1.通过spark-submit脚本提交spark程序
在spark-submit脚本里面执行了SparkSubmit类的main方法

2.运行SparkSubmit类的main方法

3.调用doSubmit方法
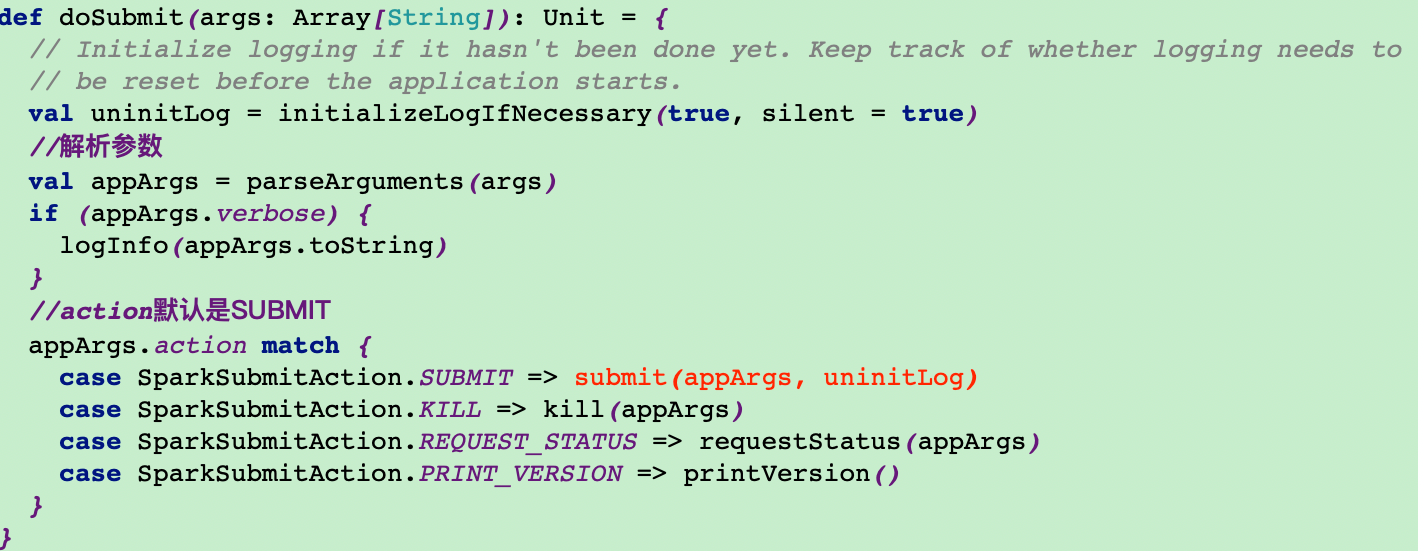
4.调用submit方法
在submit方法里调用doRunMain方法,最终调用runMain方法
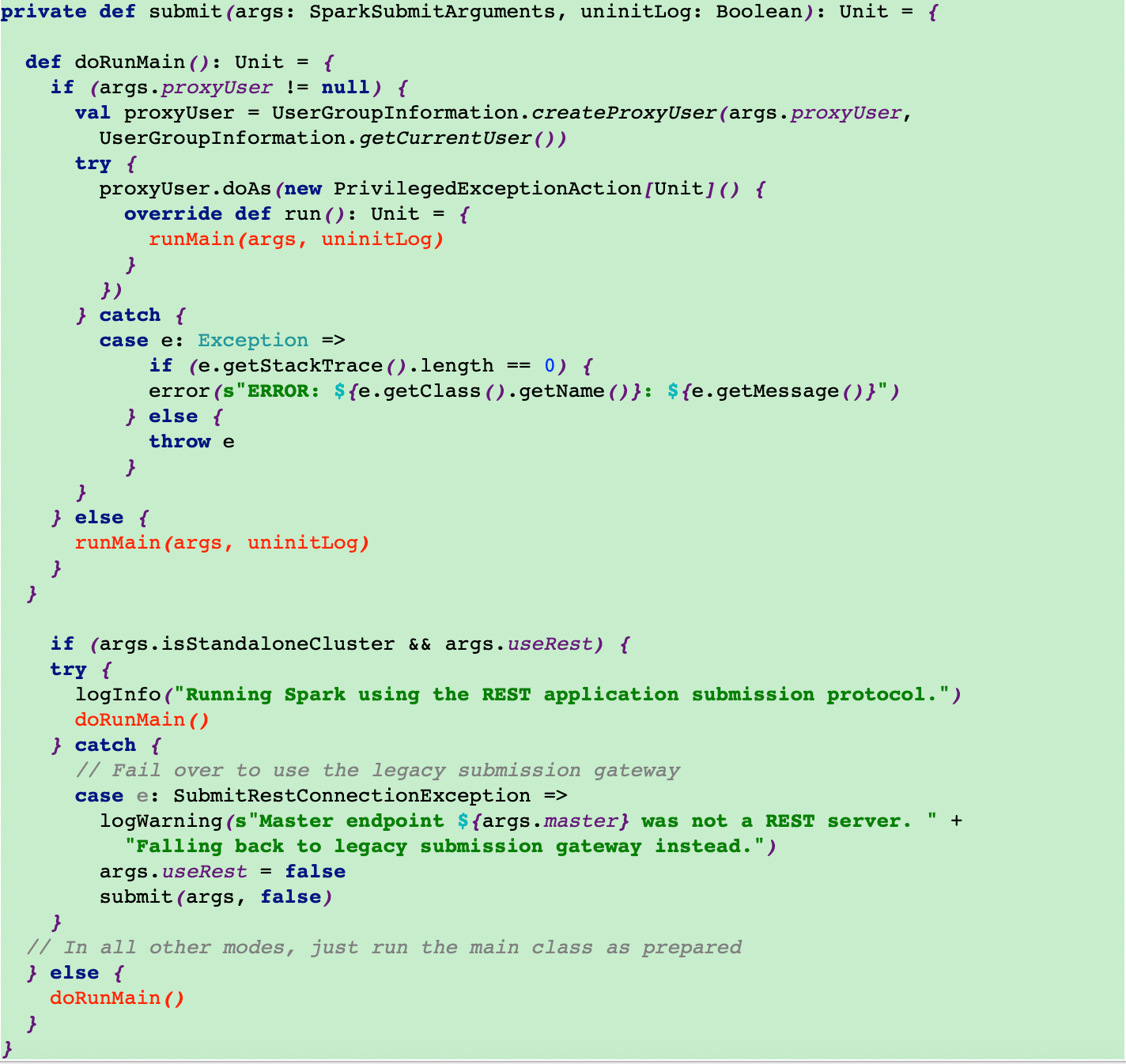
5.在runMain方法里面获取mainClass,再去执行start方法

在这里根据提交模式来选择mainClass
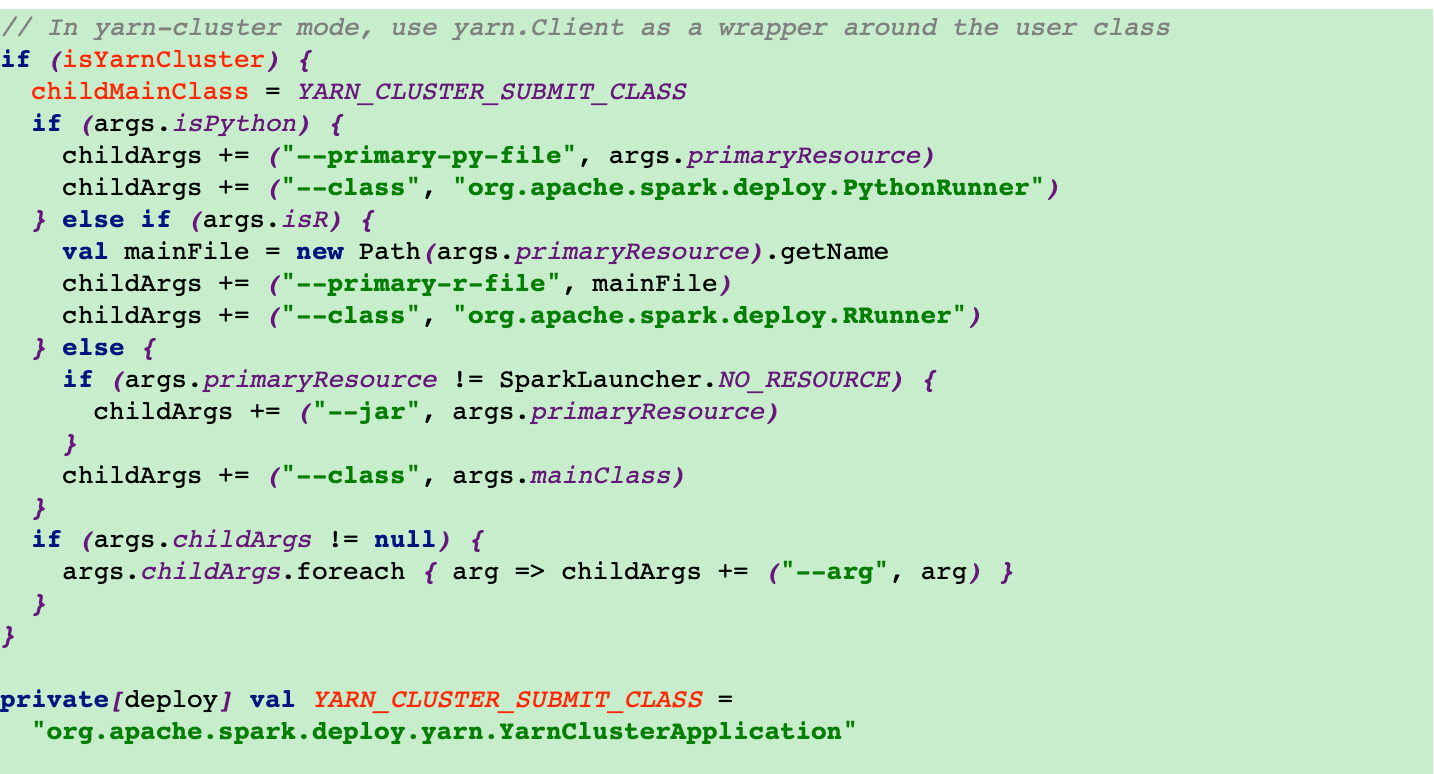
6.在start方法里面去调用YarnClusterApplication的start方法

7.YarnClusterApplication方法里面new一个yarnClient对象,并执行run方法

8.run方法里执行submitApplication提交application

9.submitApplication方法里首先会去请求RM并返回一个appId,然后创建container和application上下文环境并执行submitApplication提交application

这里通过createContainerLaunchContext方法启动了ApplicationMaster

10.调用ApplicationMaster类的main方法
在这里首先new一个ApplicationMaster,然后调用了master的run方法
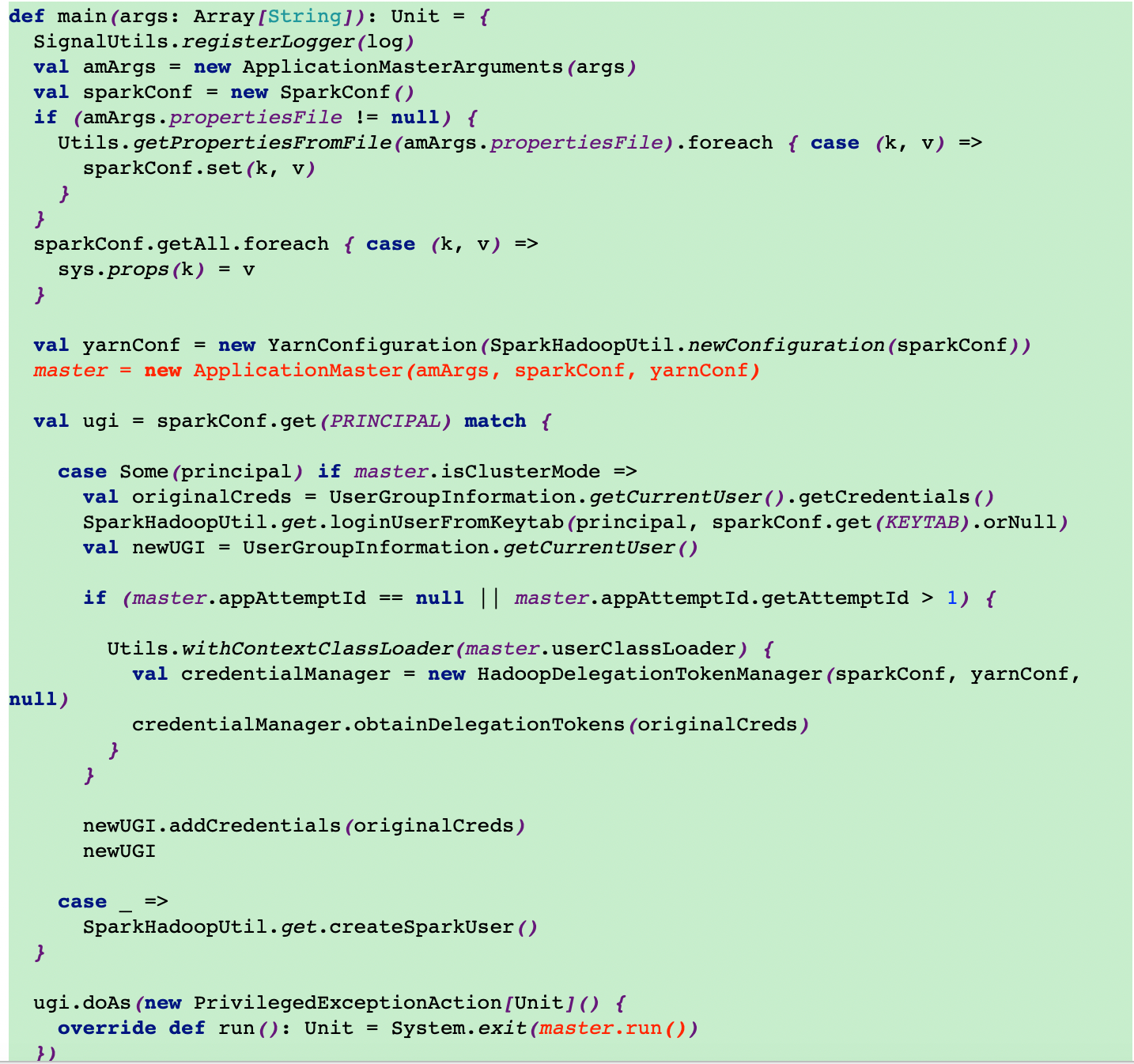
11.调用ApplicationMaster的run方法
这里会根据是否是集群模式执行不同的方法
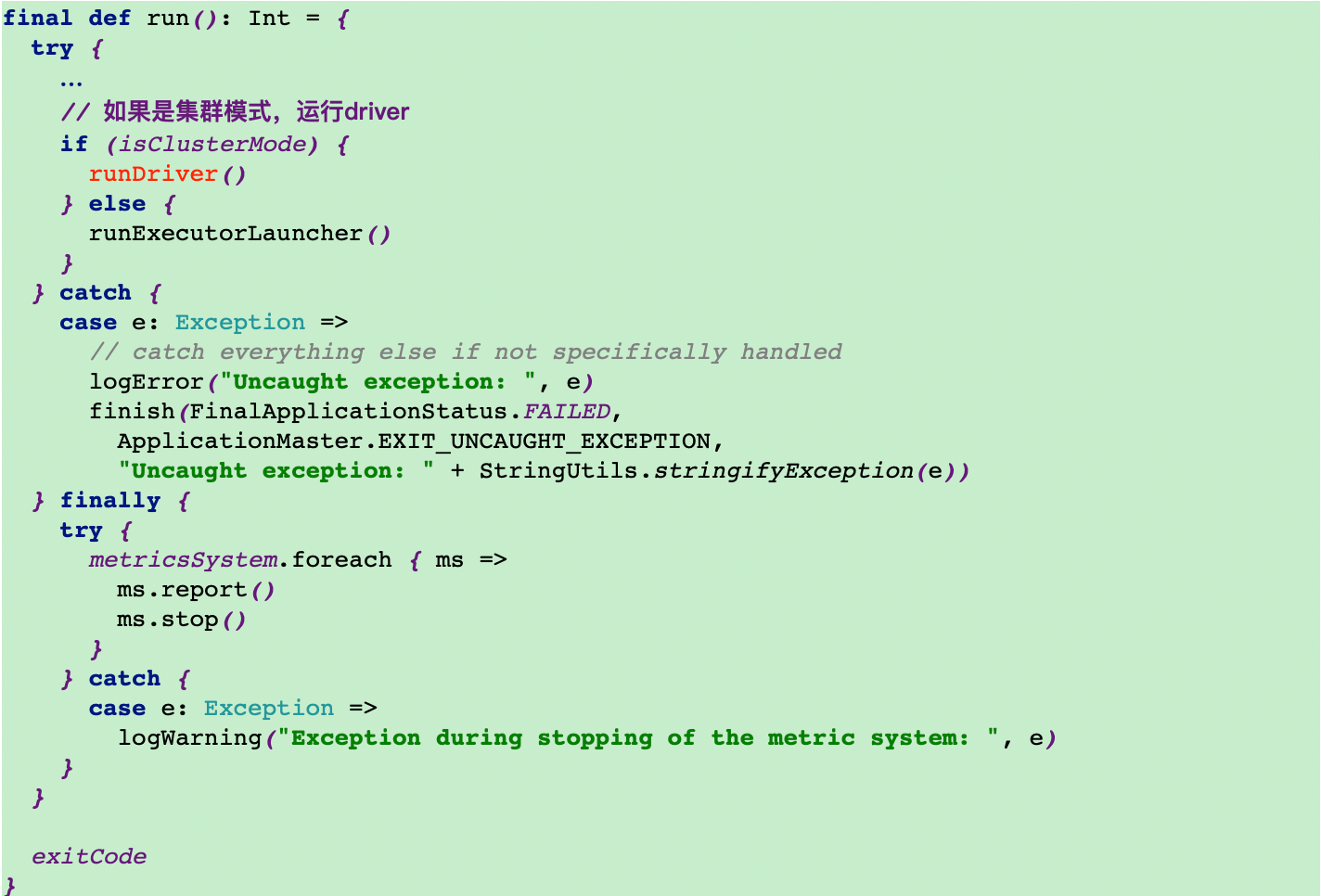
12.调用runDriver方法
12.1调用startUserApplication方法启动一个driver线程
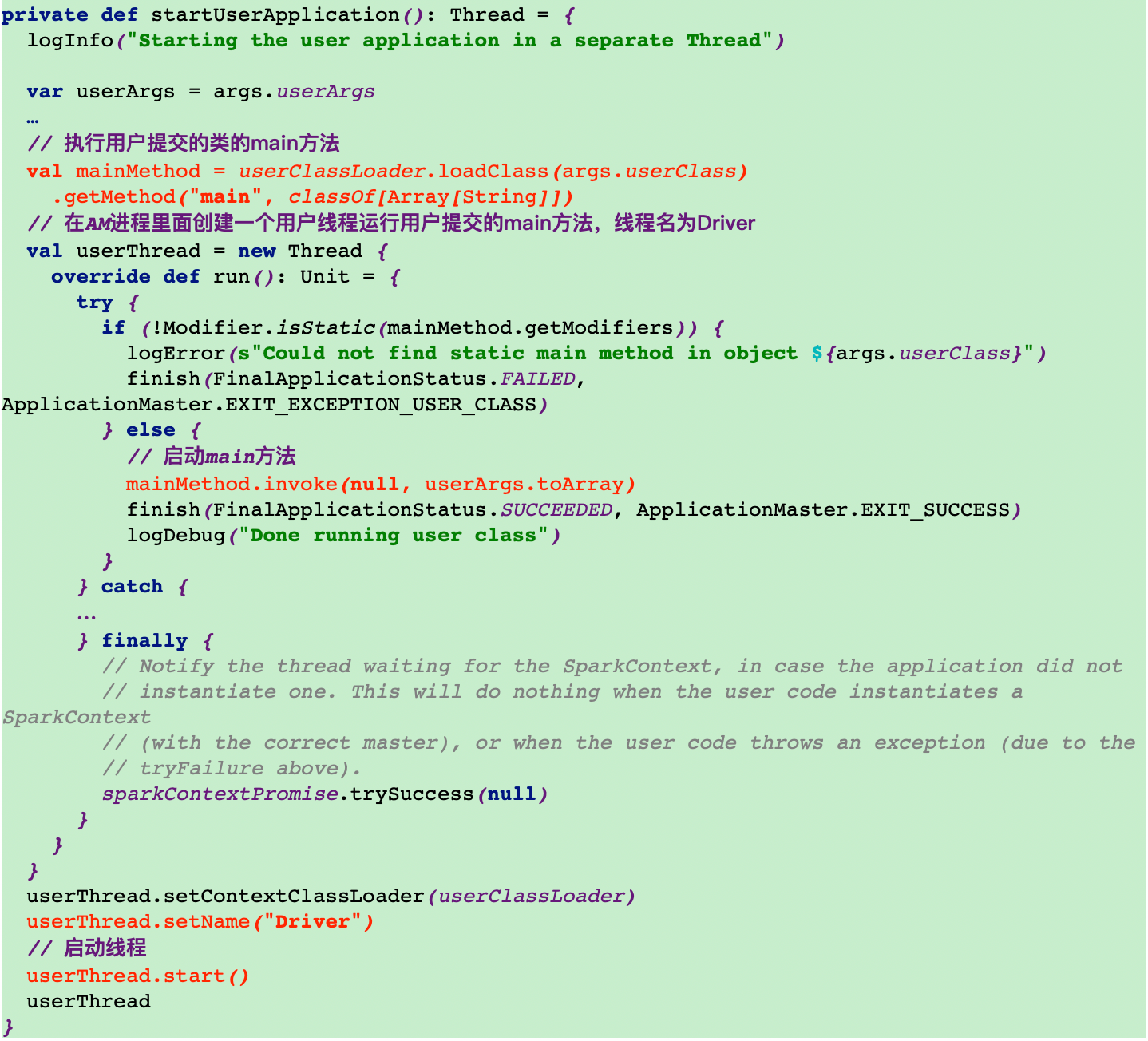
12.2将AM注册到RM
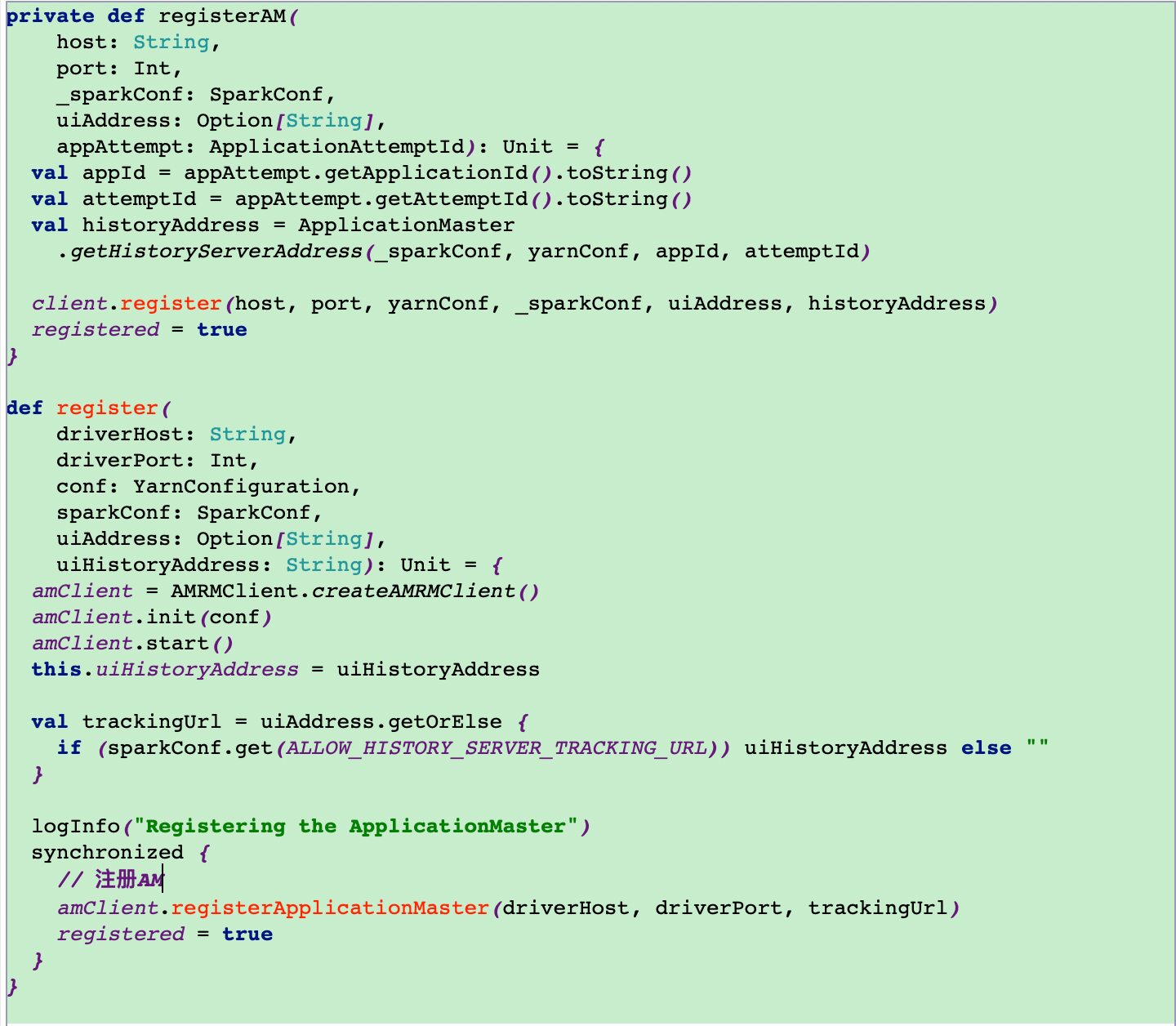
12.3分配资源


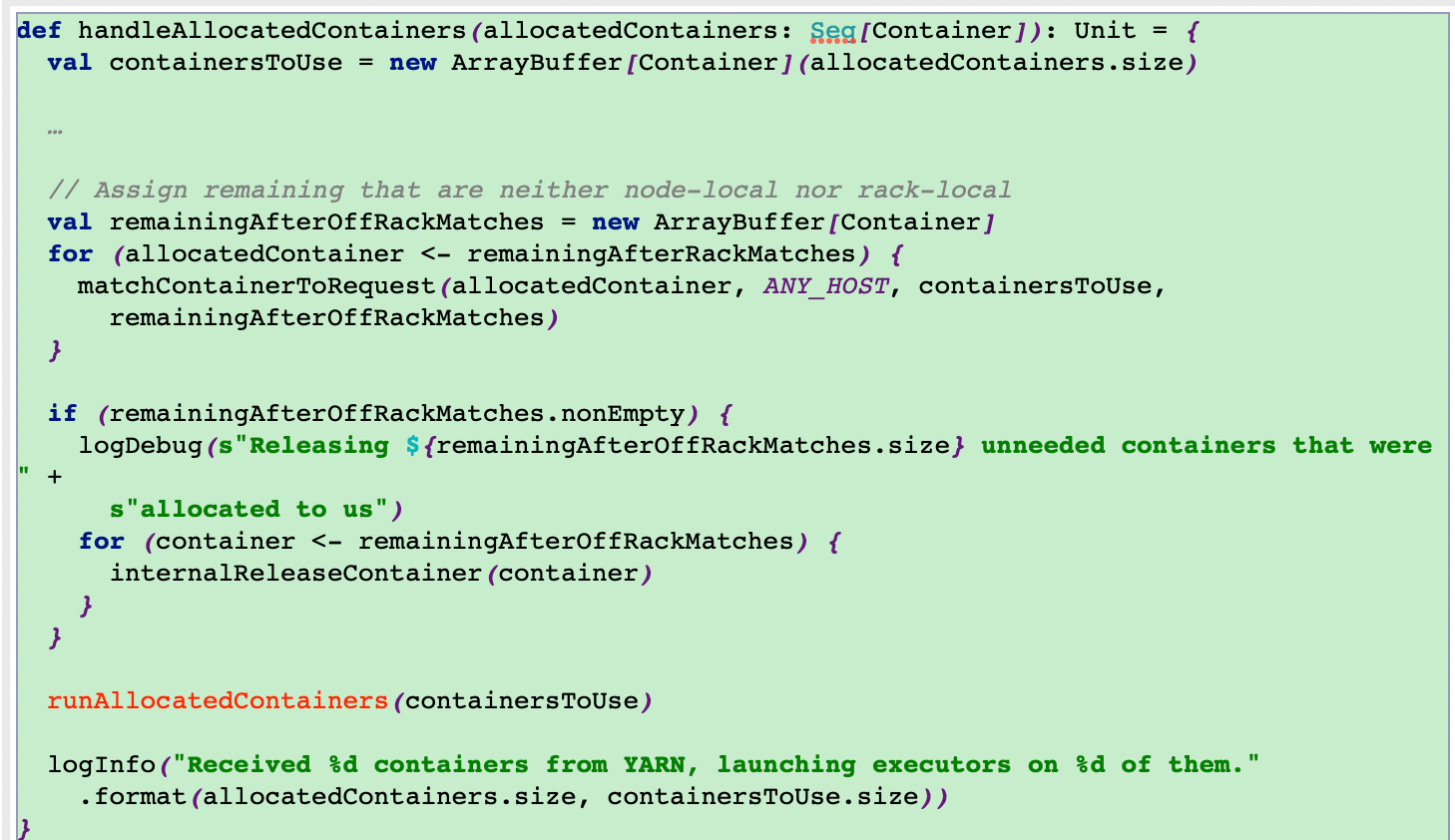
这里通过调用runAllocatedContainers方法在分配的container里面运行executors

12.4调用ExecutorRunnable的run方法,然后调用run方法里面的startContainer方法来启动executor

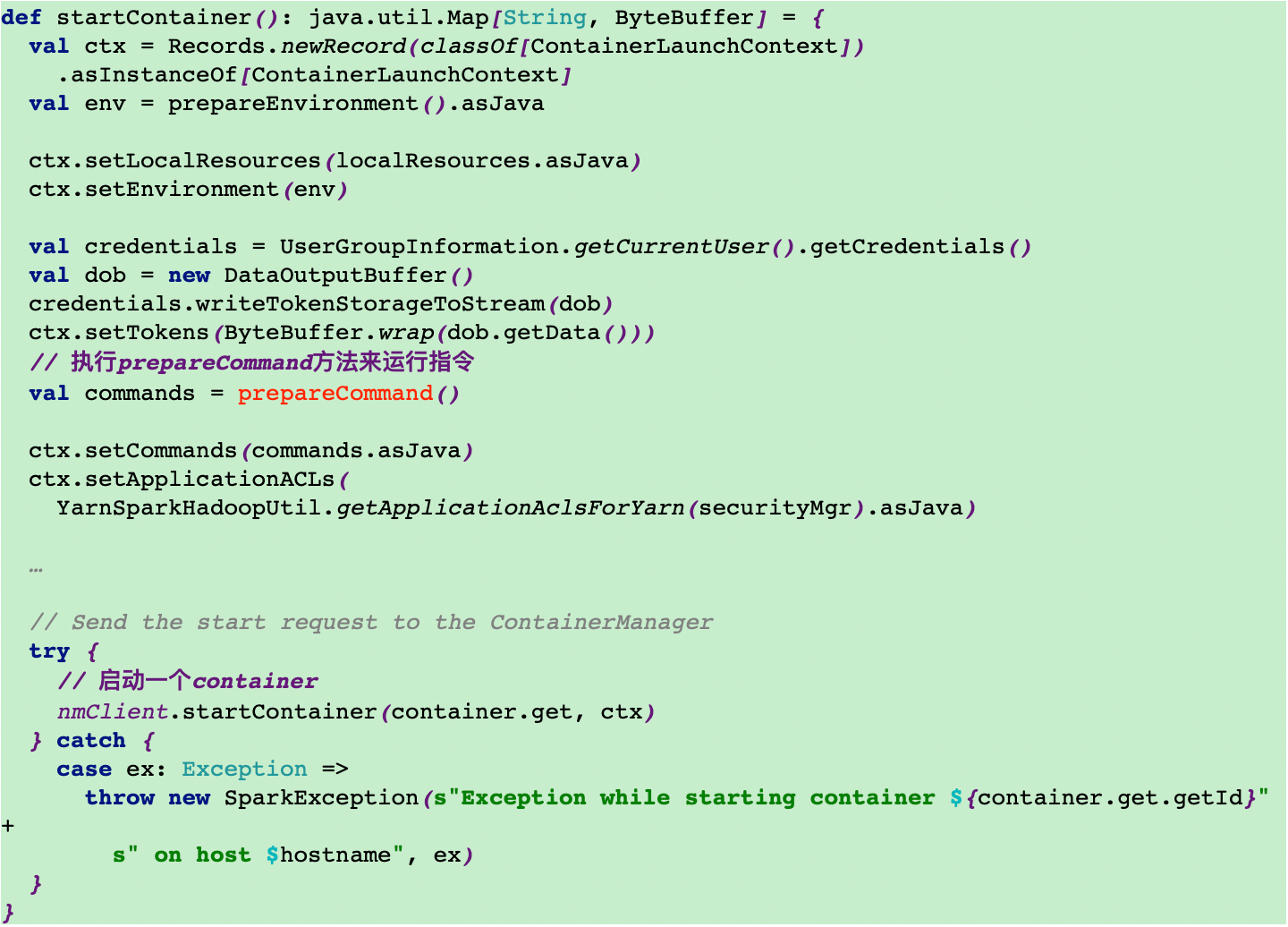
12.5调用prepareCommand方法来运行org.apache.spark.executor.YarnCoarseGrainedExecutorBackend类
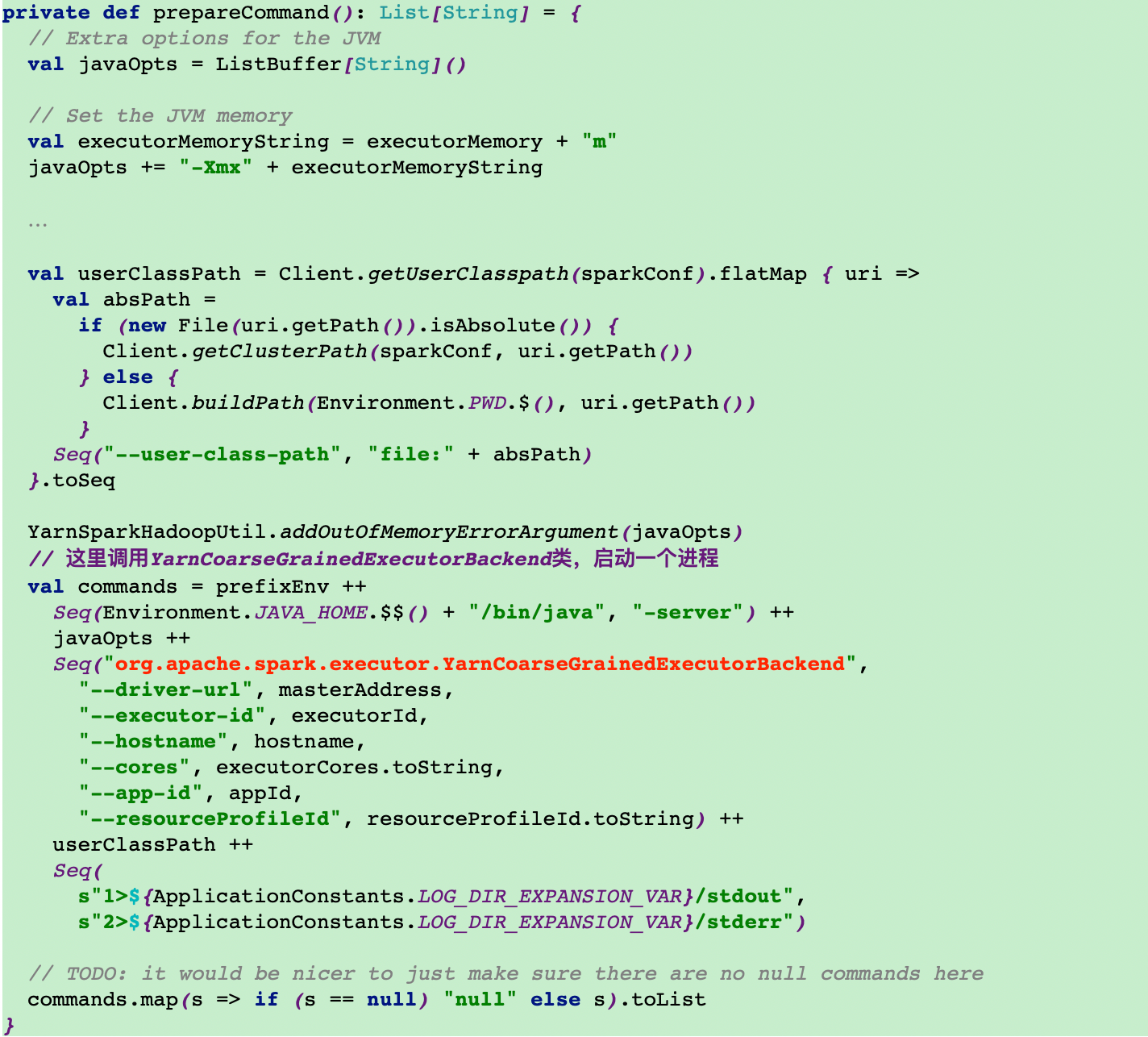
13.执行YarnCoarseGrainedExecutorBackend类main方法的run方法创建executor终端

14.调用setupEndpoint创建executor终端
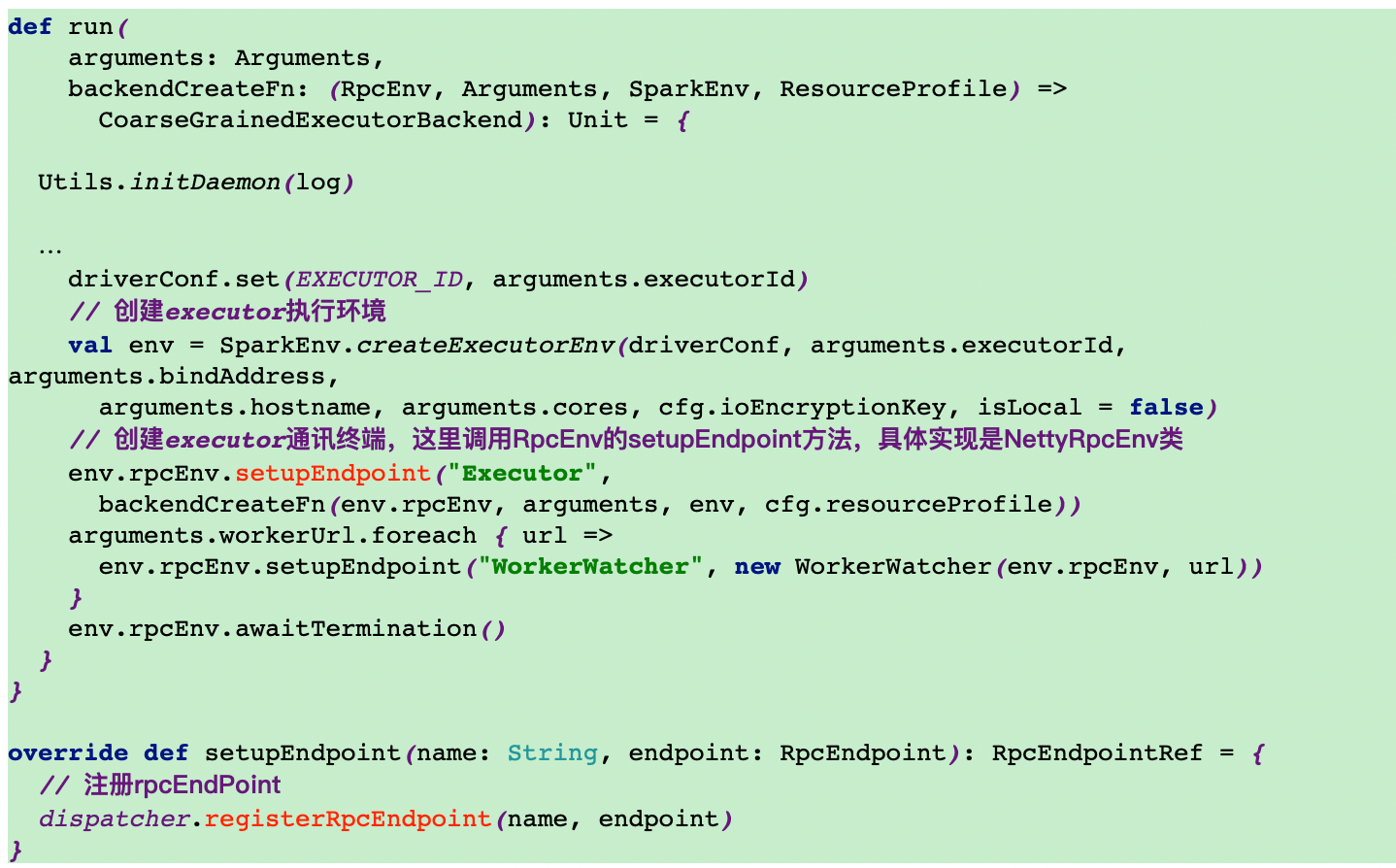
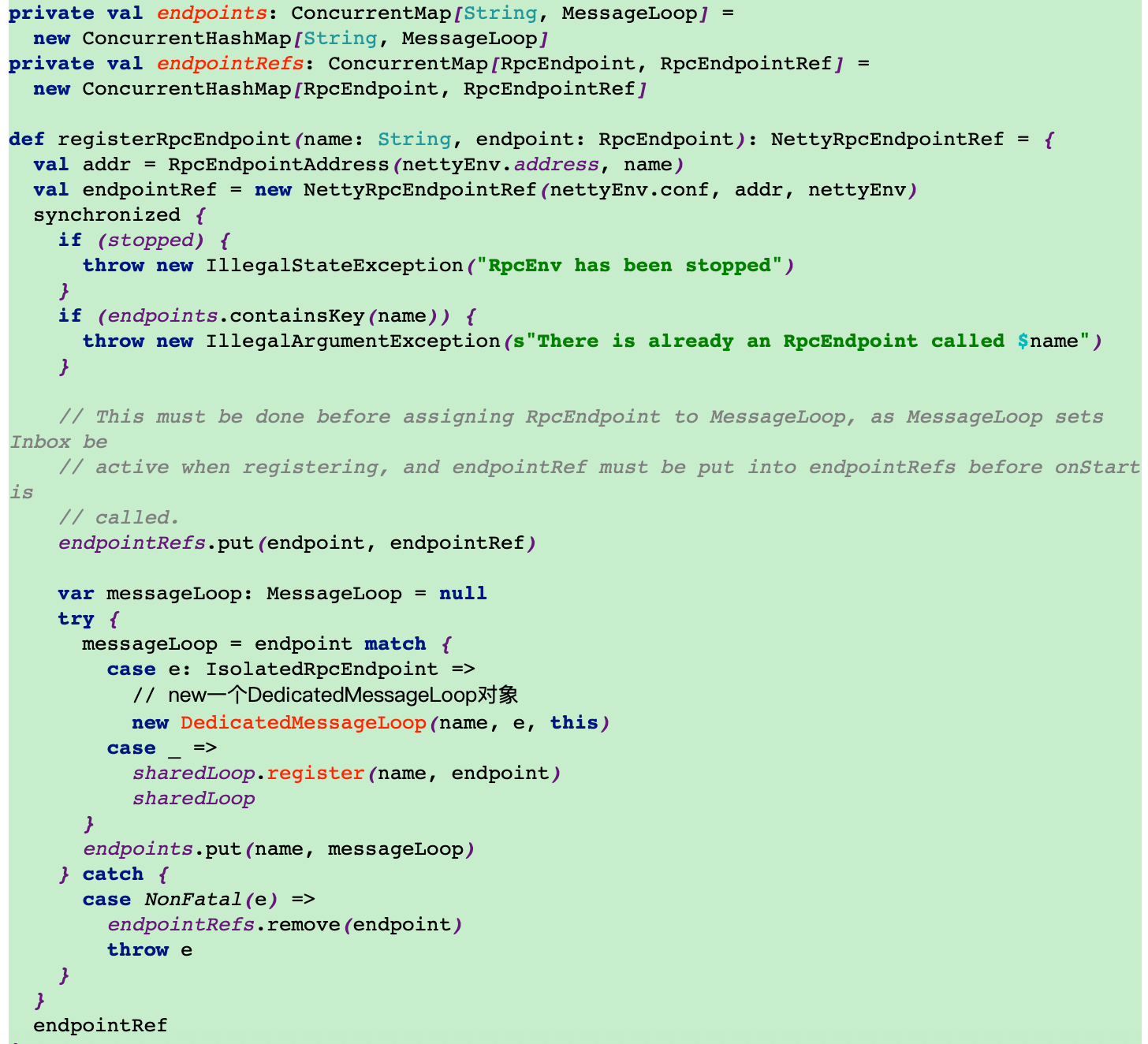
15.反向注册executor到driver

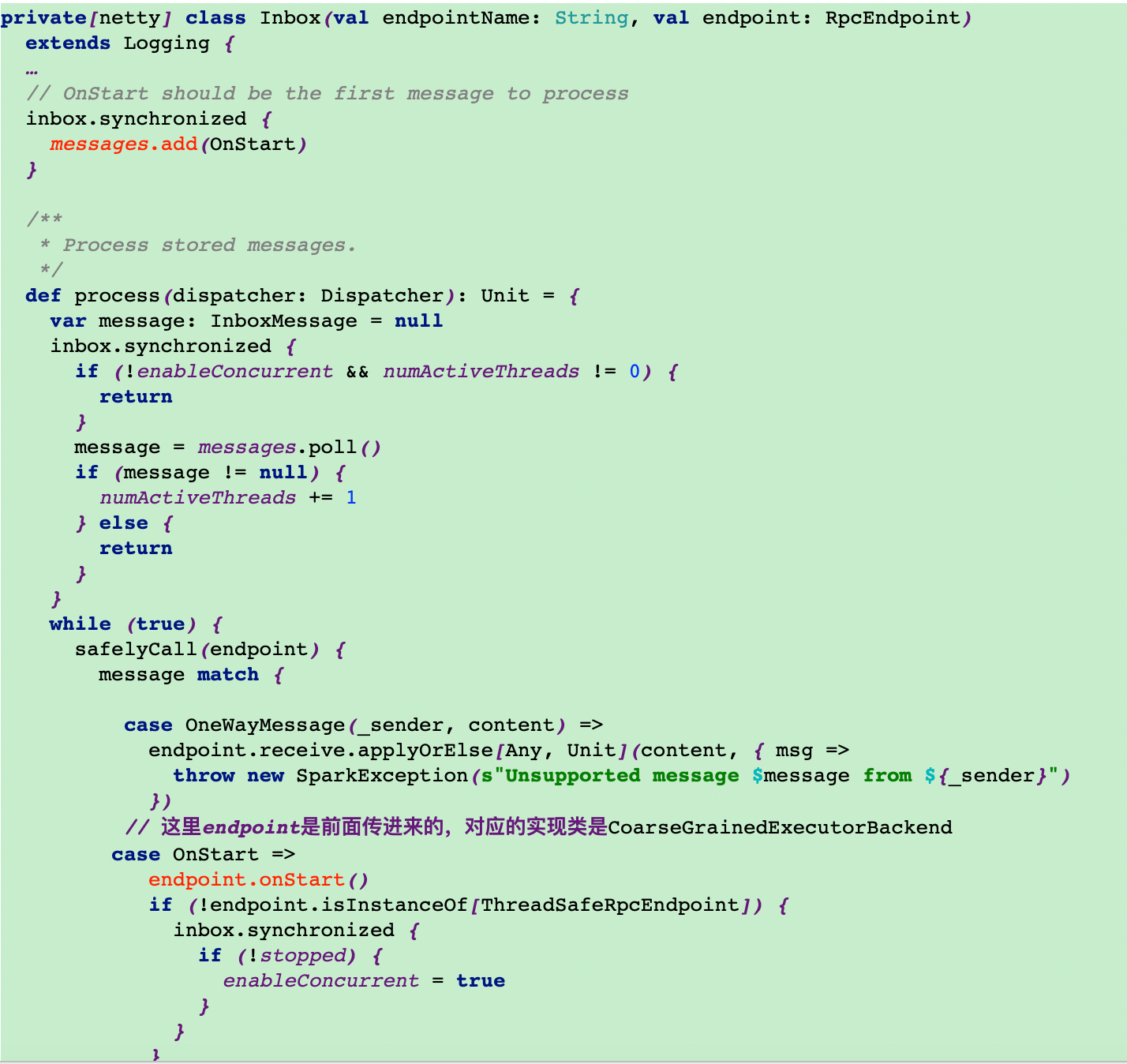

16.driver端接收
在SparkContext中有SchedulerBackend,它是一个特质,具体实现类为CoarseGrainedSchedulerBackend,该类中有一个receiveAndReply方法来对executor的注册做回复
