思路:
①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1、s2
②分别配置三台主机环境变量,并使用source命令使之立即生效
主机映射信息如下:
192.168.32.100 s0
192.168.32.101 s1
192.168.32.102 s2
搭建目标:
s0 : Master
s1 : Worker
s2 : Worker
1、准备
Hadoop 版本:2.7.7
Scala版本:2.12.8
Spark版本:2.4.3
2、安装Hadoop
下载地址:
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
Hadoop 安装步骤参考(示例版本与HDFS端口配置略有差异,根据实际情况调整):
https://www.cnblogs.com/jonban/p/hadoop.html
3、安装Scala
下载地址:
https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz
解压到 /opt 下
tar -zxvf scala-2.12.8.tgz -C /opt/
环境变量可暂时不配置,等到全部配置完成后统一配置环境变量,并使之生效。
配置环境变量,追加如下内容:
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
可用追加命令,如下所示:
echo -e '
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
' >> /etc/profile
使用source命令使配置立即生效
source /etc/profile
4、安装Spark
Spark下载地址:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
也可到官网下载其它版本,下载页面地址如下:
http://spark.apache.org/downloads.html
解压到 /opt 下
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz -C /opt/
5、修改配置文件
进入配置文件目录
cd /opt/spark-2.4.3-bin-hadoop2.7/conf
配置 log4j.properties
mv log4j.properties.template log4j.properties
配置 slaves
mv slaves.template slaves
内容如下:
s1
s2
配置 spark-env.sh
cp spark-env.sh.template spark-env.sh
在 spark-env.sh 中添加如下内容(以下为本机示例,配置路径根据实际情况调整):
export JAVA_HOME=/opt/jdk1.8.0_192
export SCALA_HOME=/opt/scala-2.12.8
export HADOOP_HOME=/opt/hadoop-2.7.7
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=s0
export SPARK_MASTER_HOST=s0
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-2.7.7/bin/hadoop classpath)
6、远程复制Scala 安装目录到其它两台主机s1、s2
scp -r /opt/scala-2.12.8 root@s1:/opt/
scp -r /opt/scala-2.12.8 root@s2:/opt/
7、远程复制Spark 安装目录到其它两台主机s1、s2
scp -r /opt/spark-2.4.3-bin-hadoop2.7 root@s1:/opt/
scp -r /opt/spark-2.4.3-bin-hadoop2.7 root@s2:/opt/
8、配置三台主机环境变量
在 /etc/profile 中追加如下内容:
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
追加命令如下:
echo -e '
export SCALA_HOME=/opt/scala-2.12.8
export PATH=$PATH:$SCALA_HOME/bin
' >> /etc/profile
echo -e '
export SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
' >> /etc/profile
使用source命令使配置立即生效
source /etc/profile
9、启动
启动Hadoop集群
start-dfs.sh
start-yarn.sh
启动Spark
start-master.sh
start-slaves.sh
10、查看状态
在三台主机上分别输入jps命令查看状态,结果如下:
[root@s0 conf]# jps
2097 ResourceManager
1803 NameNode
2675 Master
[root@s1 ~]# jps
1643 NodeManager
1518 DataNode
1847 Worker
[root@s2 ~]# jps
1600 NodeManager
1475 DataNode
1804 Worker
符合预期结果!
11、验证
浏览器输入地址:
截图如下:
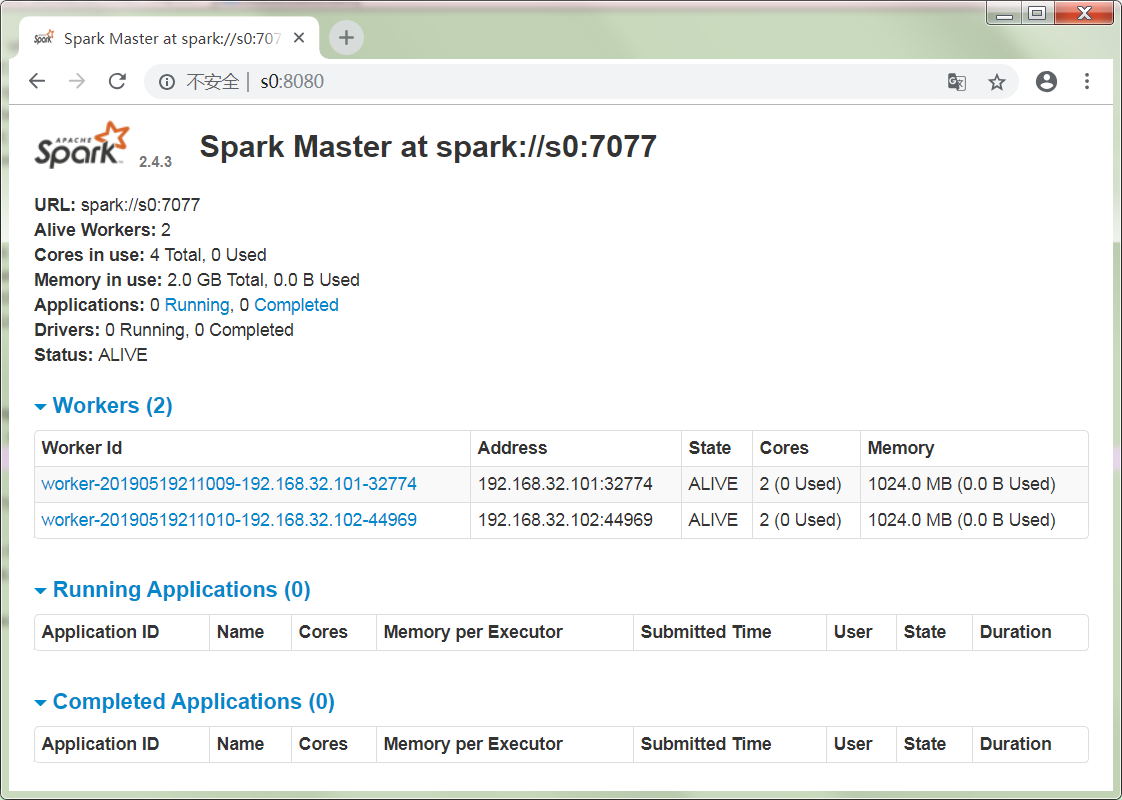
集群状态完美!
12、测试
输入spark-shell 命令,如下所示:
创建 wordcount.txt 文件,内容如下:
Hello Hadoop
Hello Hbase
Hello Spark
上传 wordcount.txt 到 HDFS文件系统上
hdfs dfs -mkdir -p /spark/input
hdfs dfs -put wordcount.txt /spark/input
输入scala 统计单词个数程序,如下:
sc.textFile("hdfs://s0:8020/spark/input/wordcount.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collect
输出结果:
res0: Array[(String, Int)] = Array((Spark,1), (Hello,3), (Hbase,1), (Hadoop,1))
程序正常运行!
13、停止集群
stop-slaves.sh
stop-master.sh
停止Hadoop集群
stop-yarn.sh
stop-dfs.sh
Spark 集群环境搭建
.