服务集群
一个系统从本地调用转成远程调用,原因有很多种。最主要的两个,一个是功能解耦,另外一个就是高可用。为了解决高可用问题,通常再服务部署的时候,都会部署多套,以防止单个服务压力过大或者网络分区等单点故障导致服务不可用,也就是我们常说的集群。
路由
当服务提供方部署成集群的时候,问题就来了,原来只有一个机器提供服务的时候,调用方只需要知道ip+port都可以把请求发过去了。现在,提供方变成了一个ip+port的列表,每次调用前都需要选择其中一个,显然这不是用户想要关心的。这时候一个新的路由模块会被加到中间,调用方把请求发给路由模块,路由模块决定这个请求应该发给后端的那个提供方。像下图这样,调用方不需要知道具体请求发给谁了。
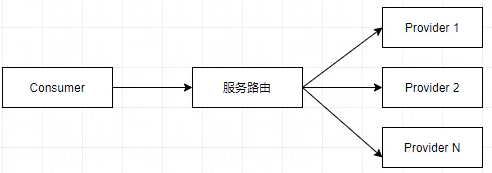
当然,这个路由模块可以是一个单独的Proxy,也可以是一个jar包,集成到Consumer的程序里面。
服务发现
对于路由模块来说,后端的集群配置是不断变化的,比如节点的上下线,ip和端口的变化等。因为服务节点不会知道路由模块的存在,所以双方要有个公共的地方,服务节点变化时更新数据,路由模块通过通知或者轮询拉取变化。这个模块就是注册中心了,常见的作为注册中心的有Eureka、zookeeper等。有了注册中心,路由模块就有了服务发现的能力,上面的图就变成这样:
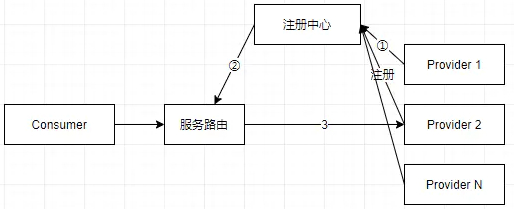
Dubbo集群解决方案
Dubbo集群的特点
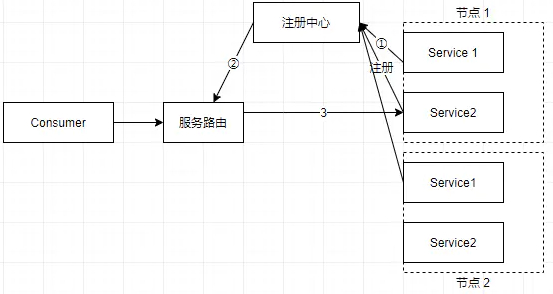
跟现在主流的微服务框架的集群概念稍有不同。Dubbo的集群就是指接口提供者的集合,而不是节点或者机器的集合。当然这不妨碍对它的理解:
先来回顾下Dubbo Consumer一侧的模块调用链:
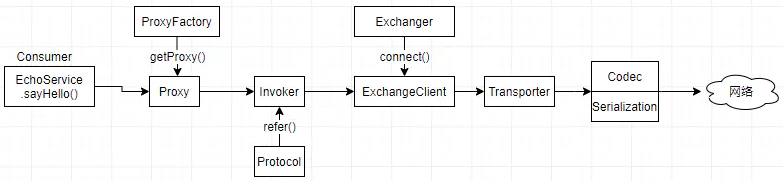
上图中,Proxy通过url获取到一个远程调用的Invoker,Dubbo要做的,就是Invoker提供路由功能,通过注册中心来获取真实的url列表。而做为一个开放的rpc框架,显然要能够很容易的集成现有的注册中心。 这里Dubbo的逻辑是,如果url是具体服务节点的url,比如dubbo://127.0.0.1:12345,那就正常走建立连接,发起调用。如果url是注册中心url,Dubbo通过替换成集群的Invoker来发起调用,下面来看下集群部分的接口抽象。
Cluster
上面提到需要将Invoker替换成一个支持集群调用的Invoker,这个Invoker就是从Cluster中获取的。
@SPI(FailoverCluster.NAME) public interface Cluster { /** * Merge 从directory获取的invoker列表 */ @Adaptive <T> Invoker<T> join(Directory<T> directory) throws RpcException; }
Cluster接口通过将从directory获取的Invoker列表合并成一个集群ClusterInvoker。Directory是Dubbo对服务列表提供者的抽象,显然注册中心就是一种Directory的实现,更准确得说是一种Directory的数据来源,注册中心的部分后面讲。
Cluster实现
Dubbo提供了很多Cluster实现,默认的是FailoverCluster:
public class FailoverCluster extends AbstractCluster { public final static String NAME = "failover"; @Override public <T> AbstractClusterInvoker<T> doJoin(Directory<T> directory) throws RpcException { return new FailoverClusterInvoker<>(directory); } }
可以看到这里的实现就是创建一个具体的ClusterInvoker,将directory传给它。所有的ClusterInvoker实现都继承了AbstractClusterInvoker。
ClusterInvoker实现
AbstractClusterInvoker实现了Invoker接口,所以对Consumer端的Proxy的是透明的。这个类代码比较多,最主要的就是实现接口的invoke() 方法。
public abstract class AbstractClusterInvoker<T> implements Invoker<T> { ... //从directory获取invoker列表 List<Invoker<T>> invokers = list(invocation); //初始化负载均衡 LoadBalance loadbalance = initLoadBalance(invokers, invocation); //子类实现调用 return doInvoke(invocation, invokers, loadbalance); } }
这里面除了从directory获取invoker列表外,最主要的就是初始化LoadBalance,然后发起调用。Dubbo中默认的ClusterInvoker实现就是前面FailoverCluster返回的FailoverClusterInvoker,这个实现包含重试逻辑,即调用一个节点失败的情况下会重试其它的。加了ClusterInvoker之后,调用如下:

负载均衡
当ClusterInvoker从Directory处获取到多个后端服务的Invoker后,选择调用哪个Invoker是有负载均衡策略决定的。就是上面提到的LoadBalance接口。 Dubbo实现了4种策略,分别是加权随机、加权轮询、最小活跃调用、一致性Hash,默认采用加权随机。
@SPI(RandomLoadBalance.NAME) public interface LoadBalance { /** * select one invoker in list. */ @Adaptive("loadbalance") <T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException; }
接口比较简单,根据要调用参数信息,从invokers中选择一个。这个方法由ClusterInvoker负责调用。
注册中心
Dubbo为了对接不同的注册中心,抽象出了Registry接口,定义如下:
public interface Registry extends Node, RegistryService { }
这个接口只是简单组合了Node和RegistryService,组合Node的原因是Dubbo配置中将注册中心也是用url的形式配置的,比如zookeeper://127.0.0.1:2081。主要的接口定义都在RegistryService中:
public interface RegistryService { /** * 注册 */ void register(URL url); /** * 注销 */ void unregister(URL url); /** * 订阅 */ void subscribe(URL url, NotifyListener listener); /** * 取消订阅 */ void unsubscribe(URL url, NotifyListener listener); /** * 主动查询 */ List<URL> lookup(URL url); }
注册中心包含两类接口,注册和注销主要是给服务提供方使用,订阅和取消订阅主要是给服务消费方使用。Dubbo已经默认实现了主流注册中心的对接,比如zookeeper、eureka等。
RegistryDirectory
上面讲到的Cluster接口,当需要一个ClusterInvoker的时候,需要提供一个Directory参数。RegistryDirectory相当于Directory的注册中心实现,它包含了一个注册中心,当注册中心的数据发生变化后,刷新自身的Invoker缓存。
public class RegistryDirectory<T> extends AbstractDirectory<T> implements NotifyListener { ... // 初始化时注入 private Registry registry; ... }
路由策略
服务路由功能中,除了可以通过负载均衡策略来干涉具体调用的服务之外,通常需要一些更加个性化的设置。比如,部分新上线的功能只想让符合一定条件的用户使用,就可以设置根据用户id或者标签来决定请求发送到后端那个提供方。 Dubbo中针对路由策略的接口是Router:
public interface Router extends Comparable<Router> { int DEFAULT_PRIORITY = Integer.MAX_VALUE; /** * Get the router url. */ URL getUrl(); /** * 对于传入的invokers做Rute规则匹配,返回匹配上的invoker列表 */ <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException; /** * 接收invoker list变化通知 */ default <T> void notify(List<Invoker<T>> invokers) { } /** * Router 的优先级 */ int getPriority(); ... }
接口中最主要的就是route() 方法,在Cluster从Directory获取到Invoker列表后,首先查询可用的Route规则,并逐个匹配,只有符合条件的invoker才会交给LoadBalance再选择。 Dubbo默认提供两种实现,一种是基于条件表达式的路由规则设置,一种式基于脚本的路由规则设置。
总结
上面分别从集群支持、负载均衡、注册中心、路由策略等方面分解了Dubbo对集群调用的支持,下面还是通过一张图来看下各个模块的关系。
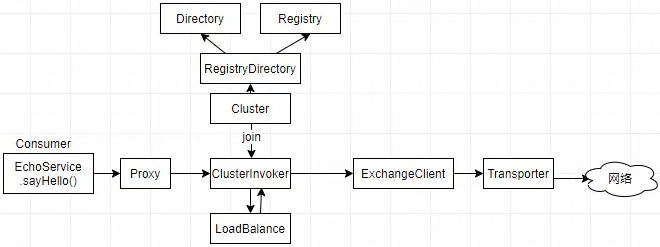
当服务变成一个集群之后,情况复杂了很多,要让用户无感知的调用集群,需要将集群调用做抽象,并对接注册中心。这也是Dubbo在Proxy之后又抽象出Invoker的原因。针对集群调用,内部实现了不同的容错策略,同时围绕Invoker,Dubbo还扩容了其它功能。