当你感到悲哀痛苦时,最好是去学些什么东西。学习会使你永远立于不败之地。
使用场景
在rdd的每一个分区上,执行迭代操作,在每一次的迭代操作中,需要先访问redis缓存,并获取key对应的value,若value存在则对value进行反序列化操作,否则从db里查询并序列化存放到redis缓存中。
伪代码如下:
rdd.mapPartitions {
iter.map{
val value:Option[Array[Byte]] = getValueByKey(key)
value match {
case Some(bs) => {
deserilialize(bs);
other operations...
}
case None => {
val newVals = fetchFromDbByKey(key);
other operations ....;
val newBs = serialize(key);
storeRedis(newBs)
}
}
}
}
从这段位代码可以看出,影响效率的有序列化和反序列化的效率以及序列化后byte数组的字节大小(可以影响网络IO)。
测试指标
主要从四方面来考虑,序列化总时间,反序列化总时间,序列化后平均字节大小,cpu使用率峰值。
其中,使用jconsole监控其cpu使用率峰值。
注意,cpu使用率的峰值只是一个参考,因为在数据量增大时,在序列化和反序列化过程中,伴随着gc,也会消耗cpu资源。
测试数据
https://github.com/Devskiller/jfairy.git 是用来生成测试数据的,可以支持多国语言,由于其本身不是用来测试序列化的数据集,其生成的对象也不是完全可序列化的,字段也多,也包含了一下二级字段,故简化之。
简化之后的数据结构如下:
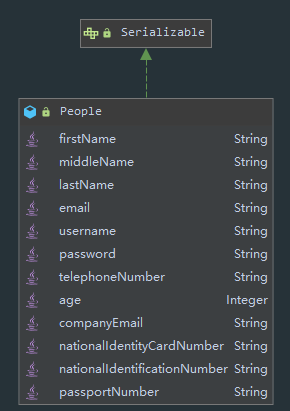
生成测试数据代码如下:
package com.wisers;
import com.devskiller.jfairy.Fairy;
import com.devskiller.jfairy.producer.person.Person;
import java.util.ArrayList;
import java.util.Locale;
public class DataGenerator {
public static ArrayList<People> generatePeople(int sampleNum) {
Fairy chineseFairy = Fairy.create(Locale.CHINESE);
Fairy englishFairy = Fairy.create(Locale.ENGLISH);
ArrayList<People> people = new ArrayList<People>(sampleNum);
for (int i = 0; i < sampleNum; i++) {
Person person = Math.random() >= 0.5 ? chineseFairy.person() : englishFairy.person();
people.add(People.createBy(person));
}
return people;
}
}
测试环境
| cpu | memory | disk |
|---|---|---|
| 1颗cpu,8核 | 32g | 可用 4.9g |
测试方案
尽可能地重用流对象,避免新创建对象对结果的影响
尽可能地避免gc对序列化和反序列化的影响,每次序列化反序列化之后都手动gc,并且测试数据集不宜过大,目前设定最大为1kw,尽可能避免gc对结果的影响
在测试操作过程中,避免打印以及磁盘读取存放等io操作,序列化后的数据直接放在内存,供反序列化使用。
测试结果
下面开始对比业内的比较认可的几种序列化方案。
序列化方案对比结果如下:
不同数据集下各个序列化方案对比
对比结果如下:
| times | type | serialize time(ms) | de-serialize time(ms) | avg size | cpu占用率(峰值) | remark |
|---|---|---|---|---|---|---|
| 10000 | jdk | 73 | 211 | 531 | 2.1 | |
| 10000 | kryo | 71 | 48 | 144 | 1.6 | |
| 10000 | msgpack | 39 | 66 | 119 | 1.1 | |
| 10000 | fst | 53 | 49 | 151 | 2.4 | |
| 10000 | hession | 53 | 113 | 349 | 2.7 | |
| 10000 | protoStuff | 24 | 21 | 131 | 0.6 | |
| 100000 | jdk | 367 | 1387 | 531 | 5.9 | |
| 100000 | kryo | 116 | 88 | 144 | 1 | |
| 100000 | msgpack | 129 | 350 | 119 | 2 | |
| 100000 | fst | 101 | 104 | 151 | 0.9 | |
| 100000 | hession | 211 | 374 | 349 | 2.4 | |
| 100000 | protoStuff | 63 | 70 | 131 | 0.5 | |
| 500000 | jdk | 1746 | 7412 | 531 | 27.2 | |
| 500000 | kryo | 437 | 423 | 144 | 2.4 | |
| msgpack | 414 | 1510 | 119 | 6.6 | ||
| 500000 | fst | 412 | 538 | 151 | 1.7 | |
| 500000 | hession | 890 | 1768 | 349 | 6.4 | |
| 500000 | protoStuff | 263 | 333 | 131 | 1 | |
| 1000000 | jdk | 3479 | 14130 | 531 | 37.2 | |
| 1000000 | kryo | 878 | 844 | 144 | 1.3 | |
| 1000000 | msgpack | 864 | 3036 | 119 | 13.6 | |
| 1000000 | fst | 827 | 993 | 151 | 3.6 | |
| 1000000 | hession | 1688 | 3522 | 349 | 12.8 | |
| 1000000 | protoStuff | 513 | 666 | 131 | 2.5 | |
| 2500000 | jdk | 15558 | 35460 | 531 | 70.2 | |
| 2500000 | kryo | 2151 | 2281 | 144 | 11.7 | |
| 2500000 | msgpack | 2185 | 8170 | 119 | 21.7 | |
| 2500000 | fst | 2014 | 2607 | 151 | 12.6 | |
| 2500000 | hession | 4169 | 9047 | 349 | 15.1 | |
| 2500000 | protoStuff | 1238 | 1777 | 131 | 8.1 | |
| 5000000 | jdk | 41637 | 332540 | 531 | 100 | 均值大概在80% |
| 5000000 | kryo | 4255 | 4774 | 144 | 19.8 | |
| 5000000 | msgpack | 4603 | 16362 | 119 | 41.8 | |
| 5000000 | fst | 3985 | 5399 | 151 | 18.2 | |
| 5000000 | hession | 8716 | 18436 | 349 | 27 | |
| 5000000 | protoStuff | 2563 | 3770 | 131 | 20.1 |
结果分析
时间角度分析
- 由于jdk本身在序列化和反序列化时,ObjectOutputStream、ByteArrayInputStream以及ObjectInputStream不能复用,序列化时间会包含部分对象创建的时间,这会增加gc时间
- msgpack在序列化过程中,MessageUnpacker不能复用,并且需要手动创建类,反序列化时间会比序列化时间长
- hession在反序列化过程中,流不能复用,反序列化时间会比较长
- kryo、fst、protoStuff 在序列化和反序列化的过程中,很好的使用了流复用,序列化效果比较好
- 整体来看,同一种序列化方案,反序列化消耗时间会比序列化消耗时间长,多了对象的创建以及字段映射时间
- 数量级达到百万级后,使用protoStuff、fst以及kryo效果比较好,整体时间消耗依次为 protoStuff < kryo < fst
序列化后字节大小分析
- 整体大小如下:msgpack < protoStuff < kryo < fst < hession < jdk
- msgpack需要手动序列化字段,并不包含类信息,故序列化后的结果比较小
最大堆内存对序列化时间的影响
默认最大堆内存约为7.7g,由于序列化后的数据被存放在内存,不能被gc回收,数据量达到1kw 时,出现内存溢出异常,故调大堆内存,对比在1kw 数据量时最大堆内存对序列化和反序列化的影响。
| Xmx | type | serialize time(ms) | de-serialize time(ms) | avg size | cpu占用率(峰值) |
|---|---|---|---|---|---|
| 20g | jdk | 36283 | 130879 | 531 | 28.1 |
| 20g | kryo | 8759 | 9288 | 144 | 20.2 |
| 20g | msgpack | 9151 | 29653 | 119 | 38.2 |
| 20g | fst | 8274 | 10719 | 151 | 19.5 |
| 20g | hession | 17853 | 38109 | 349 | 21.2 |
| 20g | protoStuff | 5218 | 7767 | 131 | 22.5 |
| 30g | jdk | 37496 | 128481 | 531 | 22.5 |
| 30g | kryo | 8994 | 9200 | 144 | 14.3 |
| 30g | msgpack | 9035 | 29973 | 119 | 22.5 |
| 30g | fst | 8544 | 10088 | 151 | 15.5 |
| 30g | hession | 17366 | 36742 | 349 | 22.7 |
| 30g | protoStuff | 5217 | 7289 | 131 | 20.1 |
结果分析
当数据量在 1kw时,增大最大堆内存,对不能使用流复用技术的 jdk、hession影响比较大,影响为几秒,但整体时间影响并不大,对于其他序列化方案影响在毫秒级,几乎不影响。
分析总结
综合考虑序列化和反序列化时间以及序列化后的大小来看,优先使用 protoStuff 、 kryo 以及 fst 。