前言
之前了解了Elasticsearch的基本概念。将spring boot + ElasticSearch + head插件 搞通之后。紧接着对es进行下一步的探索:集群。查阅资料的过程中,找到了一篇超鸡详细的博客~~转载以方便日后查阅。亲自实践能更快理解哦。
二话不说,先贴上转载地址,QAQ:
博客出处(博主):Thinkgamer博客
博客原文地址:Elasticsearch5.2.1集群搭建,动态加入节点,并添加监控诊断插件
还有一篇es安装head教程,一并贴上地址:ElasticSearch-5.0安装head插件
注:以下均为转载博客内容
写在前面的话
之前写过一篇文章是: 如何使用一个IP搭建ES集群——Docker如你所愿,在该篇文章中说明了Elasticsearch集群的单播和多播的概念和差别,以及在生产环境中的利与弊。其实在里边也写了怎么搭建集群,但是整个流程走下来是有很多bug的,那么这篇文章就好好聊一下如何搭建一个完整的Elasticsearch集群,并灵活添加节点。
环境准备
1:Elasticsearch 5.2.1 ZIP包下载:点击下载
2:Ubuntu 16.04
3:Java 1.8
4:解压包到/opt/elk/目录下,生成两个Elasticsearch文件夹,如下
>ls /opt/elk
elasticsearch-5.2.1_1 elasticsearch-5.2.1_2
- 1
- 2
5:赋予权限,否则在启动的过程中会报错(可选,根据自己的情况而定)
sudo chown -R master;master elasticsearch-5.2.1_*
- 1
配置说明
注意:以下配置过程中可能会出现权限错误,由于我是在/opt/elk目录下进行的,所以有权限问题
1:Elasticsearch集群中的三种角色
- master node:master几点主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等。
- data node:data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
- client node:client 节点起到路由请求的作用,实际上可以看做负载均衡器。
其对应的高性能集群拓扑结构模式为:
# 配置文件中给出了三种配置高性能集群拓扑结构的模式,如下:
# 1. 如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器
# node.master: false
# node.data: true
# 2. 如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
# node.master: true
# node.data: false
# 3. 如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等
# node.master: false
# node.data: false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2:config/elasticsearch.ymal中配置项说明
- cluster_name 集群名称,默认为elasticsearch,这里我们设置为es5.2.1Cluster
- node.name配置节点名,用来区分节点
- network.host 是配置可以访问本节点的路由地址
- http.port 路由地址端口
- transport.tcp.port TCP协议转发地址端口
- node.master 是否作为集群的主结点 ,值为true或true
- node.data 是否存储数据,值为true或true
- discovery.zen.ping.unicast.hosts 用来配置所有用来组建集群的机器的IP地址,由于5.2.1新版本是不支持多播的,因此这个值需要提前设定好,当集群需要扩展的时候,该值都要做改变,增加新机器的IP地址,如果是在一个ip上,要把TCP协议转发端口写上
- discovery.zen.minimum_master_nodes 用来配置主节点数量的最少值,如果主节点数量低于该值,闭包范围内的集群将会停止服务,之所以加粗体,是因为暂时尚未认证,下面配置为1方便集群更容易形成,即使只有一个主节点,也可以构建集群
- gateway.* 网关的相关配置
- script.* indices.* 根据需求添加的配置(可选)
3:elasticsearch-5.2.1_1中的yaml文件
该结点作为master-node运行
cluster.name: es5
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
gateway.expected_nodes: 1
script.engine.groovy.inline.search: on
script.engine.groovy.inline.aggs: on
indices.recovery.max_bytes_per_sec: 20mb
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4:elasticsearch-5.2.1_2中的yaml文件
该结点作为data-node运行
cluster.name: es5
node.name: node-2
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9301
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
gateway.expected_nodes: 1
script.engine.groovy.inline.search: on
script.engine.groovy.inline.aggs: on
indices.recovery.max_bytes_per_sec: 20mb
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5:elasticsearch-5.2.1_3中的yaml文件
该结点作为client-node运行
cluster.name: es5
node.name: node-3
network.host: 0.0.0.0
http.port: 9202
transport.tcp.port: 9302
node.master: false
node.data: false
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
gateway.expected_nodes: 1
script.engine.groovy.inline.search: on
script.engine.groovy.inline.aggs: on
indices.recovery.max_bytes_per_sec: 20mb
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
启动三个结点,打开http://localhost:9200/

查看 http://localhost:9200/_cluster/health?pretty=true 出现错误:
no known master node, scheduling a retry
- 1
原因是:我们设置的主节点只有一个而
discovery.zen.minimum_master_nodes: 2
- 1
所以这里改为1即可,然后此时还可能会遇到一个问题就是node2和node3不能加入到集群,报的错如下:
[node-2] failed to send join request to master [{node-1}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:9300}], reason [RemoteTransportException[[node-1][10.10.11.200:9300][internal:discovery/zen/join]]; nested: IllegalArgumentException[can't add node {node-2}{WbcP0pC_T32jWpYvu5is1A}{p-HCgFLvSFaTynjKSeqXyA}{10.10.11.200}{10.10.11.200:9301}, found existing node {node-1}{WbcP0pC_T32jWpYvu5is1A}{2_LCVHx1QEaBZYZ7XQEkMg}{10.10.11.200}{10.10.11.200:9300} with the same id but is a different node instance]; ]
- 1
原因是:是因为复制的elasticsearch文件夹下包含了data文件中示例一的节点数据,需要把示例二data文件下的文件清空。
然后在查看集群状态:
{
"cluster_name" : "es5",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 2,
"active_primary_shards" : 22,
"active_shards" : 22,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 21,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 51.162790697674424
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6:配置head插件
克隆到本地:
git clone git://github.com/mobz/elasticsearch-head.git
- 1
进入到文件夹,并安装
cd elasticsearch-head
npm install
- 1
- 2
在elasticsearch.ymal文件中添加:
http.cors.enabled: true
http.cors.allow-origin: "*"
- 1
- 2
运行
npm install -g grunt
grunt server
- 1
- 2
配置logstash解析rsyslog文件
配置rsyslog参考:http://blog.csdn.net/gamer_gyt/article/details/54025857
编写相应的jx_syslog.conf 解析文件
input {
tcp{
port => 5000
type => syslog
}
udp{
port => 5000
type => syslog
}
}
filter {
if [type] == 'syslog'{
grok {
match => { 'message' => '%{SYSLOGTIMESTAMP:syslog_timestamp} %{HOSTNAME:hostname} %{WORD:program}%{GREEDYDATA:msgsplit}'
}
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
target => "syslog_timestamp"
timezone => "UTC"
}
# processing repeated messages
if [msgsplit] =~ "message repeated " {
grok { match => [ "msgsplit", "[%{BASE10NUM:pid}]: message repeated %{BASE10NUM:ntimes} times: [ Failed password for %{NOTSPACE:user} from %{IP:src_ip} port %{BASE10NUM:src_port} %{WORD:protocol}]" ]
tag_on_failure => ["parsefailure", "ssh_failed_login", "ssh_repeat_message" ]
add_tag => [ "ssh_repeat_message", "grokked", "ssh_failed_login" ]
}
}
# SSH successful login
else if [msgsplit] =~ "Accepted password for" {
mutate {
replace => { type => "success_syslog" }
}
grok {
match => [ "msgsplit", "[%{BASE10NUM:pid}]: Accepted password for %{NOTSPACE:user} from %{IP:src_ip} port %{BASE10NUM:src_port} %{WORD:protocol}" ]
tag_on_failure => ["parsefailure", "ssh_successful_login" ]
add_tag => [ "ssh_successful_login", "grokked" ]
}
}
# SSH Brute force attemp
else if [msgsplit] =~ "Failed password for invalid user" {
mutate {
replace => { type => "brute_syslog" }
}
grok {
match => [ "msgsplit", "[%{BASE10NUM:pid}]: Failed password for invalid user %{NOTSPACE:user} from %{IP:src_ip} port %{BASE10NUM:src_port} %{WORD:protocol}" ]
add_tag => [ "ssh_brute_force", "grokked" ]
tag_on_failure => ["parsefailure", "ssh_brute_force" ]
}
}
# SSH failed login
else if [msgsplit] =~ "Failed password for" {
mutate {
replace => { type => "fail_syslog" }
}
grok { match => [ "msgsplit", "[%{BASE10NUM:pid}]: Failed password for %{NOTSPACE:user} from %{IP:src_ip} port %{BASE10NUM:src_port} %{WORD:protocol}" ]
add_tag => [ "ssh_failed_login", "grokked" ]
tag_on_failure => ["parsefailure", "ssh_failed_login" ]
}
}
else {
drop { }
}
}
}
output {
if [type] in ['success_syslog', 'brute_syslog', 'fail_syslog'] {
elasticsearch {
hosts => ["http://localhost:9200"]
#index => "ssh_login-%{+YYYY.MM.dd}"
index => "%{type}-%{+YYYY.MM.dd}"
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
运行logstash:
bin/logstash -f conf/jx_syslog.conf
ssh 模拟登录
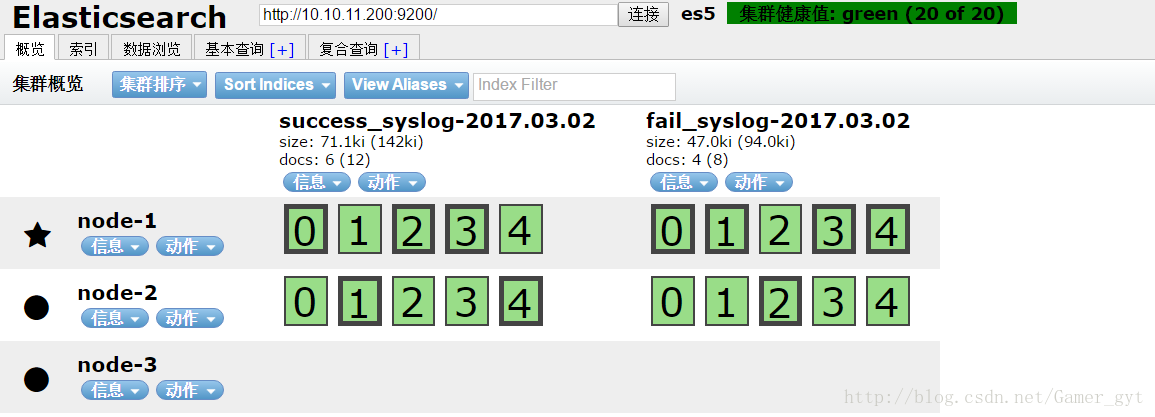
查看es集群
node-1是master结点,node-2是data结点,node-3不存储数据,作为负载均衡使用
踩过的坑
- 1:我是在虚拟机中进行的,由于硬盘内存不足,在es集群正常启动之后,logstash往es集群写数据时不能正常写入
- 2:复制elasticsearch文件夹时,如果原来的es文件夹下存在node数据,那么es集群也不能正常启动
- 3:配置master结点个数,由于我是三台机器,一个master node,一个data node,一个client node,然后设置 discovery.zen.minimum_master_nodes: 2,es集群也不能正常启动,建议这里设置为1
elasticsearch.ymal配置文件说明
上边已经对我配置es集群设置的参数有了简单的说明,但是其实还有许多参数没有设置和说明
修改配置 /etc/elasticsearch/elasticsearch.yml 以下对相关字段以注释方式进行解析.
##################### Elasticsearch Configuration Example #####################
# 我只是挑些重要的配置选项进行注释,其实自带的已经有非常细致的英文注释了.有理解偏差的地方请以英文原版解释为准.
################################### Cluster ###################################
# 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.
# es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
# cluster.name可以确定你的集群名称,当你的elasticsearch集群在同一个网段中elasticsearch会自动的找到具有相同cluster.name的elasticsearch服务.
# 所以当同一个网段具有多个elasticsearch集群时cluster.name就成为同一个集群的标识.
#cluster.name: elasticsearch
#################################### Node #####################################
# 节点名称同理,可自动生成也可手动配置.
#node.name: "Franz Kafka"
# 允许一个节点是否可以成为一个master节点,es是默认集群中的第一台机器为master,如果这台机器停止就会重新选举master.
#node.master: true
# 允许该节点存储数据(默认开启)
#node.data: true
# 配置文件中给出了三种配置高性能集群拓扑结构的模式,如下:
# 1. 如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器
# node.master: false
# node.data: true
#
# 2. 如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
# node.master: true
# node.data: false
#
# 3. 如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等
# node.master: false
# node.data: false
# 监控集群状态有一下插件和API可以使用:
# Use the Cluster Health API [http://localhost:9200/_cluster/health], the
# Node Info API [http://localhost:9200/_nodes] or GUI tools
# such as <http://www.elasticsearch.org/overview/marvel/>,
# <http://github.com/karmi/elasticsearch-paramedic>,
# <http://github.com/lukas-vlcek/bigdesk> and
# <http://mobz.github.com/elasticsearch-head> to inspect the cluster state.
# A node can have generic attributes associated with it, which can later be used
# for customized shard allocation filtering, or allocation awareness. An attribute
# is a simple key value pair, similar to node.key: value, here is an example:
#
#node.rack: rack314
# By default, multiple nodes are allowed to start from the same installation location
# to disable it, set the following:
#node.max_local_storage_nodes: 1
#################################### Index ####################################
# 设置索引的分片数,默认为5
#index.number_of_shards: 5
# 设置索引的副本数,默认为1:
#index.number_of_replicas: 1
# 配置文件中提到的最佳实践是,如果服务器够多,可以将分片提高,尽量将数据平均分布到大集群中去
# 同时,如果增加副本数量可以有效的提高搜索性能
# 需要注意的是,"number_of_shards" 是索引创建后一次生成的,后续不可更改设置
# "number_of_replicas" 是可以通过API去实时修改设置的
#################################### Paths ####################################
# 配置文件存储位置
#path.conf: /path/to/conf
# 数据存储位置(单个目录设置)
#path.data: /path/to/data
# 多个数据存储位置,有利于性能提升
#path.data: /path/to/data1,/path/to/data2
# 临时文件的路径
#path.work: /path/to/work
# 日志文件的路径
#path.logs: /path/to/logs
# 插件安装路径
#path.plugins: /path/to/plugins
#################################### Plugin ###################################
# 设置插件作为启动条件,如果一下插件没有安装,则该节点服务不会启动
#plugin.mandatory: mapper-attachments,lang-groovy
################################### Memory ####################################
# 当JVM开始写入交换空间时(swapping)ElasticSearch性能会低下,你应该保证它不会写入交换空间
# 设置这个属性为true来锁定内存,同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过 `ulimit -l unlimited` 命令
#bootstrap.mlockall: true
# 确保 ES_MIN_MEM 和 ES_MAX_MEM 环境变量设置为相同的值,以及机器有足够的内存分配给Elasticsearch
# 注意:内存也不是越大越好,一般64位机器,最大分配内存别才超过32G
############################## Network And HTTP ###############################
# 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0
#network.bind_host: 192.168.0.1
# 设置其它节点和该节点交互的ip地址,如果不设置它会自动设置,值必须是个真实的ip地址
#network.publish_host: 192.168.0.1
# 同时设置bind_host和publish_host上面两个参数
#network.host: 192.168.0.1
# 设置节点间交互的tcp端口,默认是9300
#transport.tcp.port: 9300
# 设置是否压缩tcp传输时的数据,默认为false,不压缩
#transport.tcp.compress: true
# 设置对外服务的http端口,默认为9200
#http.port: 9200
# 设置请求内容的最大容量,默认100mb
#http.max_content_length: 100mb
# 使用http协议对外提供服务,默认为true,开启
#http.enabled: false
################################### Gateway ###################################
# gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统
#gateway.type: local
# 下面的配置控制怎样以及何时启动一整个集群重启的初始化恢复过程
# (当使用shard gateway时,是为了尽可能的重用local data(本地数据))
# 一个集群中的N个节点启动后,才允许进行恢复处理
#gateway.recover_after_nodes: 1
# 设置初始化恢复过程的超时时间,超时时间从上一个配置中配置的N个节点启动后算起
#gateway.recover_after_time: 5m
# 设置这个集群中期望有多少个节点.一旦这N个节点启动(并且recover_after_nodes也符合),
# 立即开始恢复过程(不等待recover_after_time超时)
#gateway.expected_nodes: 2
############################# Recovery Throttling #############################
# 下面这些配置允许在初始化恢复,副本分配,再平衡,或者添加和删除节点时控制节点间的分片分配
# 设置一个节点的并行恢复数
# 1.初始化数据恢复时,并发恢复线程的个数,默认为4
#cluster.routing.allocation.node_initial_primaries_recoveries: 4
#
# 2.添加删除节点或负载均衡时并发恢复线程的个数,默认为2
#cluster.routing.allocation.node_concurrent_recoveries: 2
# 设置恢复时的吞吐量(例如:100mb,默认为0无限制.如果机器还有其他业务在跑的话还是限制一下的好)
#indices.recovery.max_bytes_per_sec: 20mb
# 设置来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5
#indices.recovery.concurrent_streams: 5
# 注意: 合理的设置以上参数能有效的提高集群节点的数据恢复以及初始化速度
################################## Discovery ##################################
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点.默认为1,对于大的集群来说,可以设置大一点的值(2-4)
#discovery.zen.minimum_master_nodes: 1
# 探查的超时时间,默认3秒,提高一点以应对网络不好的时候,防止脑裂
#discovery.zen.ping.timeout: 3s
# For more information, see
# <http://elasticsearch.org/guide/en/elasticsearch/reference/current/modules-discovery-zen.html>
# 设置是否打开多播发现节点.默认是true.
# 当多播不可用或者集群跨网段的时候集群通信还是用单播吧
#discovery.zen.ping.multicast.enabled: false
# 这是一个集群中的主节点的初始列表,当节点(主节点或者数据节点)启动时使用这个列表进行探测
#discovery.zen.ping.unicast.hosts: ["host1", "host2:port"]
# Slow Log部分与GC log部分略,不过可以通过相关日志优化搜索查询速度
############## Memory(重点需要调优的部分) ################
# Cache部分:
# es有很多种方式来缓存其内部与索引有关的数据.其中包括filter cache
# filter cache部分:
# filter cache是用来缓存filters的结果的.默认的cache type是node type.node type的机制是所有的索引内部的分片共享filter cache.node type采用的方式是LRU方式.即:当缓存达到了某个临界值之后,es会将最近没有使用的数据清除出filter cache.使让新的数据进入es.
# 这个临界值的设置方法如下:indices.cache.filter.size 值类型:eg.:512mb 20%。默认的值是10%。
# out of memory错误避免过于频繁的查询时集群假死
# 1.设置es的缓存类型为Soft Reference,它的主要特点是据有较强的引用功能.只有当内存不够的时候,才进行回收这类内存,因此在内存足够的时候,它们通常不被回收.另外,这些引用对象还能保证在Java抛出OutOfMemory异常之前,被设置为null.它可以用于实现一些常用图片的缓存,实现Cache的功能,保证最大限度的使用内存而不引起OutOfMemory.在es的配置文件加上index.cache.field.type: soft即可.
# 2.设置es最大缓存数据条数和缓存失效时间,通过设置index.cache.field.max_size: 50000来把缓存field的最大值设置为50000,设置index.cache.field.expire: 10m把过期时间设置成10分钟.
#index.cache.field.max_size: 50000
#index.cache.field.expire: 10m
#index.cache.field.type: soft
# field data部分&&circuit breaker部分:
# 用于field data 缓存的内存数量,主要用于当使用排序,faceting操作时,elasticsearch会将一些热点数据加载到内存中来提供给客户端访问,但是这种缓存是比较珍贵的,所以对它进行合理的设置.
# 可以使用值:eg:50mb 或者 30%(节点 node heap内存量),默认是:unbounded
#indices.fielddata.cache.size: unbounded
# field的超时时间.默认是-1,可以设置的值类型: 5m
#indices.fielddata.cache.expire: -1
# circuit breaker部分:
# 断路器是elasticsearch为了防止内存溢出的一种操作,每一种circuit breaker都可以指定一个内存界限触发此操作,这种circuit breaker的设定有一个最高级别的设定:indices.breaker.total.limit 默认值是JVM heap的70%.当内存达到这个数量的时候会触发内存回收
# 另外还有两组子设置:
#indices.breaker.fielddata.limit:当系统发现fielddata的数量达到一定数量时会触发内存回收.默认值是JVM heap的70%
#indices.breaker.fielddata.overhead:在系统要加载fielddata时会进行预先估计,当系统发现要加载进内存的值超过limit * overhead时会进行进行内存回收.默认是1.03
#indices.breaker.request.limit:这种断路器是elasticsearch为了防止OOM(内存溢出),在每次请求数据时设定了一个固定的内存数量.默认值是40%
#indices.breaker.request.overhead:同上,也是elasticsearch在发送请求时设定的一个预估系数,用来防止内存溢出.默认值是1
# Translog部分:
# 每一个分片(shard)都有一个transaction log或者是与它有关的预写日志,(write log),在es进行索引(index)或者删除(delete)操作时会将没有提交的数据记录在translog之中,当进行flush 操作的时候会将tranlog中的数据发送给Lucene进行相关的操作.一次flush操作的发生基于如下的几个配置
#index.translog.flush_threshold_ops:当发生多少次操作时进行一次flush.默认是 unlimited
#index.translog.flush_threshold_size:当translog的大小达到此值时会进行一次flush操作.默认是512mb
#index.translog.flush_threshold_period:在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作.默认是30m
#index.translog.interval:多少时间间隔内会检查一次translog,来进行一次flush操作.es会随机的在这个值到这个值的2倍大小之间进行一次操作,默认是5s
#index.gateway.local.sync:多少时间进行一次的写磁盘操作,默认是5s
# 以上的translog配置都可以通过API进行动态的设置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
如何动态的加入结点
上边我们已经部署了三个结点的es集群,加入现在我们要另外加入一个data node,我们该怎么办?
1:copy 一个elasticsearch文件夹,作为第四个结点
sudo cp -r elasticsearch-5.2.1_2 elasticsearch-5.2.1_4
2:修改es4 中的yaml文件
cluster.name: es5
node.name: node-4
network.host: 0.0.0.0
http.port: 9203
transport.tcp.port: 9303
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302", "0.0.0.0:9302"]
discovery.zen.minimum_master_nodes: 1
gateway.recover_after_nodes: 2
gateway.recover_after_time: 5m
gateway.expected_nodes: 1
script.engine.groovy.inline.search: on
script.engine.groovy.inline.aggs: on
indices.recovery.max_bytes_per_sec: 20mb
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3:修改另外三个结点的yaml文件
修改discovery.zen.ping.unicast.hosts: 配置项为:
discovery.zen.ping.unicast.hosts: ["0.0.0.0:9300", "0.0.0.0:9301", "0.0.0.0:9302", "0.0.0.0:9302"]
- 1
4:重启es集群
前三个结点启动完毕,启动第四个结点时报错如下:
Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x000000008a660000, 1973026816, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 1973026816 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /tmp/hs_err_pid9963.log
- 1
- 2
- 3
- 4
- 5
- 6
这个错误的意思是JVM运行内存不足,解决办法是增加虚拟机内存,同时删除es4目录下data目录下的数据
然后重启elasticsearch集群,重启logstash:
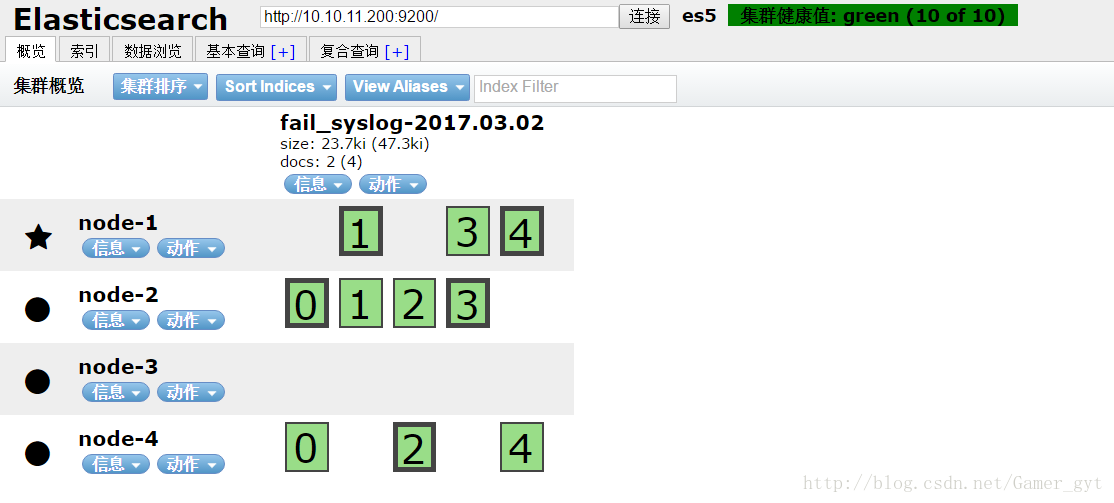
欧了,到这里灵活的添加结点我们也完成了
ES集群的监控
网上查看资料相应的插件有
bigdesk:https://github.com/hlstudio/bigdesk
paramedic:https://github.com/karmi/elasticsearch-paramedic
kopf:https://github.com/lmenezes/elasticsearch-kopf
- 1
- 2
- 3
由于大部分插件只支持es2.x,所以这里采用bigdesk
1:下载
git clone https://github.com/hlstudio/bigdesk.git
- 1
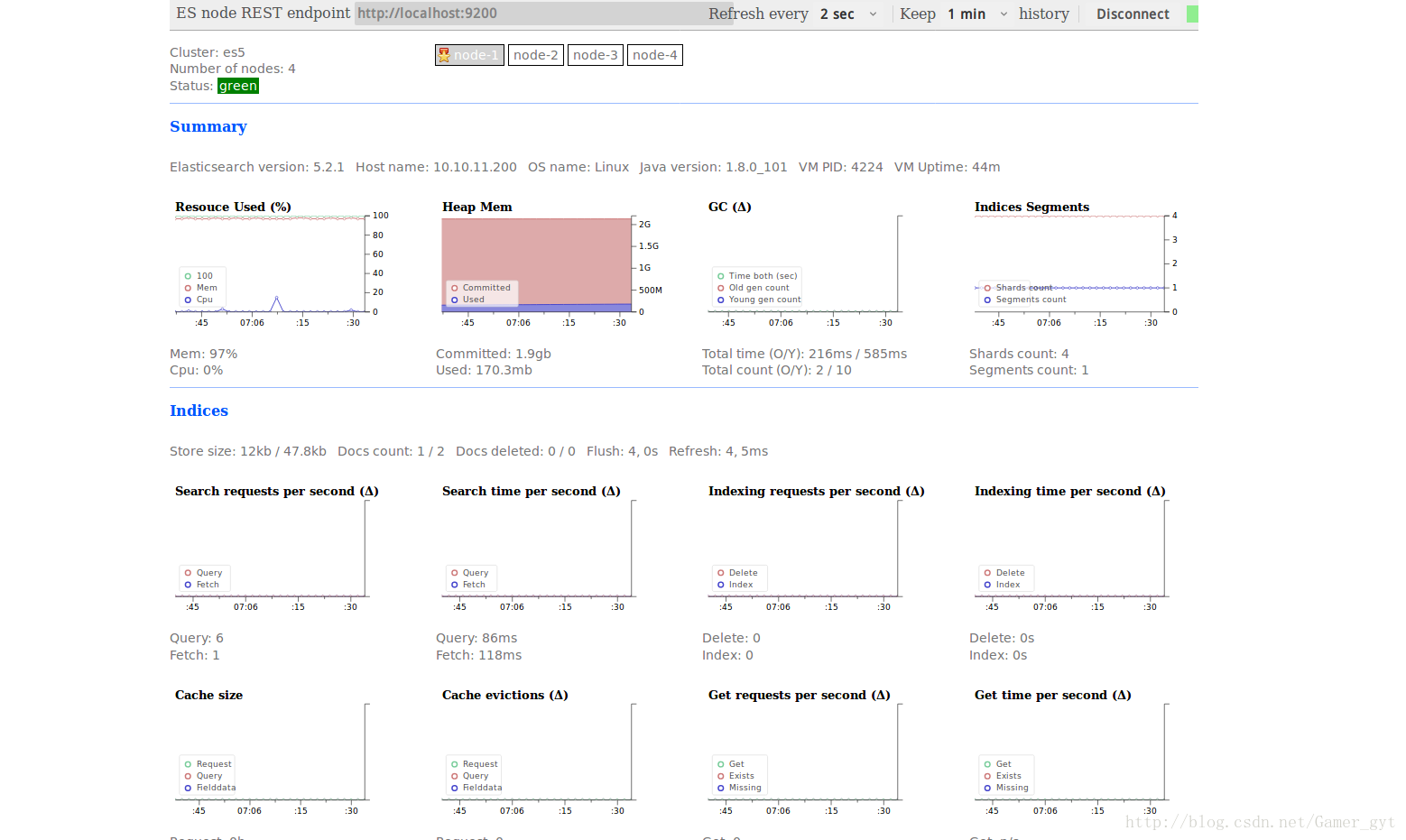
2:进入该目录,在浏览器中打开index.html
效果图如下,可以进行刷新时间设置,查看不同结点情况
结束
吾之初心,永世不忘
“请问祖安怎么走?” “顺着这条金属小道,一直走就是了。” “请问诺克萨斯怎么走?” “沿着这条沾满鲜血的道路,一直走就是了。” “请问德玛西亚怎么走?” “德玛西亚,没有走的方法,德玛西亚就在你心里,如果你有一颗德玛西亚人的心,有草丛的地方,就是德玛西亚了。”