<div class="entry-content">
<h1></h1>
背景
公司有一个业务场景,数据库的修改需要同步到Elasticsearch里,但是该场景的修改频率有点高,经常会出现一条记录短时间内多次的变化,如果每次变化都作为一次ES同步任务,那ES肯定是受不住的。
思路
通过估算请求规模,主要有如下2方面的解决思路:
- 高频变化去重:因为同一条记录短时间内多次变化,其实同步一次最终的状态即可,所以可以考虑牺牲一定的实时性,在一定时间窗口内做变化通知的去重。
- 批量导入:每条记录变化作为独立请求推送给ES,实际上远不如多条记录批量推送ES的吞吐要高。
方案
- 在线去重:因为在线业务本身是高频的,所以需要一个高频的存储介质来实现去重,想到redis的set/zset数据结构。
- 离线批量:利用离线JOB定时的将一段时间内去重的变动集合推送给ES,其核心问题在于在线set集合如何离线化,保证互不影响。
整体架构如下:
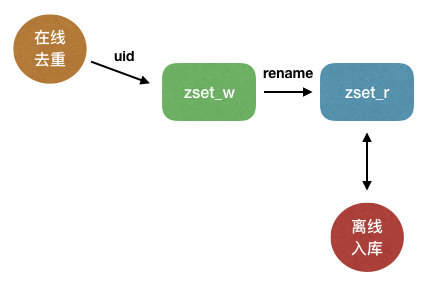
假设变动的是用户的积分等高频资产信息,那么在线部分一旦数据库发生变动,则将用户uid向zset_w在线集合写入,可以实现实时去重。
离线JOB则首先检查zset_r离线集合是否有剩余变动任务未处理,若zset_r集合为空则执行redis的rename操作将在线集合zset_w重命名为zset_r,这个过程对redis来说是原子性的。
此后离线JOB继续处理zset_r中已经去重的变化uid集合,而在线部分继续向新的zset_w集合添加最新变动的uid即可,如此往复。
优化
随着在线高频变更量的增多,该方案可以实施横向扩展,即准备N对(zset_w、zset_r)并令在线部分按uid打散流量,从而可以为每一对zset启动独立的离线JOB,实现并行处理。
鉴于在线部分操作redis异常导致通知丢失,可以通过长周期的全库离线补偿实现,在此不做说明。
结论
该业务场景的思想本质包含了2点:
- 流式转批量 换取更高的吞吐。
- 大问题拆小 实现横向的扩展。
总是思考是否有更简单的方案,做到简单可依赖。