提出问题
1. spark shuffle的预聚合操作是如何做的,其中底层的数据结构是什么?在数据写入到内存中有预聚合,在读溢出文件合并到最终的文件时是否也有预聚合操作?
2. shuffle数据的排序是如何做的? 分区内的数据是否是有序的?若有序,spark 内部是按照什么排序算法来排序每一个分区上的key的?
3. shuffle的溢出操作和TaskMemoryManager的关系?
4. 在数据溢出阶段,内存中数据的排序是使用算法进行排序的?
5. 在溢出文件数据合并阶段,内存中的数据的排序是使用的什么算法?
6. 为什么在读取溢出文件到内存中时,返回的结果是迭代器而不是直接的数据结果?
。。。。。。还有很多的细节。
前言
我们先来回首前几篇文章的关系: spark 源码分析之二十一 -- Task的执行流程 从调度的角度说明了TaskScheduler是如何调度任务的,其中任务的执行目前为止写了三篇文章,分别是 剖析Task运行时内存的管理的 spark 源码分析之二十二-- Task的内存管理,剖析shuffle写操作执行前的准备工作,引出了三种shuffle的写方式,前两篇文章分别介绍了 spark shuffle写操作三部曲之UnsafeShuffleWriter 和 spark shuffle写操作三部曲之BypassMergeSortShuffleWriter 前两种shuffle的写的方式。本篇文章来剖析最后一种 shuffle 写的方式。
我们先来看第三种shuffle的相关依赖类。
SizeTrackingAppendOnlyMap
这个类继承了AppendOnlyMap并实现了SizeTracker trait。
其内部方法如下:

它依赖的类都是其父类,他只是它的两个父类的拼凑,所以要想了解真正的动作,还是需要去看其父类AppendOnlyMap和trait SizeTracker。
父类AppendOnlyMap
这个类继承了Iterable trait和 Serializable 接口。
其类结构如下:
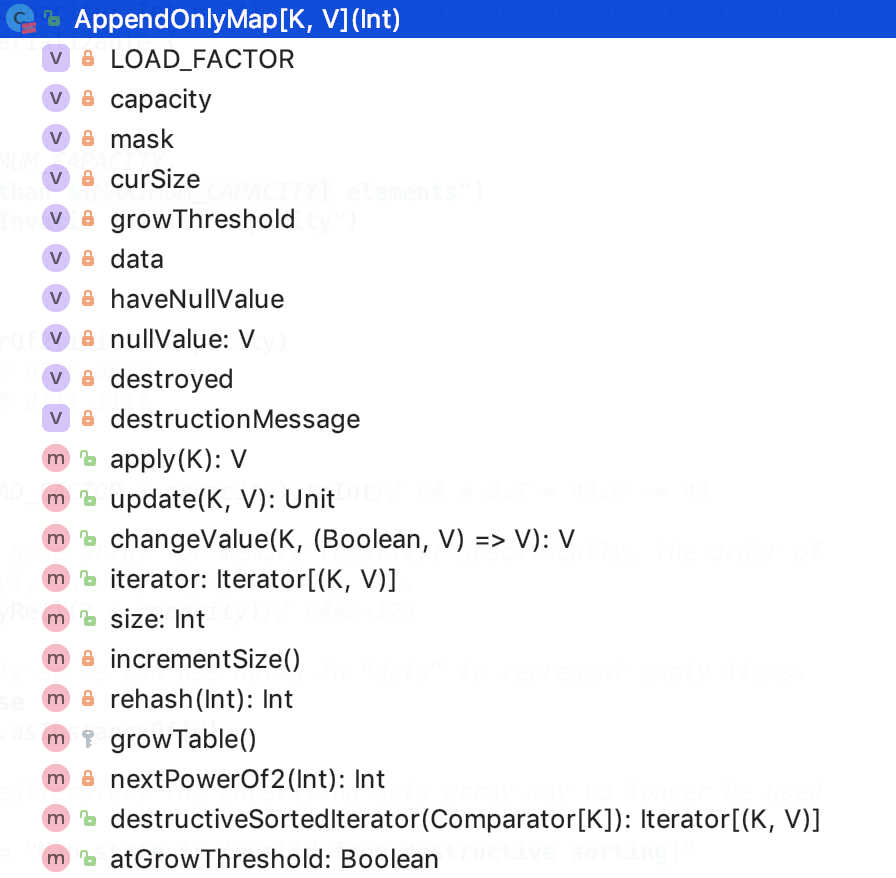
成员变量
成员变量如下:
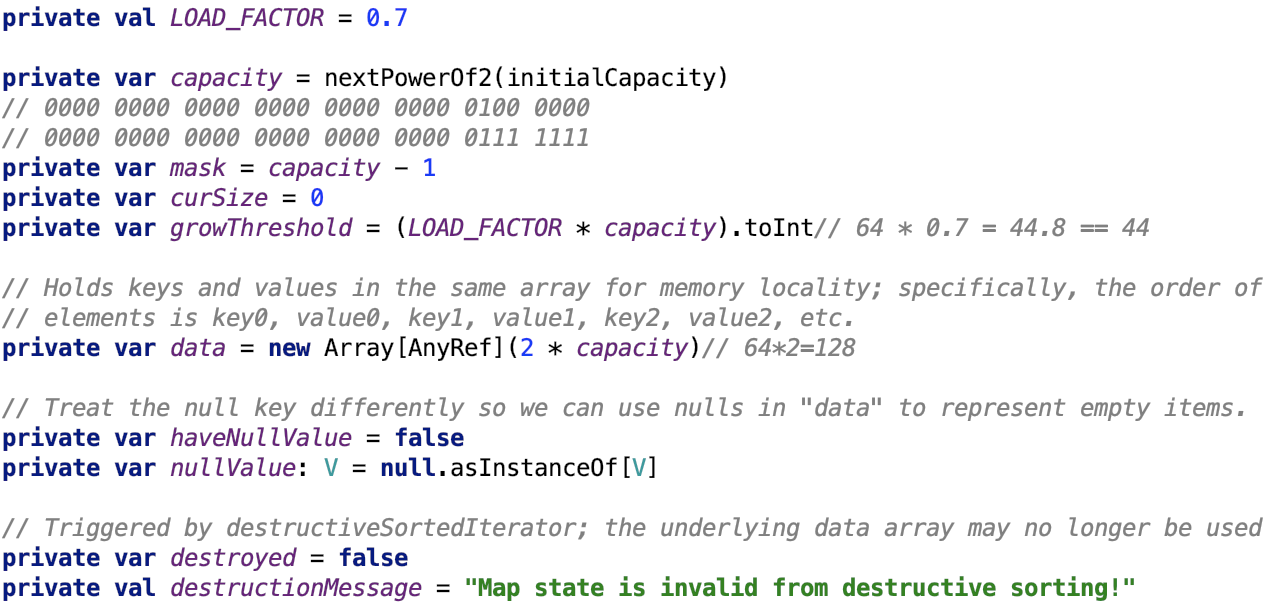
![]()
LOAD_FACTOR:负载因子,为0.7,实际存储数据占比大于负载因子则需要扩容。
mask的作用:将任意的数映射到[0,mask]的范围内。
data:是真正保存数据的数组。
haveNullValue:是否有null值,因为数组中的null值还有一个作用,那就是表示该索引位置没有元素存在。
nullValue:null值。
destoryed:表示数据是否已经被销毁。
理论最大容量为:512MB
成员方法如下:
根据key获取value
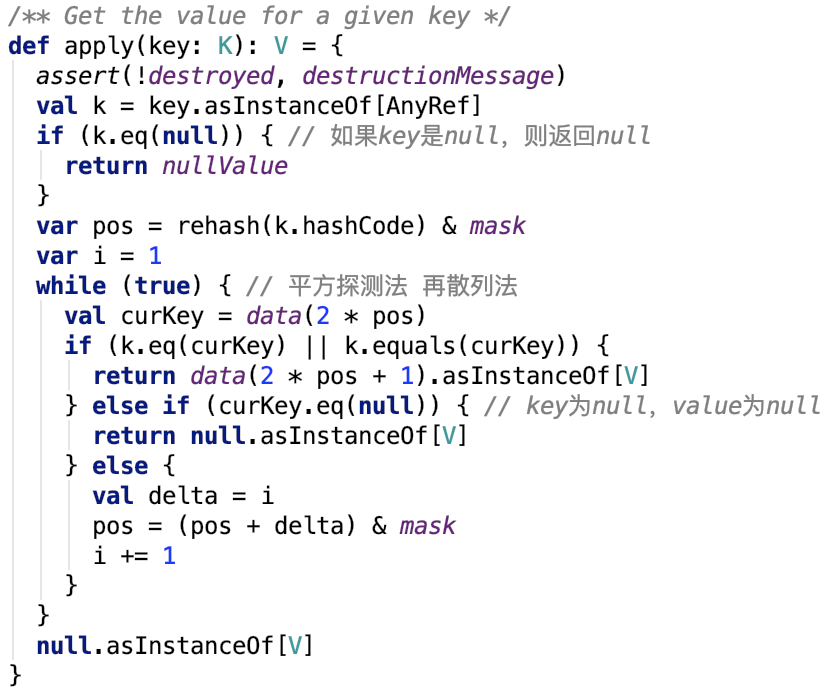
解释:
1.如果是null值,则返回null值,因为约定 null值key对应null值value。
2. 首先先把原来的hashcode再求一次hash码,然后和掩码做与操作将其映射到 [0,mask] 范围内。
3. 尝试取出数据如果取出来的key是指定的key,则返回数据,若取出的key是null,表示之前没有保存过,返回null,若取出的数据的key不是当前key,则使用再散列法 先有pos + delta逐步散列,求得下一次的pos,然后再重复第三步,直至找匹配的值或null值后返回。
设置键值对
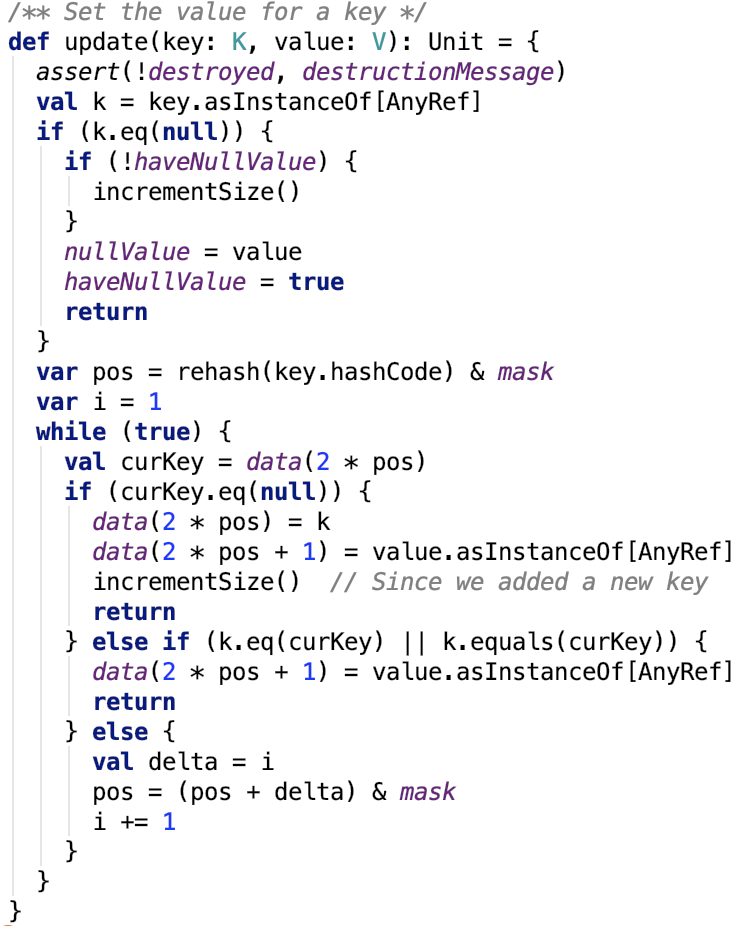
更新键值思路:跟查找的思路一样,只不过找到之后不返回,是执行更新操作。
在指定key的value上执行函数
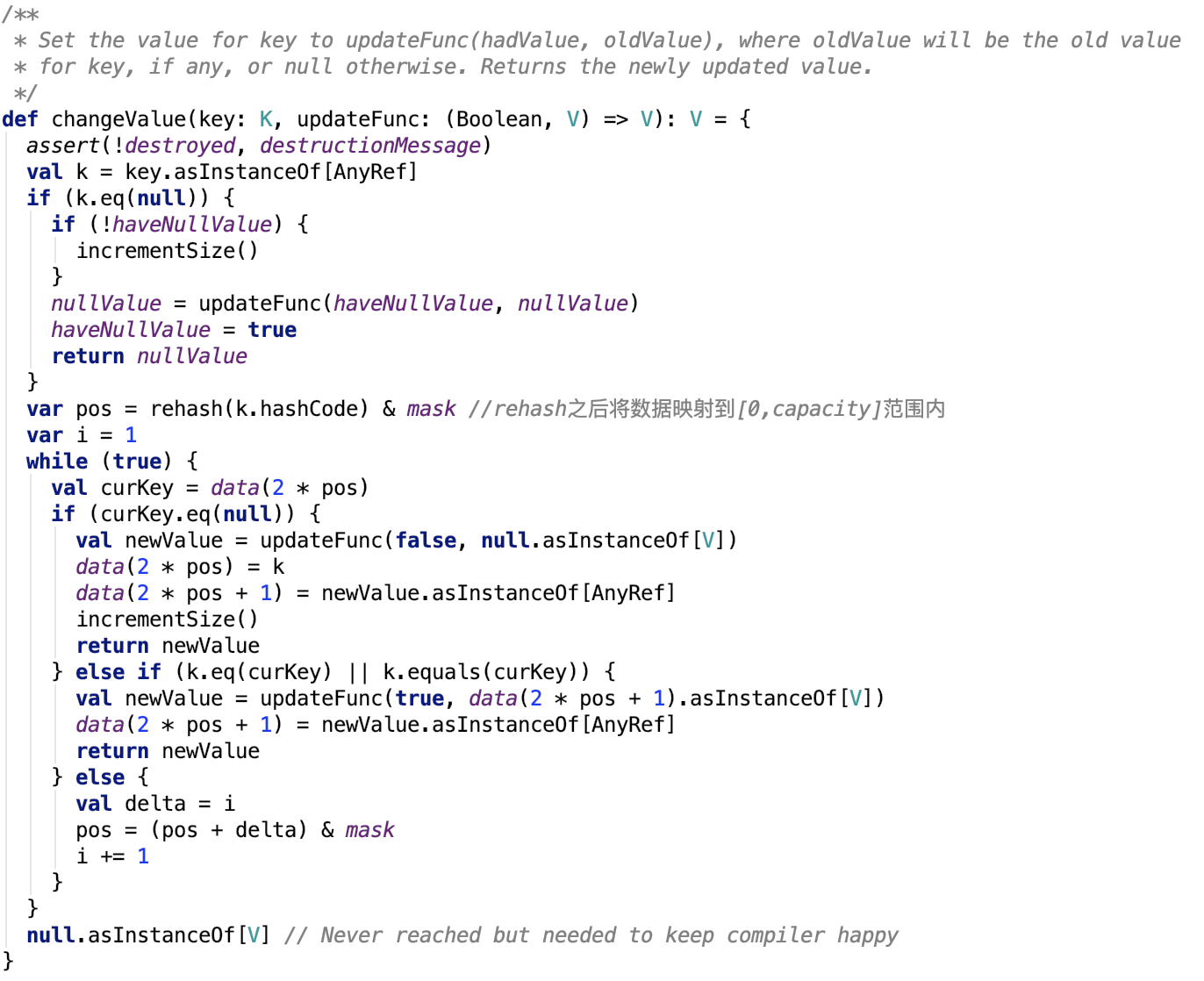
更新键值思路:跟查找的思路一样,只不过找到之后不返回,如果找的的值是null值,则执行赋值操作,否则更新value为执行更新函数后的值。
获取未排序的迭代器
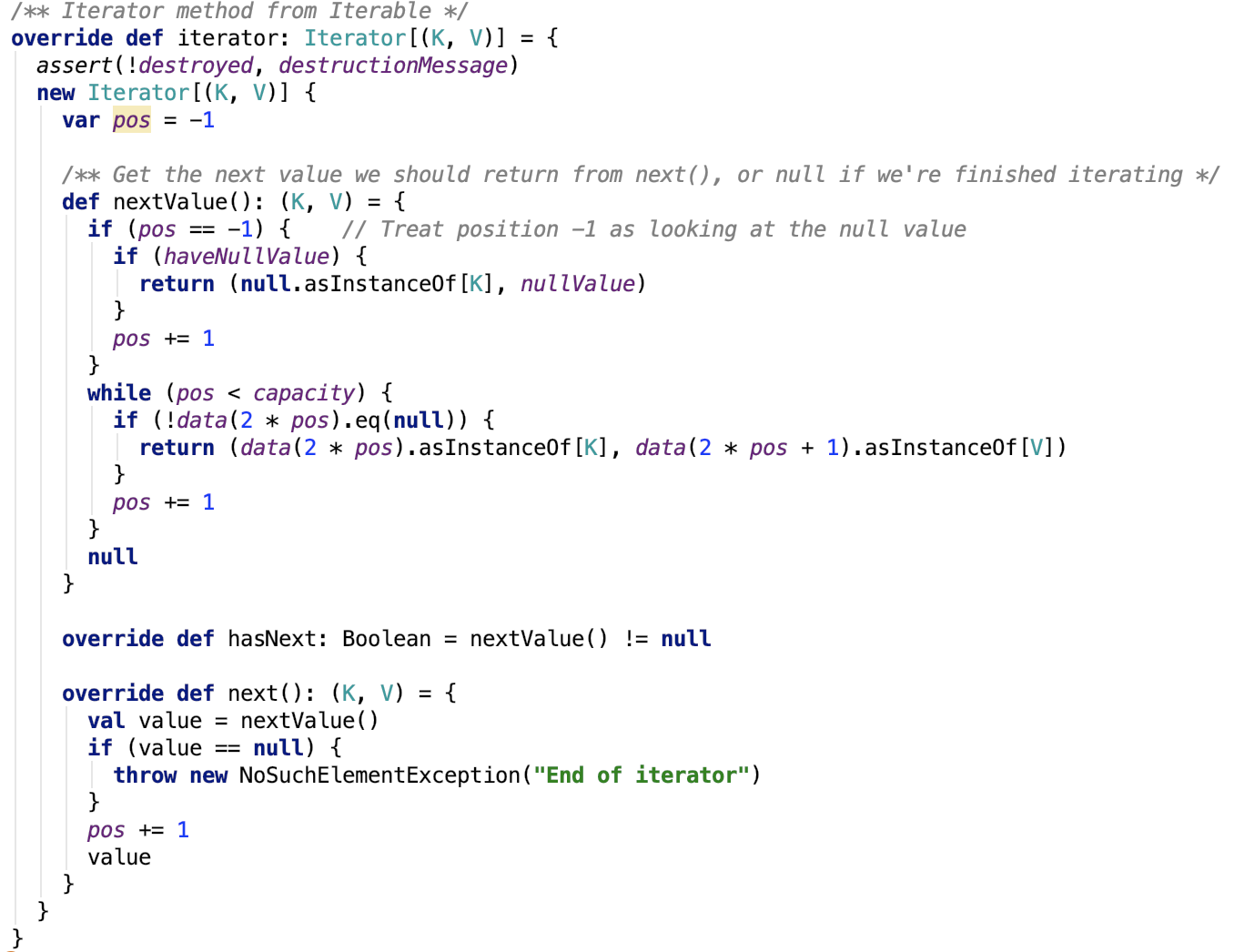
本质上是遍历数组,只不过这里的元素是稀疏的,只返回有元素的数据,不做过多说明。

先整理数组,将数组的数据变为紧凑的数据。再按照key来进行排序。最后返回一个迭代器,这个迭代器里的数据是有序的。
rehash

扩容
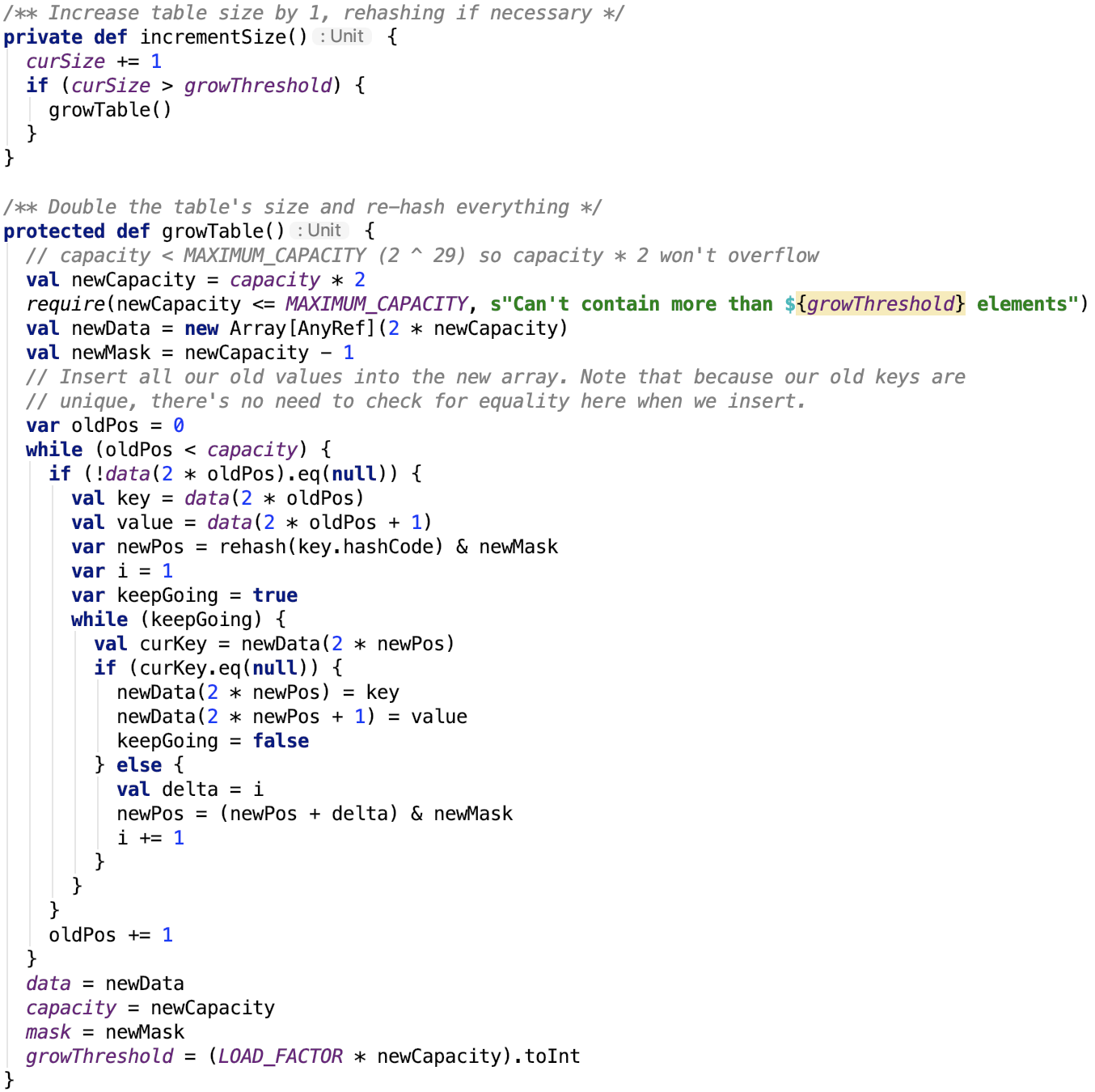
如果当前使用容量占比大于负载因子,则开始扩容。
新容量是旧容量的一倍。遍历旧的数组中的每一个非null元素,将其映射到新的数组中。
父类SizeTracker
A general interface for collections to keep track of their estimated sizes in bytes. We sample with a slow exponential back-off using the SizeEstimator to amortize the time, as each call to SizeEstimator is somewhat expensive (order of a few milliseconds).
集合的通用接口,用于跟踪其估计的大小(以字节为单位)。 我们使用SizeEstimator以缓慢的指数退避进行采样以分摊时间,因为每次调用SizeEstimator都有点昂贵。
成员变量

SAMPLE_GROWTH_RATE指数增长因子,比如是2,则是 1,2,4,8,16,......
核心方法如下:
采样

估算大小

重采样

更新后采样

依赖类 -- SizeEstimator
主要用于数据占用内存的估算。
ExternalAppendOnlyMap
继承关系
其继承关系如下:
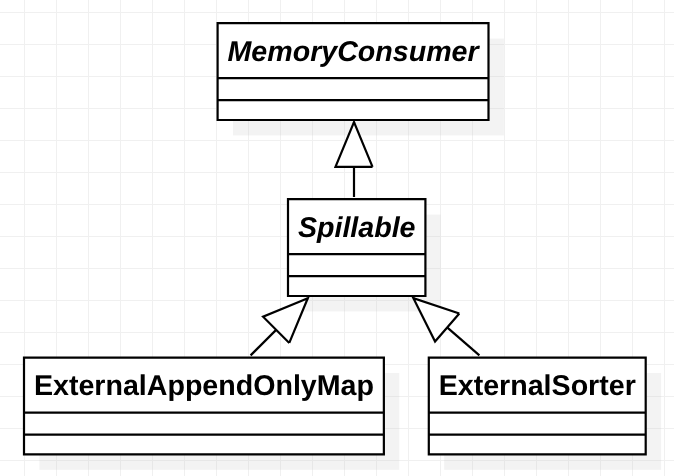
其父类是Spillable抽象类。
先来看父类Spillable
超类--Spillable
类说明:当内存不足时,这个类会把内存里的集合溢出到磁盘中。
其成员变量如下,不做过多解释。
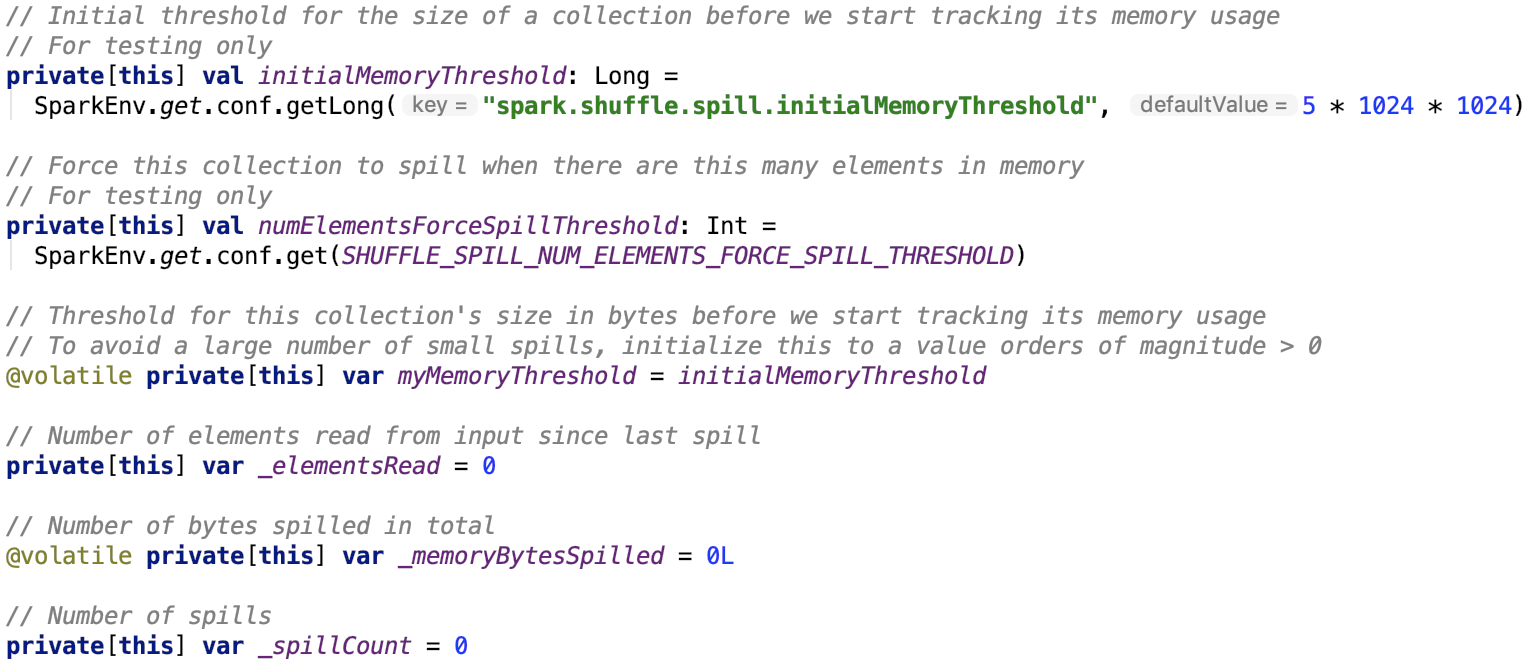
主要方法如下:
溢出内存到磁盘
它实现了父类的抽象方法 spill方法,源码如下:

思路:如果consumer不是这个类并且内存模式是堆内内存才支持内存溢出。
其依赖方法如下:
org.apache.spark.util.collection.Spillable#forceSpill源码如下,它是一个抽象方法,没有具体实现。

释放内存方法,其调用了 父类的freeMemory方法:

尝试溢出来释放内存
org.apache.spark.util.collection.Spillable#maybeSpill 源码如下:

其依赖方法spill方法如下,注意这个方法是用来溢出集合的数据到内存的,它是抽象方法,待子类实现。

这个类留给子类两个方法来实现,forceSpill和spill方法。
ExternalAppendOnlyMap这个类里面的是对 SizeTrackingAppendOnlyMap 的进一步封装,下面我们先看 SizeTrackingAppendOnlyMap。
数据比较器 -- HashComparator
其源码如下:

总之,它是根据哈希码进行比较的。
SpillableIterator
首先,它是org.apache.spark.util.collection.ExternalAppendOnlyMap的内部类,实现了Iterator trait,它是跟ExternalAppendOnlyMap一起使用的,也使用了 ExternalAppendOnlyMap 里的方法。
成员变量
其成员变量如下:

SPILL_LOCK是一个对象锁,每次执行溢出操作都会先获取锁再执行溢出操作,执行完毕后释放锁。
cur表示下一个未读的元素。
hasSpilled表示是否有溢出。
核心方法
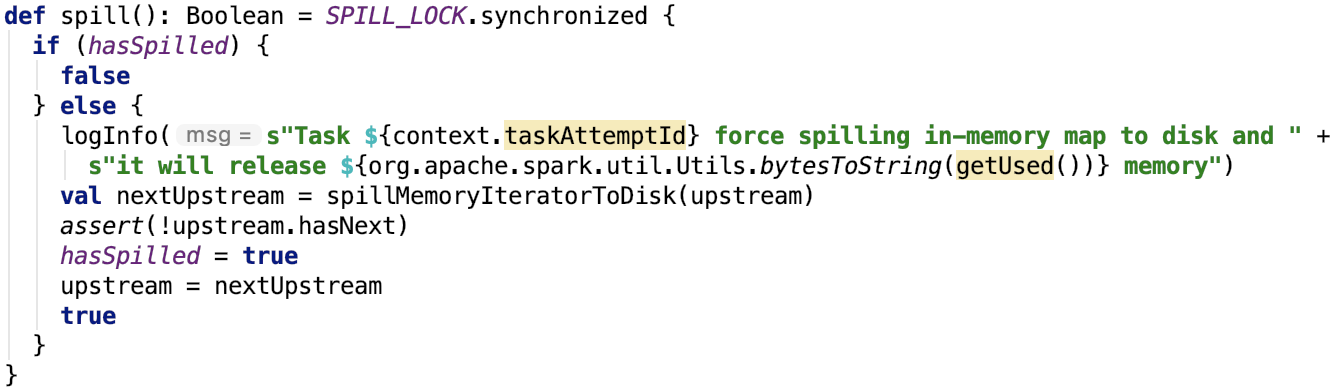
1.溢出
其源码如下:
2.销毁数据释放内存

其依赖方法 org.apache.spark.util.collection.ExternalAppendOnlyMap#freeCurrentMap 如下:

3. 读取下一个

4. 是否有下一个
![]()
5. 获取下一个元素

6. 转换为CompletionIterator
![]()
总结
从本质来来说,它是一个包装类,数据从构造方法以Iterator的形式传递过来,而它自己也是一个Iterator,除了实现了Iterator本身的方法外,还具备了溢出到磁盘、销毁内存数据、转换为CompletionIterator的功能。
DiskMapIterator
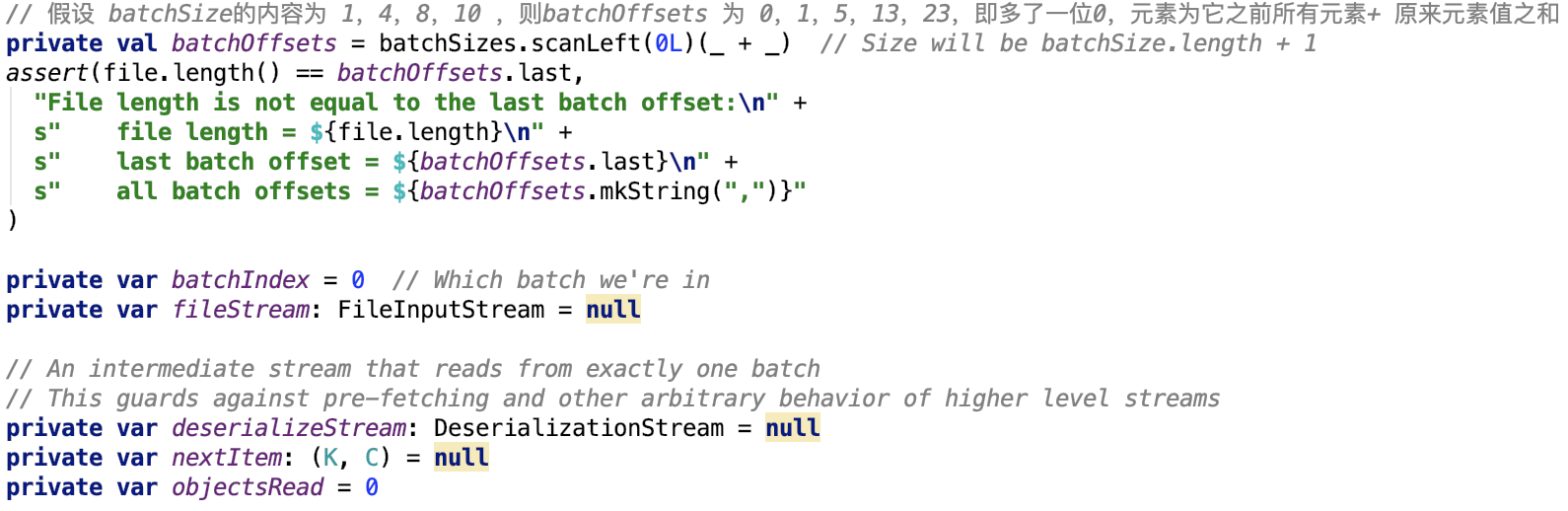
这个类就是用来读取文件的数据的,只不过文件被划分为了多个文件段,有一个数组专门记录这多个文件段的段大小,如构造函数所示:
![]()
其中file就是要读取的数据文件,blockId表示文件在shuffle系统中对应的blockId,batchSize就是指的每一个文件段的大小。
成员变量如下:
下面从Iterator的主要方法入手,去剖析整个类。
是否有下一个元素

其依赖方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#readNextItem 源码如下:

思路:首先先读取下一个key-value对,若读取完毕后,发现这个批次的数据已经读取完毕,则调用 nextBatchStream 方法,关闭现有反序列化流,初始化读取下一个文件段的反序列化流。
其依赖方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#nextBatchStream 如下:

思路:首先先确定该批次的数据是否读取完毕,若读取完毕,则做完清理操作后,返回null值,否则先关闭现有的反序列化流,然后获取下一个反序列化流的开始和结束offset,最后初始化一个反序列化流返回给调用端。
其依赖方法 org.apache.spark.util.collection.ExternalAppendOnlyMap.DiskMapIterator#cleanup 方法如下:

思路:首先关闭现有的反序列化流和文件流,最后如果文件存在,则删除之。
读取下一个元素

思路很简单,其中,nextItem已经在是否有下一个元素的时候反序列化出来了。
构造方法
它有两个重载的构造方法:

和

解释一下其中的参数:
createCombiner:是根据一个原值来创建其combine之后的值的函数。
mergeValue:是根据一个combine之后的值和一个原值求combine之后的值的函数。
mergeCombiner:是根据两个combine之后的值求combine之后的值函数。
本质上这几个函数就是逐步归并聚合的体现。
成员变量

serializerBatchSize:表示每次溢出时,写入文件的批次大小,这个批次是指的写入的对象的次数,而不是通常意义上的buffer的缓冲区大小。
_diskBytesSpilled :表示总共溢出的字节大小
fileBufferSize: 文件缓存大小,默认为 32k
_peakMemoryUsedBytes: 表示内存使用峰值
keyComparater:表示内存排序的比较器
核心方法
插入数据


溢出操作

思路:首先先调用currentMap的destructiveSortedIterator方法,先整理其内部的数据成紧凑的数据,然后对数据进行排序,最终有序数据以Iterator的结果返回。然后调用
将数据溢出到磁盘,最后将溢出的信息记录到spilledMaps中,其依赖方法 org.apache.spark.util.collection.ExternalAppendOnlyMap#spillMemoryIteratorToDisk 源码如下:

思路:创建本地临时block,并获取其writer,最终遍历内存数组的迭代器,将数据都通过writer写入到file中,其中写文件是分批写入的,即每次满足serializerBatchSize大小之后,执行flush写入,最后执行一次flush写入,关闭文件,最终返回DiskMapIterator对象。
强制溢出

摧毁迭代器

获取迭代器

预聚合类 -- Aggregator
其源码如下:

这个类的两个方法 combineValuesByKey 和 combineCombinersByKey 都依赖于 ExternalAppendOnlyMap类。
下面继续来看ExternalSorter类的内部实现。
支持排序预聚合的sorter -- ExternalSorter
类说明
Sorts and potentially merges a number of key-value pairs of type (K, V) to produce key-combiner pairs of type (K, C). Uses a Partitioner to first group the keys into partitions, and then optionally sorts keys within each partition using a custom Comparator. Can output a single partitioned file with a different byte range for each partition, suitable for shuffle fetches. If combining is disabled, the type C must equal V -- we'll cast the objects at the end. Note: Although ExternalSorter is a fairly generic sorter, some of its configuration is tied to its use in sort-based shuffle (for example, its block compression is controlled by spark.shuffle.compress). We may need to revisit this if ExternalSorter is used in other non-shuffle contexts where we might want to use different configuration settings.
对类型(K,V)的多个键值对进行排序并可能合并,以生成类型(K,C)的键组合对。使用分区程序首先将key分组到分区中,然后可以选择使用自定义Comparator对每个分区中的key进行排序。可以为每个分区输出具有不同字节范围的单个分区文件,适用于随机提取。如果禁用了组合,则类型C必须等于V - 我们将在末尾转换对象。注意:虽然ExternalSorter是一个相当通用的排序器,但它的一些配置与基于排序的shuffle的使用有关(例如,它的块压缩由spark.shuffle.compress控制)。如果在我们可能想要使用不同配置设置的其他非随机上下文中使用ExternalSorter,我们可能需要重新审视这一点。
下面,先来看其构造方法:
构造方法

参数如下:
aggregator:可选的聚合器,可以用于归并数据
partitioner :可选的分区器,如果有的话,先按分区Id排序,再按key排序
ordering : 可选的排序,它在每一个分区内按key进行排序,它也可以是全局排序
serializer :用于溢出内存数据到磁盘的序列化器
其成员变量和核心方法,先不做剖析,其方法围绕两个核心展开,一部分是跟数据的插入有关的方法,一部分是跟多个溢出文件的合并操作有关的方法。
下面来看看它的一些内部类。
只读一个分区数据的迭代器 -- IteratorForPartition
这个类实现了Iterator trait,只负责迭代读取一个特定分区的数据,其定义如下:

比较简单,不做过多说明。
溢出文件的描述 -- SpilledFile

这个类是一个 case class ,它记录了溢出文件的一些关键信息,构造方法的各个字段如下:
file:溢出文件
blockId:溢出文件对应的blockId
serializerBatchSizes:表示每一个序列化类对应的batch的大小。
elementsPerPartition:表示每一个分区的元素的个数。
比较简单,没有类的方法定义。
读取溢出文件的内容 -- SpillReader
它负责读取一个按分区做文件分区的文件,希望按分区顺序读取分区文件的内容。
其类结构如下:
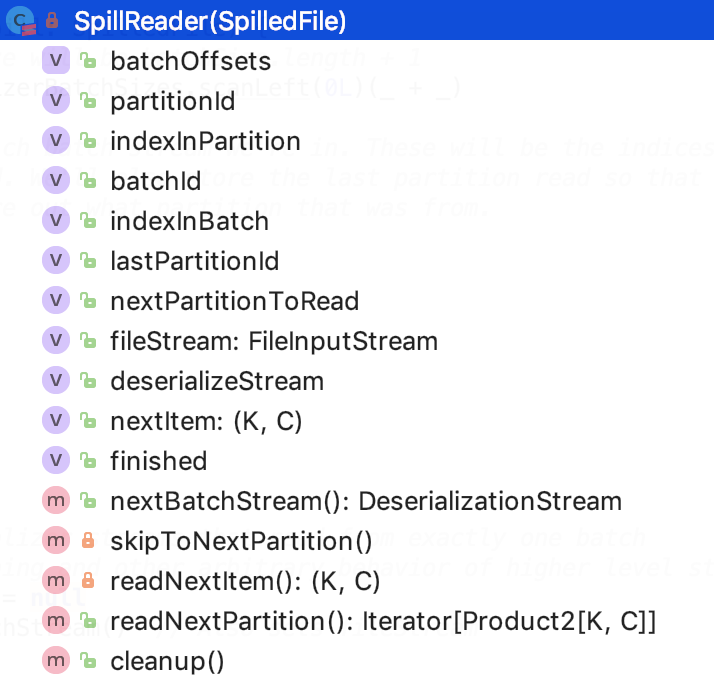
成员变量
先看其成员变量:
batchOffsets:序列化类的每一个批次的offset
partitionId:分区id
indexInPartition:在分区内的索引信息
batchId:batch的id
indexInBatch:在batch中的索引信息
lastPartitionId:上一个partition ID
nextPartitionToRead:下一个要读取的partition的id
fileStream:文件输入流
deserializeStream:分序列化流
nextItem:下一个键值对
finished:是否读取完毕
下面,来看其核心方法:
获取下一个批次的反序列化流

思路跟DiskMapIterator的获取下一个流的思路很类似,不做过多解释。
读取下一个partition的数据
其返回的是一个迭代器,org.apache.spark.util.collection.ExternalSorter.SpillReader#readNextPartition源码如下:
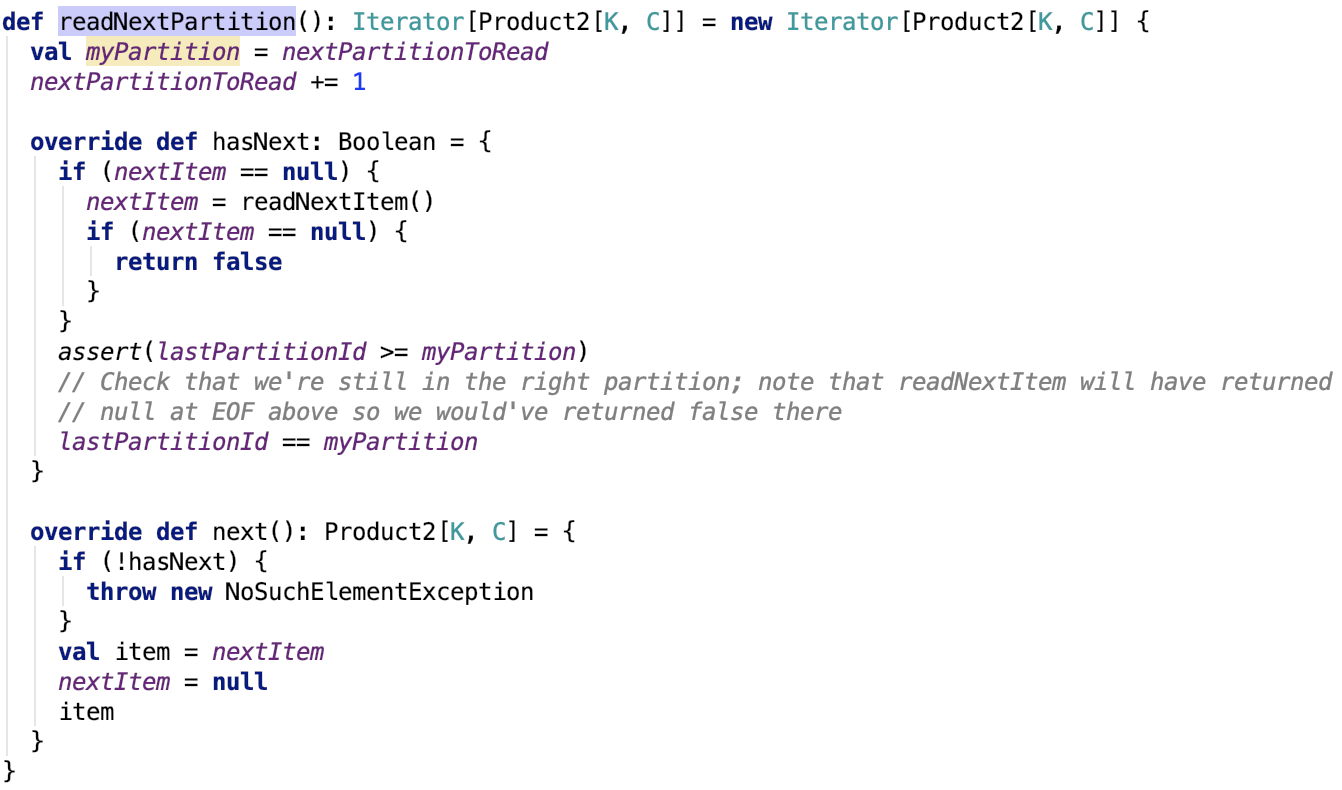
思路:其返回迭代器中,的hasNext中先去读取下一个item,如果读取到的下一个元素为null,则返回false,表示没有数据可以返回。
其依赖方法 org.apache.spark.util.collection.ExternalSorter.SpillReader#readNextItem 源码如下:
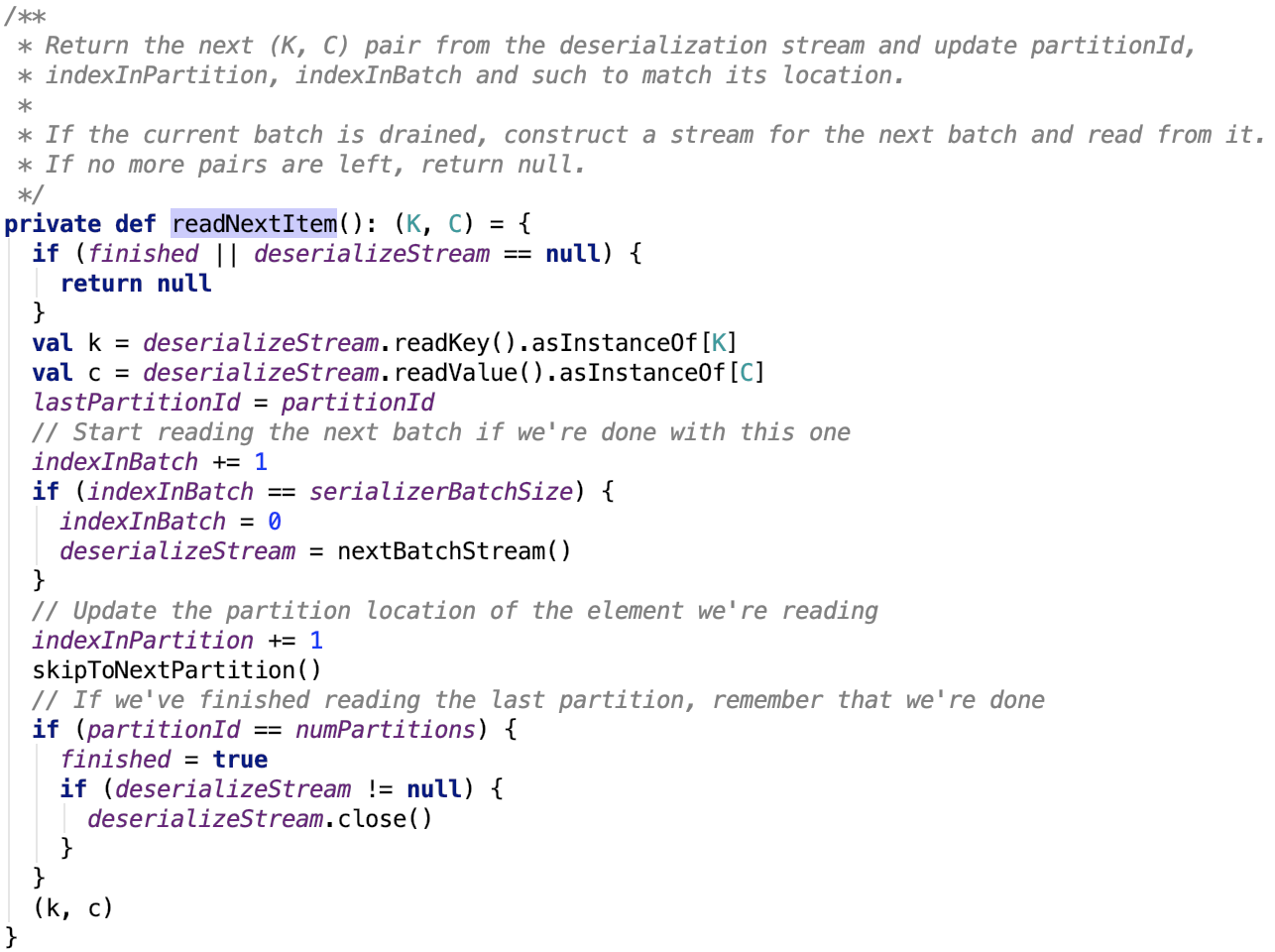
思路:首先该批次数据读取完毕,则关闭掉读取该批次数据的流,继续读取下一个批次的流。
其依赖方法 org.apache.spark.util.collection.ExternalSorter.SpillReader#skipToNextPartition 方法如下:

下面,整理一下思路:
每次读取一个文件的分区,该分区读取完毕,关闭分区文件,读取下一个文件的下一个分区数据。只不过它在读文件的分区的时候,会有batch操作,一个分区可能会对应多个batch,但是一个batch有且只能有一个分区。
SpillableIterator
首先它跟 org.apache.spark.util.collection.ExternalAppendOnlyMap.SpillableIterator 很像, 实现方法也很类似,都是实现了一个Iterator trait,构造方法以一个Iterator对象传入,并且对其做了封装,可以跟上文的 SpillableIterator 对比剖析。
其成员变量如下:

nextUpStream:下一个批次的stream
对Iterator的实现
先来看Iterator的方法实现:

溢出
其源码如下:
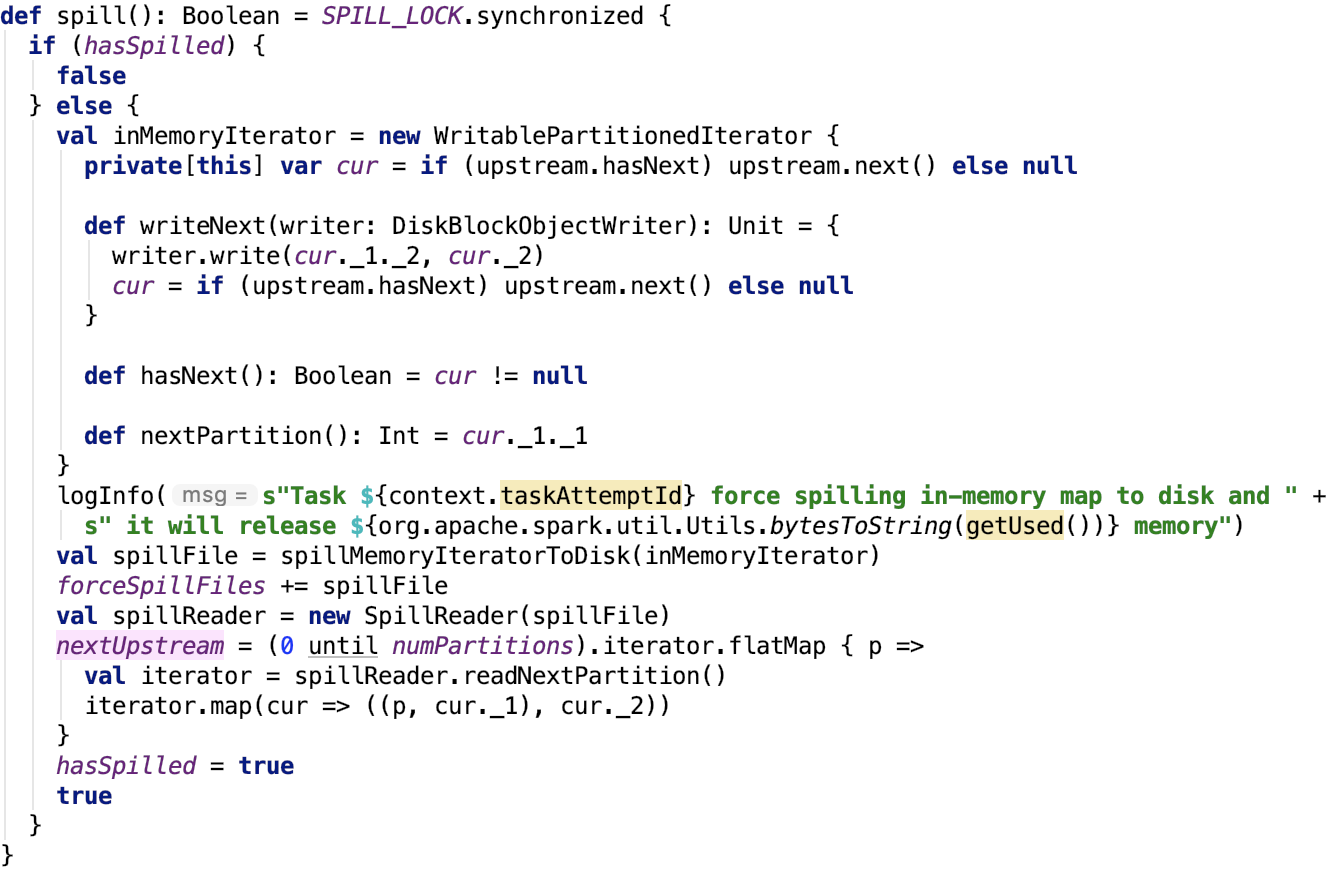
思路如下:首先创建内存迭代器,然后遍历内存迭代器,将数据溢出到磁盘中,其关键方法 spillMemoryIteratorToDisk。
两种存放溢出前数据的数据结构
PartitionedAppendOnlyMap
这个类底层是数组,数据按照Map的形式稀疏排列,它还支持多个key的预聚合操作。
它是SizeTrackingAppendOnlyMap和 WritablePartitionPairCollection的子类。
其源码如下:

PartitionedPairBuffer
这个类底层是数组,数据按数组的形式紧凑排列。不支持多个相同key的预聚合操作。
它是SizeTracker 和 WritablePartitionPairCollection的子类。
其源码如下:
插入数据

数组扩容

获取排序后的迭代器

获取读取数组数据的迭代器

下面来看最后一种shuffle数据写的方式。
使用SortShuffleWriter写数据
这种shuffle方式支持预聚合操作。
其下操作源码如下:
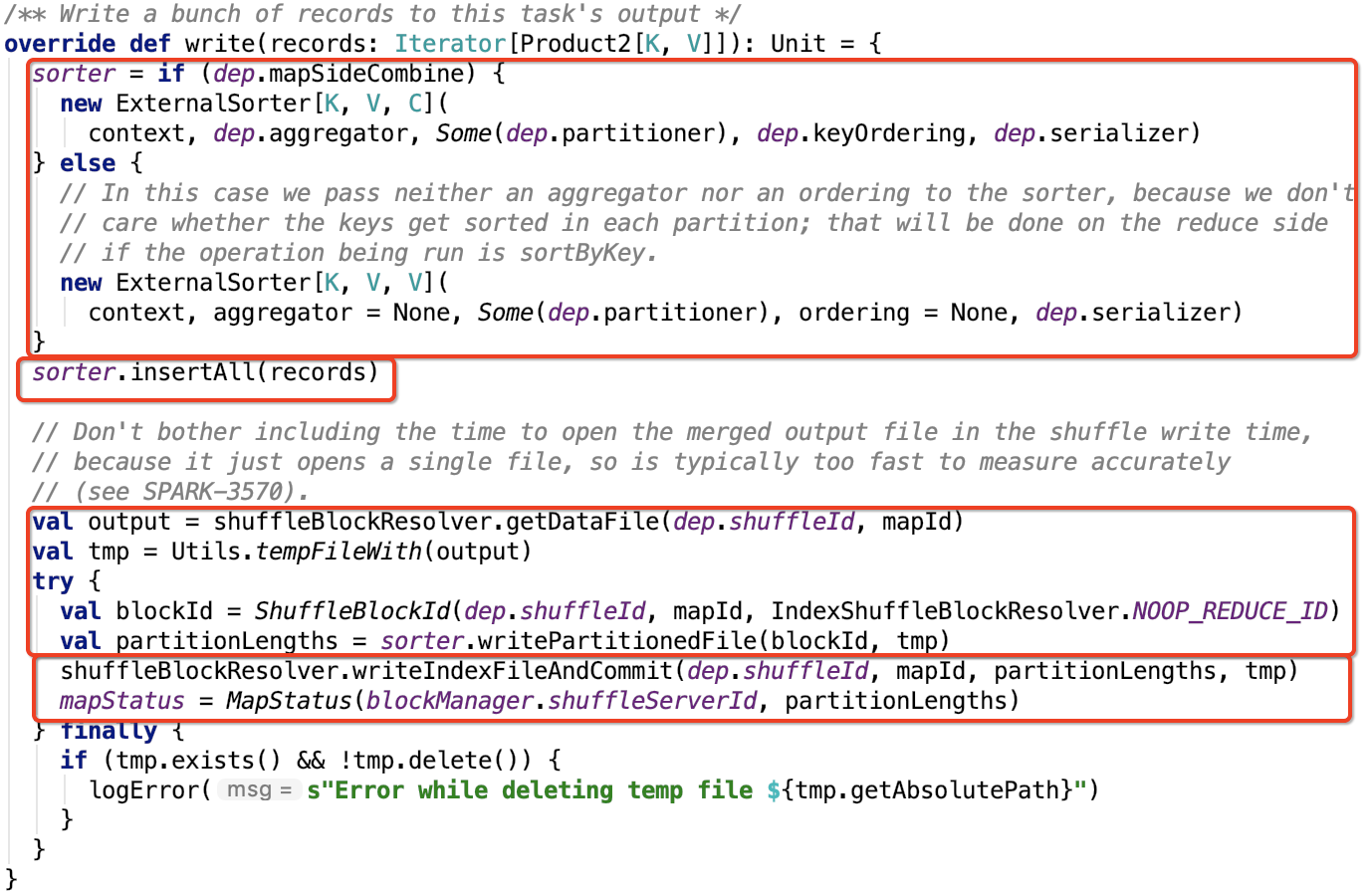
初始化Sorter
如果需要在map段做combine操作,则需要指定 aggragator和 keyOrdering,即map端的数据会做预聚合操作,并且分区内的数据有序,其排序规则是按照hashCode做排序的。
否则这两个参数为null,即map端的数据没有预聚合,并且分区内数据无序。
向sorter插入数据
其源码如下:
![]()
org.apache.spark.util.collection.ExternalSorter#insertAll的源码如下:
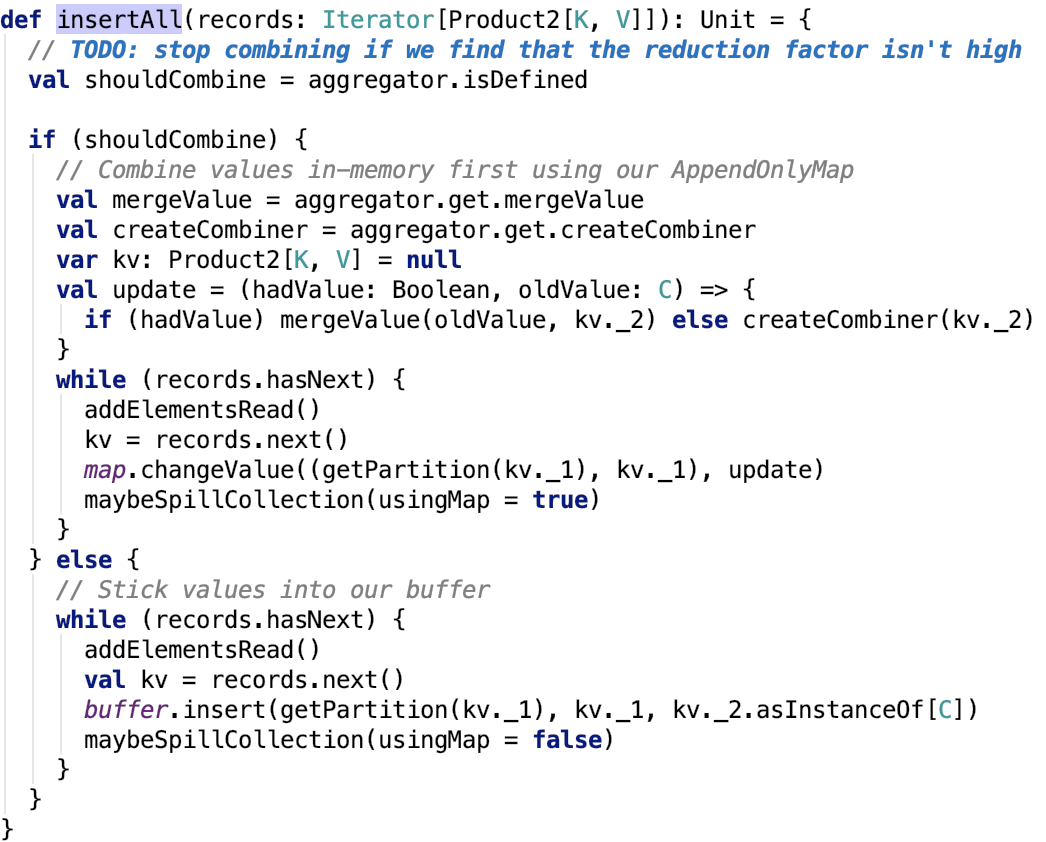
思路:首先如果数据需要执行map端的combine操作,则使用 PartitionedAppendOnlyMap 类来操作,这个类可以支持数据的combine操作。如果不需要 执行map 端的combine 操作,则使用 PartitionedPairBuffer 来实现,这个类不会对数据进行预聚合。每次数据写入之后,都要查看是否需要执行溢出内存数据到磁盘的操作。
这两个类在上文中已经做了详细的说明。
其依赖方法 addElementsRead 源码如下:
![]()
溢出内存数据到磁盘的核心方法 maybeSpillCollection 源码如下:

思路:它有一个标志位 usingMap表示是否使用的是map的数据结构,即是否是 PartitionedAppendOnlyMap,其思路几乎一样,只不过在调用 mayBeSpill 方法中传入的参数不一样。其中使用的内存的大小,都是经过采样评估计算过的。其依赖方法 org.apache.spark.util.collection.Spillable#maybeSpill 如下:

思路:如果读取的数据是 32 的整数倍并且当前使用的内存比初始内存大,则开始向TaskMemoryManager申请分配内存,如果申请成功,则返回申请的大小,注意:在向TaskMemoryManager申请内存的过程中,如果内存不够,也会去调用 org.apache.spark.util.collection.Spillable#spill 方法,在其内部也会去调用 org.apache.spark.util.collection.ExternalSorter#forceSpill 方法其源码如下,其中readingIterator是SpillableIterator类型的对象。

其依赖方法 org.apache.spark.util.collection.Spillable#logSpillage 会打印一些溢出日志。不再过多说明。
其依赖方法 org.apache.spark.util.collection.ExternalSorter#spill 源码如下:
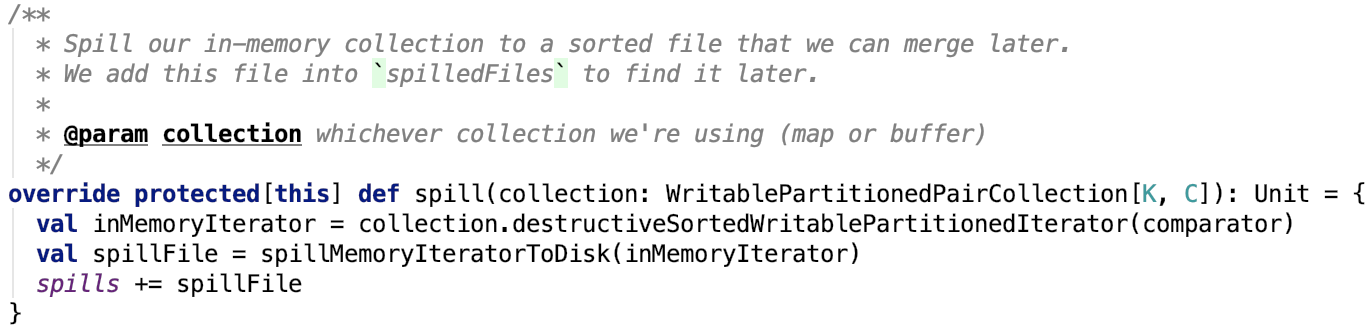
思路相对比较简单,主要是先获取排序后集合的迭代器,然后将迭代器传入 org.apache.spark.util.collection.ExternalSorter#spillMemoryIteratorToDisk ,将内存数据溢出到临时的磁盘文件后返回一个SpilledFile对象,将其记录到 spills中,spills这个变量主要记录了内存数据的溢出过程中的溢出文件的信息。
其溢出磁盘方法 org.apache.spark.util.collection.ExternalSorter#spillMemoryIteratorToDisk 源码如下:

首先获取写序列化文件的writer,然后遍历数据的迭代器,将数据迭代写入到磁盘中,在写入过程中,不断将每一个分区的大小信息以及每一个分区内元素的个数记录下来,最终将溢出文件、分区元素个数,以及每一个segment的大小信息封装到SpilledFile对象中返回。
多文件归并为一个文件
其核心代码如下:

思路:首先先初始化一个临时的最终文件(以uuid作为后缀),然后初始化blockId,最后调用 org.apache.spark.util.collection.ExternalSorter的writePartitionedFile 方法。将数据写入一个临时文件,并将该文件中每一个分区对应的FileSegment的大小返回。
其关键方法 org.apache.spark.util.collection.ExternalSorter#writePartitionedFile 源码如下:

思路:首先如果从来没有过溢出文件,则首先先看一下是否需要map端聚合,若是需要,则数据已经被写入到了map中,否则是buffer中。然后调用集合的转成迭代器的方法,将内存的数据排序后输出,最终迭代遍历这个迭代器,将数据不断写入到最终的临时文件中,更新分区大小返回。
如果之前已经有溢出文件了,则先调用 org.apache.spark.util.collection.ExternalSorter的partitionedIterator 方法将数据合并后返回合并后的迭代器。
最终遍历每一个分区的数据,将分区的数据写入到最终的临时文件,更新分区大小;最后返回分区大小。
下面重点剖析一下合并方法 org.apache.spark.util.collection.ExternalSorter#partitionedIterator,其源码如下:

首先,要说明的是,通过我们上面的程序分支进入该程序,此时历史溢出文件集合是空的,即它不会执行第一个分支的处理流程,但还是要做一下简单的说明。
它有三个依赖方法分别如下:
依赖方法 org.apache.spark.util.collection.ExternalSorter#destructiveIterator 源码如下:

思路:首先 isShuffleSort为 true,我们现在就是走的 shuffle sort的流程,肯定是需要走第一个分支的,即它不会返回一个SpillableIterator迭代器。
值得注意的是,这里的comparator跟内存排序使用的comparator是一样的,即排序方式是一样的。
依赖方法 org.apache.spark.util.collection.ExternalSorter#groupByPartition 源码如下:

思路:遍历每一个分区返回一个IteratorForPartition的分区迭代器。
注意:由于历史溢出文件集合此时不为空,将不会调用这个方法。
依赖方法 org.apache.spark.util.collection.ExternalSorter#merge 源码如下:

思路:传给merge方法的有两个参数,一个是代表溢出文件的SpiiledFile集合,一个是代表内存数据的迭代器。
首先遍历每一个溢出文件,创建一个读取该溢出文件的SpillReader对象,然后遍历每一个分区创建一个IteratorForPartition迭代器,然后读取每一个溢出文件的分区的迭代器,最终和 作为参数传入merge 方法的内存迭代器合并到一个迭代器集合中。
如果是需要预聚合的,则调用 mergeWithAggregation 方法,如果是需要排序的,则调用mergeSort 方法,对其进行排序,最后如果不满足前两种情况,调用集合的flatten 方法,将打平到一个迭代器中返回。
它有两个依赖方法,分别如下:
org.apache.spark.util.collection.ExternalSorter#mergeSort 源码如下:
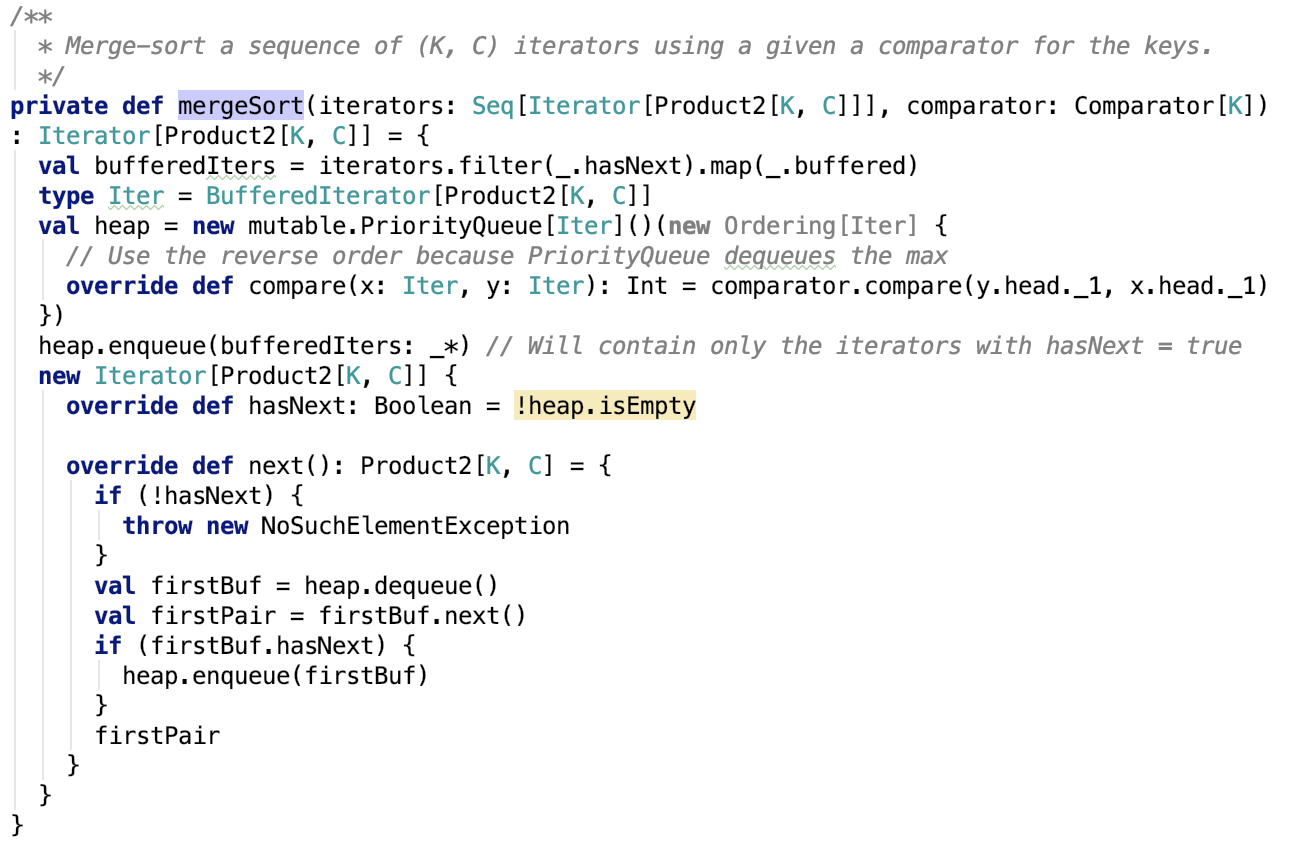
思路:使用堆排序构造优先队列,对数据进行排序,最终返回一个迭代器。每次先从堆中根据partitionID排序,将同一个partition的排到前面,每次取出一个Iterator,然后取出该Iterator中的一个元素,再放入堆中,因为可能取出一个元素后,Iterator的头节点的partitionId改变了,所以需要再次排序,就这样动态的出堆入堆,让不同Iterator的相同partition的数据总是在一起被迭代取出。注意这里的comparator在指定ordering或aggragator的时候,是支持二级排序的,即不仅仅支持分区排序,还支持分区内的数据按key进行排序,其排序器源码如下:
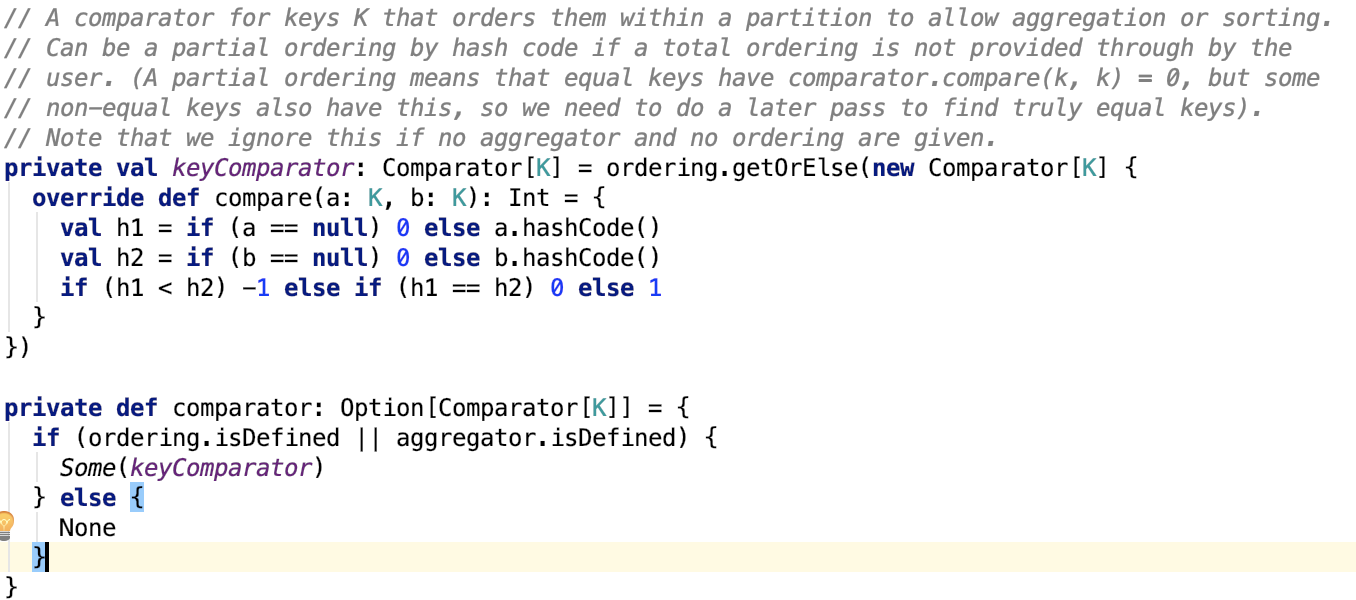

如果ordering和aggragator没有指定,则数据排序器为:

即只按分区排序,跟第二种shuffle的最终格式很类似,分区内部数据无序。
org.apache.spark.util.collection.ExternalSorter#mergeWithAggregation源码如下:

思路:如果数据整体并不要求有序,则会使用combiner将数据整体进行combine操作,最终相同key的数据被聚合在一起。如果数据整体要求有序,则直接对有序的数据按照顺序一边聚合一边迭代输出下一个元素,最终数据是整体有序的。
创建索引文件
其关键源码如下:
![]()
其思路很简单,可以参考 spark shuffle写操作三部曲之UnsafeShuffleWriter 对应部分的说明。
总结
在本篇文章中,剖析了spark shuffle的最后一种写方式。溢出前数据使用数组自定义的Map或者是列表来保存,如果指定了aggerator,则使用Map结构,Map数据结构支持map端的预聚合操作,但是列表方式的不支持预聚合。
数据每次溢出数据都进行排序,如果指定了ordering,则先按分区排序,再按每个分区内的key排序,最终数据溢出到磁盘中的临时文件中,在merge阶段,数据被SpillReader读取出来和未溢出的数据整体排序,最终数据可以整体有序的落到最终的数据文件中。
至此,spark shuffle的三种写方式都剖析完了。之后会有文章来剖析shuffle的读取操作。
不足之处:这篇文章历时比较久,也由于平时工作原因,用的都是碎片时间,可能有一些部分思路接不上,可能还有部分类没有剖析,望见谅,虽然本文有诸多问题,但是对预整体理解第三种shuffle的写方式来说,都无足轻重了。