1 需求背景
该应用场景为AdMaster DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称admckid)的mapping关系,还包括了admckid的人口标签、移动端id(主要是idfa和imei)的人口标签,以及一些黑名单id、ip等数据。 在hdfs的帮助下离线存储千亿记录并不困难,然而DMP还需要提供毫秒级的实时查询。由于cookie这种id本身具有不稳定性,所以很多的真实用户的浏览行为会导致大量的新cookie生成,只有及时同步mapping的数据才能命中DMP的人口标签,无法通过预热来获取较高的命中,这就跟缓存存储带来了极大的挑战。 经过实际测试,对于上述数据,常规存储超过五十亿的kv记录就需要1T多的内存,如果需要做高可用多副本那带来的消耗是巨大的,另外kv的长短不齐也会带来很多内存碎片,这就需要超大规模的存储方案来解决上述问题。
2 存储何种数据
人⼝标签主要是cookie、imei、idfa以及其对应的gender(性别)、age(年龄段)、geo(地域)等;mapping关系主要是媒体cookie对admckid的映射。以下是数据存储⽰示例: 1) PC端的ID: 媒体编号-媒体cookie=>admckid admckid => { age=>年龄段编码,gender=>性别编码,geo=>地理位置编码 } 2) Device端的ID: imei or idfa => { age=>年龄段编码,gender=>性别编码,geo=>地理位置编码 } 显然PC数据需要存储两种key=>value还有key=>hashmap,⽽而Device数据需要存储⼀一种 key=>hashmap即可。
3 数据特点
短key短value:其中superid为21位数字:比如1605242015141689522;imei为小写md5:比如2d131005dc0f37d362a5d97094103633;idfa为大写带”-”md5:比如:51DFFC83-9541-4411-FA4F-356927E39D04; 媒体自身的cookie长短不一; 需要为全量数据提供服务,admckid是百亿级、媒体映射是千亿级、移动id是几十亿级; 每天有十亿级别的mapping关系产生; 对于较大时间窗口内可以预判热数据(有一些存留的稳定cookie); 对于当前mapping数据无法预判热数据,有很多是新生成的cookie;
4 存在的技术挑战
1)长短不一容易造成内存碎片; 2)由于指针大量存在,内存膨胀率比较高,一般在7倍,纯内存存储通病; 3)虽然可以通过cookie的行为预判其热度,但每天新生成的id依然很多(百分比比较敏感,暂不透露); 4)由于服务要求在公网环境(国内公网延迟60ms以下)下100ms以内,所以原则上当天新更新的mapping和人口标签需要全部in memory,而不会让请求落到后端的冷数据; 5)业务方面,所有数据原则上至少保留35天甚至更久; 6)内存至今也比较昂贵,百亿级Key乃至千亿级存储方案势在必行!
5 解决方案
5.1 淘汰策略 存储吃紧的一个重要原因在于每天会有很多新数据入库,所以及时清理数据尤为重要。主要方法就是发现和保留热数据淘汰冷数据。 网民的量级远远达不到几十亿的规模,id有一定的生命周期,会不断的变化。所以很大程度上我们存储的id实际上是无效的。而查询其实前端的逻辑就是广告曝光,跟人的行为有关,所以一个id在某个时间窗口的(可能是一个campaign,半个月、几个月)访问行为上会有一定的重复性。 数据初始化之前,我们先利用hbase将日志的id聚合去重,划定TTL的范围,一般是35天,这样可以砍掉近35天未出现的id。另外在Redis中设置过期时间是35天,当有访问并命中时,对key进行续命,延长过期时间,未在35天出现的自然淘汰。这样可以针对稳定cookie或id有效,实际证明,续命的方法对idfa和imei比较实用,长期积累可达到非常理想的命中。 5.2 减少膨胀 Hash表空间大小和Key的个数决定了冲突率(或者用负载因子衡量),再合理的范围内,key越多自然hash表空间越大,消耗的内存自然也会很大。再加上大量指针本身是长整型,所以内存存储的膨胀十分可观。先来谈谈如何把key的个数减少。 大家先来了解一种存储结构。我们期望将key1=>value1存储在redis中,那么可以按照如下过程去存储。先用固定长度的随机散列md5(key)值作为redis的key,我们称之为BucketId,而将key1=>value1存储在hashmap结构中,这样在查询的时候就可以让client按照上面的过程计算出散列,从而查询到value1。 过程变化简单描述为:get(key1) -> hget(md5(key1), key1) 从而得到value1。 如果我们通过预先计算,让很多key可以在BucketId空间里碰撞,那么可以认为一个BucketId下面挂了多个key。比如平均每个BucketId下面挂10个key,那么理论上我们将会减少超过90%的redis key的个数。 具体实现起来有一些麻烦,而且用这个方法之前你要想好容量规模。我们通常使用的md5是32位的hexString(16进制字符),它的空间是128bit,这个量级太大了,我们需要存储的是百亿级,大约是33bit,所以我们需要有一种机制计算出合适位数的散列,而且为了节约内存,我们需要利用全部字符类型(ASCII码在0~127之间)来填充,而不用HexString,这样Key的长度可以缩短到一半。 下面是具体的实现方式
public static byte getBucketId(byte [] key,Integer bit) { MessageDigest mdInst =MessageDigest.getInstance("MD5"); mdInst.update(key); byte md =mdInst.digest; byte r = new byte[(bit-1)/7 + 1];// 因为一个字节中只有7位能够表示成单字符inta = (int) Math.pow(2, bit%7)-2; md[r.length-1] = (byte) (md[r.length-1] &a); System.arraycopy(md, 0, r, 0, r.length); for(int i=0;i<r.length;i++) {if(r[i]<0) r[i] &= 127; } return r; }
参数bit决定了最终bucketid空间的大小,空间大小集合是2的整数幂次的离散值。这里解释一下为何一个字节中只有7位可用,是因为redis存储key时需要是ascii(0~127),而不是byte array。如果规划百亿级存储,计划每个桶分担10个kv,那么我们只需2^30=1073741824的桶个数即可,也就是最终key的个数。
5.3 减少碎片
碎片主要原因在于内存无法对齐、过期删除后,内存无法重新分配。通过上文描述的方式,我们可以将人口标签和mapping数据按照上面的方式去存储,这样的好处就是redis key是等长的。另外对于hashmap中的key我们也做了相关优化,截取cookie或者deviceid的后六位作为key,这样也可以保证内存对齐,理论上会有冲突的可能性,但在同一个桶内后缀相同的概率极低(试想id几乎是随机的字符串,随意10个由较长字符组成的id后缀相同的概率*桶样本数="发生冲突的期望值<<0.05,也就是说出现一个冲突样本则是极小概率事件,而且这个概率可以通过调整后缀保留长度控制期望值)。而value只存储age、gender、geo的编码,用三个字节去存储。
另外提一下,减少碎片还有个很low但是有效的方法,将slave重启,然后强制的failover切换主从,这样相当于给master整理的内存的碎片。
推荐google-tcmalloc,facebook-jemalloc内存分配,可以在value不大时减少内存碎片和内存消耗。有人测过大value情况下反而libc更节约。
6. md5散列桶的方法需要注意的问题
1)kv存储的量级必须事先规划好,浮动的范围大概在桶个数的十到十五倍,比如我就想存储百亿左右的kv,那么最好选择30bit~31bit作为桶的个数。也就是说业务增长在一个合理的范围(10~15倍的增长)是没问题的,如果业务太多倍数的增长,会导致hashset增长过快导致查询时间增加,甚至触发zip-list阈值,导致内存急剧上升。
2)适合短小value,如果value太大或字段太多并不适合,因为这种方式必须要求把value一次性取出,比如人口标签是非常小的编码,甚至只需要3、4个bit(位)就能装下。
3)典型的时间换空间的做法,由于我们的业务场景并不是要求在极高的qps之下,一般每天亿到十亿级别的量,所以合理利用cpu租值,也是十分经济的。
4)由于使用了信息摘要降低了key的大小以及约定长度,所以无法从redis里面random出key。如果需要导出,必须在冷数据中导出。
5)expire需要自己实现,目前的算法很简单,由于只有在写操作时才会增加消耗,所以在写操作时按照一定的比例抽样,用hlen命中判断是否超过15个entry,超过才将过期的key删除,ttl的时间戳存储在value的前32bit中。
6)桶的消耗统计是需要做的。需要定期清理过期的key,保证redis的查询不会变慢。
7. 测试结果
人口标签和mapping的数据100亿条记录。
优化前用2.3t,碎片率在2左右;优化后500g,而单个桶的平均消耗在4左右。碎片率在1.02左右。查询时这对于cpu的耗损微乎其微。
另外需要提一下的是,每个桶的消耗实际上并不是均匀的,而是符合多项式分布的。
上面的公式可以计算桶消耗的概率分布。公式是唬人用的,只是为了提醒大家不要想当然的认为桶消耗是完全均匀的,有可能有的桶会有上百个key。但事实并不没有那么夸张。试想一下投硬币,结果只有两种正反面。相当于只有两个桶,如果你投上无限多次,每一次相当于一次伯努利实验,那么两个桶必然会十分的均匀。概率分布就像上帝施的魔咒一样,当你面对大量的桶进行很多的广义的伯努利实验。桶的消耗分布就会趋于一种稳定的值。接下来我们就了解一下桶消耗分布具体什么情况:
通过采样统计
31bit(20多亿)的桶,平均4.18消耗
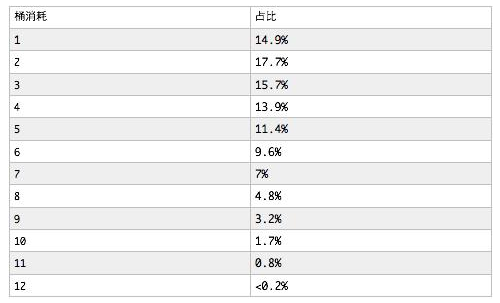
100亿节约了1.8t内存。相当于节约了原先的78%内存,而且桶消耗指标远没有达到预计的底线值15。
对于未出现的桶也是存在一定量的,如果过多会导致规划不准确,其实数量是符合二项分布的,对于2^30桶存储2^32kv,不存在的桶大概有(百万级别,影响不大):
Math.pow((1 - 1.0 / Math.pow(2, 30)),Math.pow(2, 32)) * Math.pow(2, 30);
对于桶消耗不均衡的问题不必太担心,随着时间的推移,写入时会对hlen超过15的桶进行削减,根据多项式分布的原理,当实验次数多到一定程度时,桶的分布就会趋于均匀(硬币投掷无数次,那么正反面出现次数应该是一致的),只不过我们通过expire策略削减了桶消耗,实际上对于每个桶已经经历了很多的实验发生。
总结:信息摘要在这种场景下不仅能节约key存储,对齐了内存,还能让key按照多项式分布均匀的散列在更少量的key下面从而减少膨胀,另外无需在给key设置expire,也很大程度上节约了空间。
这也印证了时间换空间的基本理论,合理利用cpu租值也是需要考虑的。