python登录豆瓣网站的过程
准备工作
进入豆瓣登录页面https://accounts.douban.com/passport/login
选择使用密码登录

- 按下F12键进入控制台,
- 选择网络
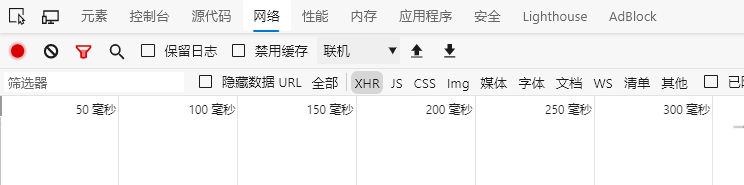
- 在输入框内输入错误的帐号密码,点击登录,
- 这时就会看到
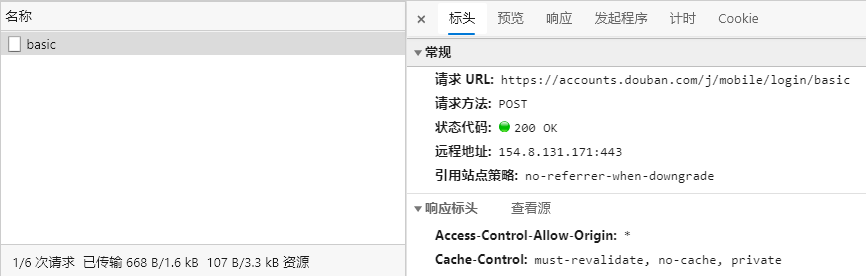
网站发送了一个请求,因为是错误的帐号密码,所以无法发送成功,这时就可查看POST发送的表单信息和登录所使用的链接
https://accounts.douban.com/j/mobile/login/basic
表单信息

这是使用python提交给后台的数据之一
为了让豆瓣知道我们是用浏览器来登录的,需要添加另一个头信息
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 fari/537.36 Edg/83.0.478.37
另外一般网站登录时候都有Cookie验证,所以请求时候Cookie也是必不可少的,这个也可以在标头内获取到。
尝试登录
代码python3
# -*- coding: utf-8 -*- import requests def main(): url_basic = 'https://accounts.douban.com/j/mobile/login/basic' ua_headers = { "User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', "Cookie": "你的登录Cookie", } data = { 'ck': '', 'name': '你的登录帐号', 'password': '你的登录密码', 'remember': 'false', 'ticket': '' } s = requests.Session() r = s.post(url=url_basic, data=data, headers=ua_headers) print(r.text)if __name__ == '__main__': main()
运行代码输出

这时豆瓣就已经登录成功了
获取自己看过的电影
经过上面的测试一切正常,这时网上的一些文章开始请求自己的主页面
https://www.douban.com/people/你的豆瓣ID/
这时豆瓣就会直接返回登录豆瓣的页面,不管cookie的格式有没有转换
所以测试页面不要用自己的豆瓣个人中心
改用自己看过的电影
https://movie.douban.com/people/这里是你的ID号/collect?start=0&sort=time&rating=all&filter=all&mode=grid
这样豆瓣就可以正常返回我们需要的页面了
完整代码如下
# -*- coding: utf-8 -*- import requests def main(): url_basic = 'https://accounts.douban.com/j/mobile/login/basic' ua_headers = { "User-Agent": 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)', "Cookie": "你的登录Cookie", } data = { 'ck': '', 'name': '你的登录帐号', 'password': '你的登录密码', 'remember': 'false', 'ticket': '' } s = requests.Session() url = 'https://movie.douban.com/people/你的豆瓣ID/collect?start=0&sort=time&rating=all&filter=all&mode=grid' r = s.post(url=url_basic, data=data, headers=ua_headers) print(r.text) r.raise_for_status() response = s.get(url=url, headers=ua_headers) print(response.status_code) with open('douban3.html', 'wb') as f: f.write(response.content) if __name__ == '__main__': main()
测试结果如下

生成的douban3.html页面截取

页面在浏览器打开

这样暂时没有发现反爬的措施,爬取页面成功,需要后续操作可以使用beautifulsoup来实现内容获取