不够用了,慢慢的办理业务的人连大厅都放不下了,人越多越混乱了,导致最后的效率其实不升反降了。对于java的线程来说也存在这种问题,我们前边说过,线程的创建和销毁都是需要系统资源的,而且线程的上下文切换也要浪费很多时间,线程越多浪费的时间越多;在相同时间内分配在每个线程头上的处理时间就越少;每个线程在执行任务的时候都需要分配内存,如果无限制的创建线程,肯定会导致内存不够用的,而且一般的操作系统对线程的创建数量是有限制的。
所以结论就是:在一定范围内增加线程数量的确可以提升系统的处理能力,但是过多的创建线程将会降低系统的处理速度,如果无限制的创建线程,将会使系统崩溃。
线程的重复利用
在经历了一次银行崩溃之后,行长决定只留下10个业务员,让办理业务的客户都排成一队,哪个业务员空闲,就把队头的客户叫走,这样即可以提升处理效率,又可以避免业务员太多带来的烦恼,完美!我们用java代码表示一下:
- public void process(List<Runnable> runnables) {
- final Queue<Runnable> queue = new ConcurrentLinkedQueue<>(runnables); //同步队列
-
- for (int i = 0; i < 10; i++) {
- new Thread(new Runnable() {
-
- @Override
- public void run() {
- while (true) {
- Runnable r = queue.poll();
- if (r == null) { //如果没任务了就退出
- break;
- }
- r.run(); //执行任务
- }
- }
- }).start();
- }
- }
可以看到,我们一共创建了10个线程,每个线程都试图从任务队列中取任务来做,直到任务队列里没有任务了才退出。
Executor框架
我们上边唠叨的3种任务的执行方式用一个高大上的词儿描述就是任务的执行策略,每个执行策略都要规定很多任务的执行细节,比如用多少线程去执行任务;是在把线程都创建好之后再去处理任务,还是遇到任务之后再创建线程;创建好的线程在空闲的时候能不能销毁等等的问题,如果我们乐意,我们可以定义很多的执行策略。
Executor接口的提出
其实对于客户端程序员来说,每次在执行某些任务的时候都要设计一种新的执行策略太累人了,所以设计java的大叔们就帮助客户端程序员设计了这样的一个接口:
- public interface Executor {
- void execute(Runnable command);
- }
Executor翻译过来的意思就是执行器,设计java的大叔们针对不同的执行策略定义了不同的Executor子类(我们稍后介绍)。客户端程序员只需要把Runnable任务放到执行器的execute方法里就表示任务提交了,具体提交以后这些任务怎么分配线程怎么执行就不管了。这也就是:把任务的提交和执行解耦开来了。我们先举个例子看一下执行器怎么用:
- public void process(List<Runnable> runnables) {
- Executor executor = Executors.newFixedThreadPool(10); //创建包含10个线程的执行器
-
- for (Runnable r : runnables) {
- executor.execute(r); //提交任务
- }
- }
其中的Executors类提供了一系列创建Executor子类的静态方法,上边newFixedThreadPool(10)方法代表创建了一个包含10个线程Executor,可以用这10个线程去执行任务。更多的使用方式我们下节详细唠叨。
我们也可以自定义自己的执行策略,比如对于串行执行的策略,可以定义一个这样的Executor子类:
- public class SerialExecutor implements Executor {
- @Override
- public void execute(Runnbale r) {
- r.run();
- }
- }
对于为每个任务创建一个线程的策略,可以定义一个这样的子类:
- public class ThreadPerRunnalbeExecutor implements Executor {
- @Override
- public void executor(Runnbale r) {
- new Thread(r).start();
- }
- }
我们下边深入看一下java类库中都针对哪些执行策略提供了执行器。
类库中的线程池
由于Executor子类负责执行任务,所以里边肯定要包含一些线程,才能使用这些线程去执行任务,所以Executor子类也叫做线程池,寓意盛放线程的池子。一般情况下,调用 Executor 的 execute方法会把该任务塞到一个队列中,然后线程池中的线程从这个队列中取任务执行。
Executors类里提供了创建适用于各种场景线程池的工具方法(静态方法),我们看一下常用的几个:
注意,是`Executors`类,不是`Executor`接口,不要认错哦。就和`Collections`和`Collection`不是一个东西一样~
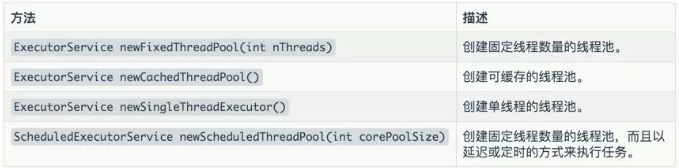
大家可以看到有的方法返回类型是ExecutorService,有的是ScheduledExecutorService,其实这两个都是Executor的子接口,稍后我们会详细说道的。下边我们看一下这几个方法的详细用法。
newFixedThreadPool(int nThreads)
通过此方法可以创建一个拥有固定线程数量的线程池,具体的线程数量由nThreads参数指定。
这里所说的固定线程数量的线程池的意思是:最开始该线程池中的线程数为0,之后每提交一个任务就会创建一个线程,直到线程数等于指定的nThreads参数,此后线程数量将不再变化。
newCachedThreadPool()
通过此方法可以创建一个可缓存的线程池。
可缓存的意思是:会为每个任务都分配一个线程,但是如果一个线程执行完任务后长时间(60秒)没有新的任务可执行,该线程将被回收。
newSingleThreadExecutor()
通过此方法可以创建单线程的线程池。
其实只有一个线程也不好意思叫线程池了,不过为了统一名称,也就勉强叫一声线程池吧~ 被提交到该线程的任务将在一个线程中串行执行,并且能确保任务可以按照队列中的顺序串行执行。
newScheduledThreadPool(int corePoolSize)
通过此方法可以创建固定线程数量的线程池,而且以延迟或定时的方式来执行任务。怎么以延迟或定时的方式执行任务呢?我们看一下该方法的返回类型ScheduledExecutorService里提供的几个方法:
- public interface ScheduledExecutorService extends ExecutorService {
-
- public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
-
- public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
-
- public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
-
- public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
- }
真的很抱歉,这段代码里出现了ScheduledFuture和Callable两个你可能不认识的东东,我们先不理它们,之后说到的时候再看,返回这个线程池,看看这几个方法(参数中带Callable的先略过)都是干什么的:

其中后两个方法的参数都是一模一样的,而且意义貌似也有点像,那就举个现实生活的例子吧,比如有很多同学在跑道上跑圈。
scheduleAtFixedRate规定在前边的同学出发1分钟后第后边同学就可以跑了,如果在1分钟之内前边的同学顺利跑完了1圈,后边的同学就可以按照约定出发,否则的话虽然1分钟时间到了,后边的同学还是要等待前边的同学到达终点后才可以出发。
scheduleWithFixedDelay规定在前边的同学跑完一圈之后再过1分钟才能出发。
示例
好了,知道了这些方法是神马意思,写个程序瞅瞅:
- import java.util.concurrent.Executors;
- import java.util.concurrent.ScheduledExecutorService;
- import java.util.concurrent.TimeUnit;
-
- public class ScheduleDemo {
-
- private static class PrintTask implements Runnable {
-
- private String s;
-
- public PrintTask(String s) {
- this.s = s;
- }
-
- @Override
- public void run() {
- System.out.println(s);
- }
- }
-
- public static void main(String[] args) {
- ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
-
- //隔1秒后打印
- service.schedule(new PrintTask("1"), 1, TimeUnit.SECONDS);
-
- //首次5秒后打印,每隔1秒打印一次
- service.scheduleAtFixedRate(new PrintTask("2"), 5, 1, TimeUnit.SECONDS);
- }
- }
Callable与Future
我们之前都是以Runnable表示任务的,再次看一下这个接口:
- public interface Runnable {
- public void run();
- }
它里边只有一个返回void的run方法,我们定义一个计算两个值大小的Runnable:
- public class AddTask implements Runnable {
-
- private int i;
-
- private int j;
-
- public AddTask(int i, int j) {
- this.i = i;
- this.j = j;
- }
-
- @Override
- public void run() {
- int sum = i + j;
- System.out.println("线程t的运算结果:" + sum);
- }
- }
下边我们在main线程中创建一个t线程去执行这个任务:
- public class Test {
- public static void main(String[] args) {
- AddTask task = new AddTask(1, 2);
- Thread t = new Thread(task, "t");
- t.start();
- }
- }
执行结果是:
线程t的运算结果:3
以上是一个很常见的显式创建线程去运行Runnable任务的使用案例,但是这种方式有个问题,就是main线程一旦调用了t线程的start方法,这两个线程就好像没关系了,也就是说main线程既不知道t线程现在是不是运行完了,也不知道t线程执行的任务的结果是什么,也不知道在运行任务的过程中是不是发生了异常。所以设计java的大叔们在设计Executor的各种子类的时候特意把这个事情考虑了进去,提出了带返回值的Callable任务以及用于检测任务执行情况的Future接口。
Callable是一个接口,它代表一个任务,与Runnable不同的是,这个任务是有返回值的:
- public interface Callable<V> {
- V call() throws Exception;
- }
我们可以把AddTask定义成一个Callable任务:
- import java.util.concurrent.Callable;
-
- public class AddTask implements Callable<Integer> {
-
- private int i;
-
- private int j;
-
- public AddTask(int i, int j) {
- this.i = i;
- this.j = j;
- }
-
- @Override
- public Integer call() throws Exception {
- int sum = i + j;
- System.out.println("线程main的运算结果:" + sum);
- return sum;
- }
- }
其中的call方法返回了两个字段的和。这种带返回值的Callable任务不能像Runnable一样直接通过Thread的构造方法传入,在Executor的子接口ExecutorService中规定了Callable任务的提交方式:
- public interface ExecutorService extends Executor {
-
- // 任务提交操作
- <T> Future<T> submit(Callable<T> task);
- Future<?> submit(Runnable task);
- <T> Future<T> submit(Runnable task, T result);
-
- // 生命周期管理
- void shutdown();
- List<Runnable> shutdownNow();
- boolean isShutdown();
- boolean isTerminated();
- boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
-
- // ... 省略了各种方便提交任务的方法
- }
可以看到,ExecutorService主要扩展了任务的提交方式、生命周期管理(稍后马上唠叨)和一系列方便提交任务的方法(这个没啥意思,等遇到了再说哈),我们这一节主要唠叨任务的提交方式。这个ExecutorService我们之前见过,Executors的各种创建线程池的工具方法的返回类型就是它,我们再重温一遍:

(注:ScheduledExecutorService继承了ExecutorService)
也就是说,各种线程池其实都是实现了 ExecutorService 的,Callable 任务需要提交到线程池中才能运行:
- public class Test {
- public static void main(String[] args) {
- ExecutorService service = Executors.newCachedThreadPool();
-
- service.submit(new AddTask(1, 2));
- }
- }
执行结果是:
线程t的运算结果:3
带返回值的Callable任务通过线程池的submit方法总算是提交并执行了哈哈。其实不管是Runnable任务还是Callable任务,线程池执行的任务可以划分为4个生命周期阶段:
-
创建:创建任务对象的时期。
-
提交:调用线程池的
excute或者submit方法后,将任务塞到任务队列的时期。 -
执行中:某个线程从任务队列中将任务取出开始执行的时期。
-
完成:任务执行结束。
任务的生命周期只能前进,不能后退,也就是说如果一个任务已经执行完成了,也就是处于完成阶段,那么就无法后退到提交阶段。我们可以在任务的执行过程中取消任务,如何取消我们之后会详细唠叨。如果我们通过线程池的submit方法提交了任务,那我们可以得到一个Future对象,它表示一个任务的实时执行状态,并提供了判断是否已经完成或取消的方法,也提供了取消任务和获取任务的运行结果的方法。线程池的submit方法的返回类型Future,其实是一个接口:
- public interface Future<V> {
- V get() throws InterruptedException, ExecutionException;
- V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
- boolean isDone();
- boolean cancel(boolean mayInterruptIfRunning);
- boolean isCancelled();
- }
各个方法的大致描述如下:

需要注意的是,如果该任务已经完成,那么get方法将会立即返回,如果任务正常完成的话,会返回执行结果,若是抛出异常完成的话,将会将该异常包装成ExecutionException后重新抛出,如果任务被取消,则调用get方法会抛出CancellationExection异常。下边我们试试Future的用法:
- public class Test {
- public static void main(String[] args) throws Exception{
- ExecutorService service = Executors.newCachedThreadPool(); //创建一个线程池
- Future<Integer> future = service.submit(new AddTask(1, 2)); //提交一个任务
- int result = future.get(); //在任务执行完成之前,该方法将一直阻塞
- System.out.println("线程main的运算结果:" + result);
- }
- }
执行结果是:
- 线程t的运算结果:3
- 线程main的运算结果:3
有时候我们希望在指定时间内等待另一个线程的执行结果,那就可以可以使用带时间限制的get方法,另外的几个方法我们之后再详细的说。
视线再返回到ExecutorService接口上来,除了参数类型为Callable的submit方法,这个接口还提供了两个重载方法:
- Future<?> submit(Runnable task); //第1个重载方法
- <T> Future<T> submit(Runnable task, T result); //第2个重载方法
对于第1个只有一个Runnable参数的重载方法来说,由于Runnable的run方法并没有返回值,也就是说任务是没有返回值的,所以在该任务完成之后,对应的Future对象的get方法的返回值就是null。虽然不能获得返回值,但是我们还是可以调用Future的其他方法,比如isDone表示任务是否已经完成,isCancelled表示任务是否已经被取消,cancel表示尝试取消一个任务(稍后详细说明)。
对于第2个带有两个参数的重载方法来说,其实和第1个的意思差不多,只不过我们可以指定该Runnable任务对应的Future对象的get方法的返回值,也就是说方法参数result其实就是get方法的返回值。有的小伙伴会问了,你还没执行任务的时候就把任务返回值给指定了是几个意思???我也不是很清楚,可能有用到的地方吧,你先记住用法就好了。
小贴士:
如果你已经大致理解了Callable和Future的用法,有没有想过它们是怎么实现的呢?其实无非是线程间通信的那一套东西,一个线程等待另一个线程完成任务之后的通知,然后通过某个共享变量来传递数据,如果你有兴趣的话可以试着自己实现一个Callable和Future。
如果你从本文中学到的知识有助于你解决眼前的工作、学习问题,或者对你的升职加薪起到了作用,可以点击下方喜欢作者,谢谢~