1、索引样例数据
下载样例数据集链接 下载后解压到ES的bin目录,然后加载到elasticsearch集群

curl -XPOST 127.0.0.1:9200/bank/account/_bulk?pretty --data-binary @accounts.json
如果accounts.json文件和bin目录并列:curl -XPOST 127.0.0.1:9200/bank/account/_bulk?pretty --data-binary @..accounts.json

查看索引:curl localhost:9200/_cat/indices?v
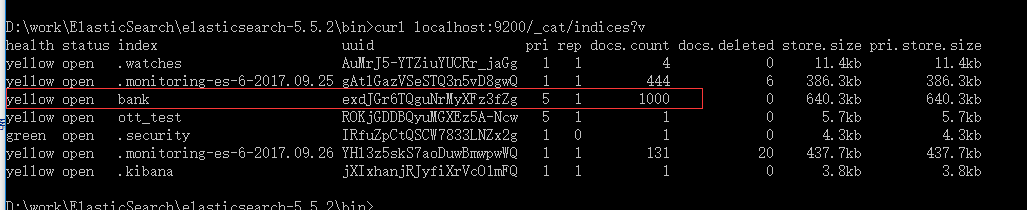
上面结果,说明我们成功bulk 1000个文档到bank索引中了
删除索引bank:curl -XDELETE http://127.0.0.1:9200/bank
2、搜索数据API
有两种方式:一种方式是通过 REST 请求 URI ,发送搜索参数;另一种是通过REST 请求体,发送搜索参数。而请求体允许你包含更容易表达和可阅读的JSON格式。
2.1、通过 REST 请求 URI
curl localhost:9200/bank/_search?pretty
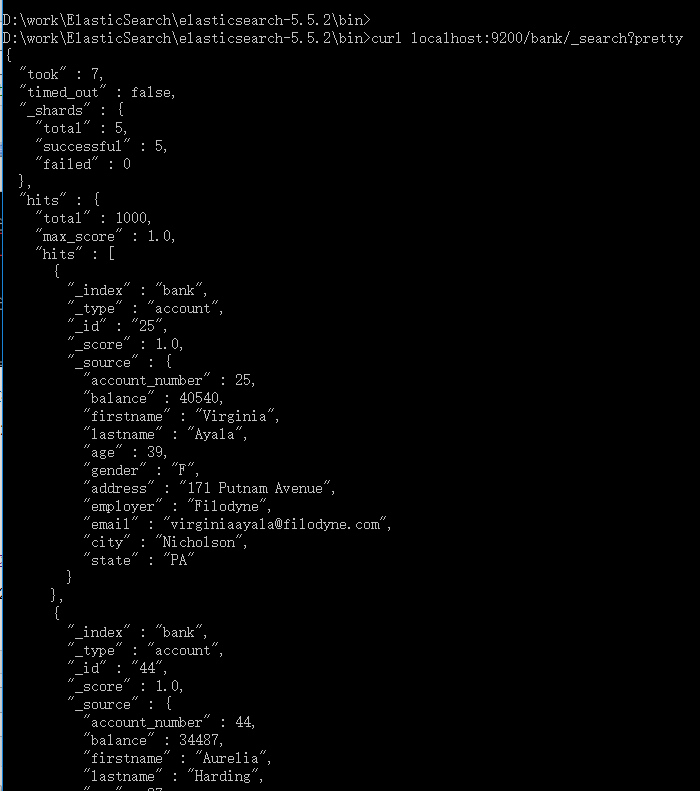
pretty,参数告诉elasticsearch,返回形式打印JSON结果
2.2、通过REST 请求体
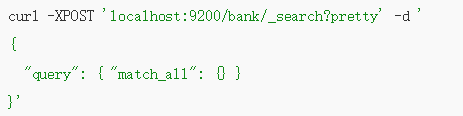
curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_all": {} }}"
query:告诉我们定义查询
match_all:运行简单类型查询指定索引中的所有文档

除了指定查询参数,还可以指定其他参数来影响最终的结果。
2.3、match_all & 只返回前两个文档:

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_all": {} }, "size" : 2}"

如果不指定size,默认是返回10条文档信息
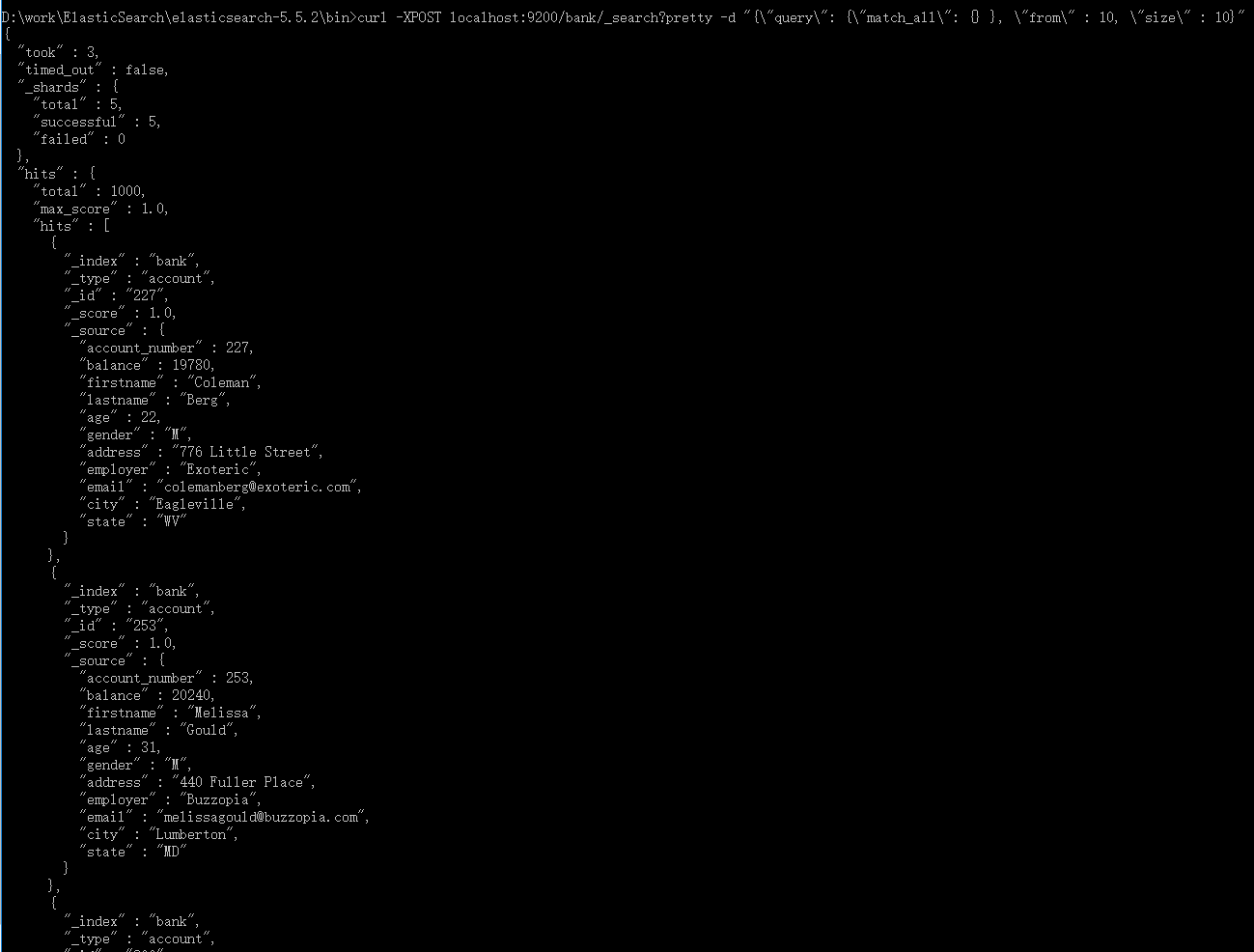
2.4、match_all & 返回第11到第20的10个文档信息

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_all": {} }, "from" : 10, "size" : 10}"
from:指定文档索引从哪里开始,默认从0开始
size:从from开始,返回多个文档
这feature在实现分页查询很有用
2.5、match_all and 根据account 的balance字段 降序排序 & 返回10个文档(默认10个)
curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_all": {} }, "sort" : {"balance" : {"order" : "desc" }}}"
2.6、比如只返回account_number 和balance两个字段
默认的,我们搜索返回完整的JSON文档。而source(_source字段搜索点击量)。如果我们不想返回完整的JSON文档,我们可以使用source返回指定字段。
比如只返回account_number 和balance两个字段

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_all": {} }, "_source": ["account_number", "balance"]}"
match 查询,可作为基本字段搜索查询
2.7、返回 account_number=20:

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match": {"account_number": 20 } }}"

2.8、返回 address=mill:

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match": {"address": "mill" } }}"
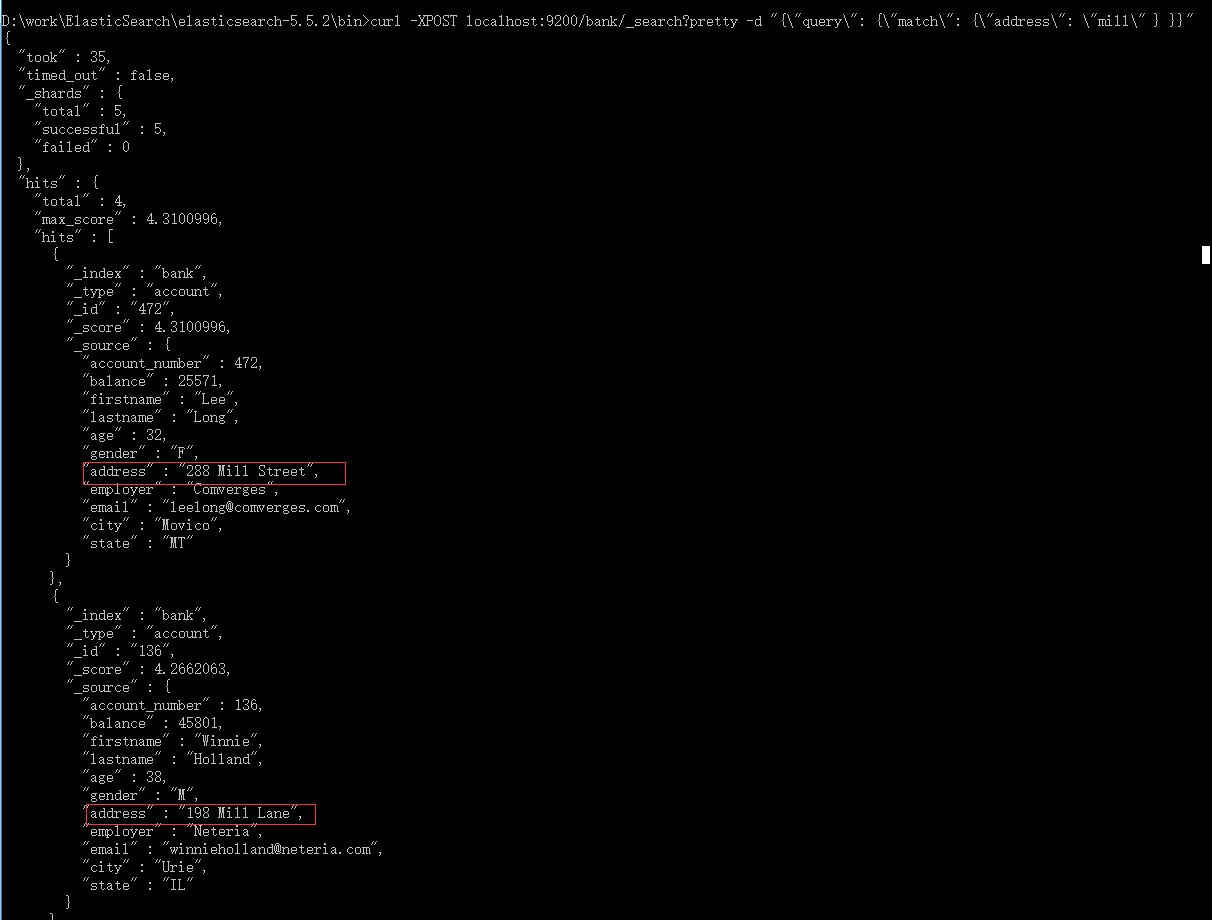
2.9、返回 address=mill or address=lane:

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match": {"address": "mill lane" } }}"
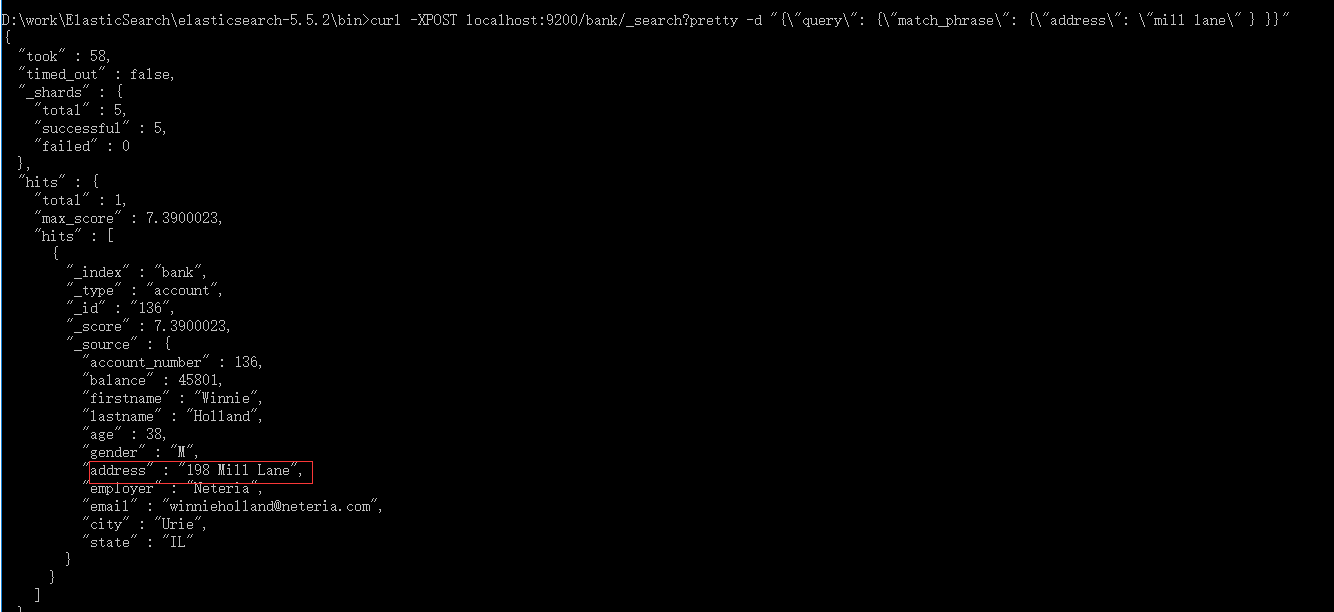
2.10、返回 短语匹配 address=mill lane:
curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"match_phrase": {"address": "mill lane" } }}"
2.11、布尔值(bool)查询
返回 匹配address=mill & address=lane:

must:要求所有条件都要满足(类似于&&)
curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"bool": {"must": [{"match": {"address": "mill" }},{"match": {"address": "lane" }}]}}}"
2.12、返回 匹配address=mill or address=lane

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"bool": {"should": [{"match": {"address": "mill" }},{"match": {"address": "lane" }}]}}}"
should:任何一个满足就可以(类似于||)
2.13、返回 不匹配address=mill & address=lane

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"bool": {"must_not": [{"match": {"address": "mill" }},{"match": {"address": "lane" }}]}}}"
must_not:所有条件都不能满足(类似于! (&&))
2.14、返回 age=40 & state!=ID

curl -XPOST localhost:9200/bank/_search?pretty -d "{"query": {"bool": {"must": [{"match": {"address": "mill" }}],"must_not": [{"match": {"state": "ID" }}]}}}"
3、执行过滤器
文档中score(_score字段是搜索结果)。score是一个数字型的,是一种相对方法匹配查询文档结果。分数越高,搜索关键字与该文档相关性越高;越低,搜索关键字与该文档相关性越低。
在elasticsearch中所有的搜索都会触发相关性分数计算。如果我们不使用相关性分数计算,那要使用另一种查询能力,构建过滤器。
过滤器是类似于查询的概念,除了得以优化,更快的执行速度的两个主要原因:
1、过滤器不计算得分,所以他们比执行查询的速度
2、过滤器可缓存在内存中,允许重复搜索
为了便于理解过滤器,先介绍过滤器搜索(like match_all, match, bool, etc.),可以与其他的普通查询搜索组合一个过滤器。
range filter,允许我们通过一个范围值来过滤文档,一般用于数字或日期过滤
使用过滤器搜索返回 balances[ 20000,30000]。换句话说,balance>=20000 && balance<=30000

POST /bank/_search?pretty { "query": { "bool": { "must": { "match": { "age": 39 }}, "must_not": { "match": { "employer":"Digitalus" }}, "filter": { "range": { "balance": { "gte": 20000, "lte": 30000 } } } } } }
3、执行聚合
聚合提供从你的数据中分组和提取统计能力, 类似于关系型数据中的SQL GROUP BY和SQL 聚合函数。
在Elasticsearch中,你有能力执行搜索返回命中结果,同时拆分命中结果,然后统一返回结果。当你使用简单的API运行搜索和多个聚合,然后返回所有结果避免网络带宽过大的情况是高效的。