spark 源码分析之八--Spark RPC剖析之TransportContext和TransportClientFactory剖析
TransportContext
首先官方文档对TransportContext的说明如下:
Contains the context to create a TransportServer, TransportClientFactory, and to setup Netty Channel pipelines with a TransportChannelHandler. There are two communication protocols that the TransportClient provides, control-plane RPCs and data-plane "chunk fetching". The handling of the RPCs is performed outside of the scope of the TransportContext (i.e., by a user-provided handler), and it is responsible for setting up streams which can be streamed through the data plane in chunks using zero-copy IO. The TransportServer and TransportClientFactory both create a TransportChannelHandler for each channel. As each TransportChannelHandler contains a TransportClient, this enables server processes to send messages back to the client on an existing channel.
首先这个上下文对象是一个创建TransportServer, TransportClientFactory,使用TransportChannelHandler建立netty channel pipeline的上下文,这也是它的三个主要功能。
TransportClient 提供了两种通信协议:控制层面的RPC以及数据层面的 "chunk抓取"。
用户通过构造方法传入的 rpcHandler 负责处理RPC 请求。并且 rpcHandler 负责设置流,这些流可以使用零拷贝IO以数据块的形式流式传输。
TransportServer 和 TransportClientFactory 都为每一个channel创建一个 TransportChannelHandler对象。每一个TransportChannelHandler 包含一个 TransportClient,这使服务器进程能够在现有通道上将消息发送回客户端。
成员变量:
1. logger: 负责打印日志的对象
2. conf:TransportConf对象
3. rpcHandler:RPCHandler的实例
4. closeIdleConnections:空闲时是否关闭连接
5. ENCODER: 网络层数据的加密,MessageEncoder实例
6. DECODER:网络层数据的解密,MessageDecoder实例
三类方法:
1. 创建TransportClientFactory,两个方法如下:

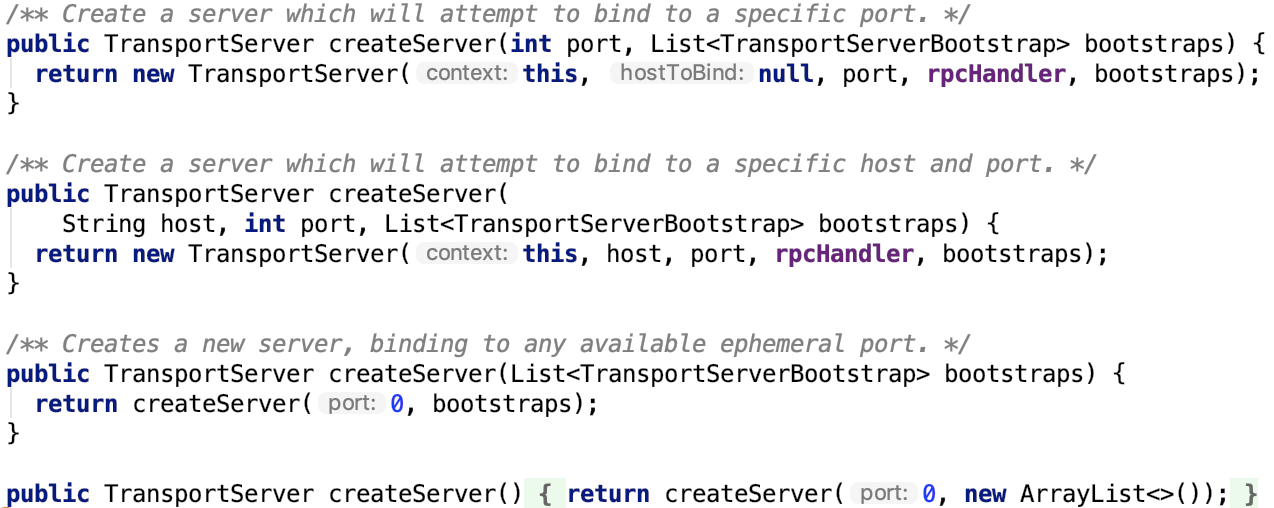
2. 创建TransportServer,四个方法如下:
3. 建立netty channel pipeline,涉及方法以及调用关系如下:

注意:TransportClient就是在 建立netty channel pipeline时候被调用的。整个rpc模块,只有这个方法可以实例化TransportClient对象。
TransportClientFactory
TransportClientFactory
使用 TransportClientFactory 的 createClient 方法创建 TransportClient。这个factory维护到其他主机的连接池,并应为同一远程主机返回相同的TransportClient。所有TransportClients共享一个工作线程池,TransportClients将尽可能重用。
在完成新TransportClient的创建之前,将运行所有给定的TransportClientBootstraps。
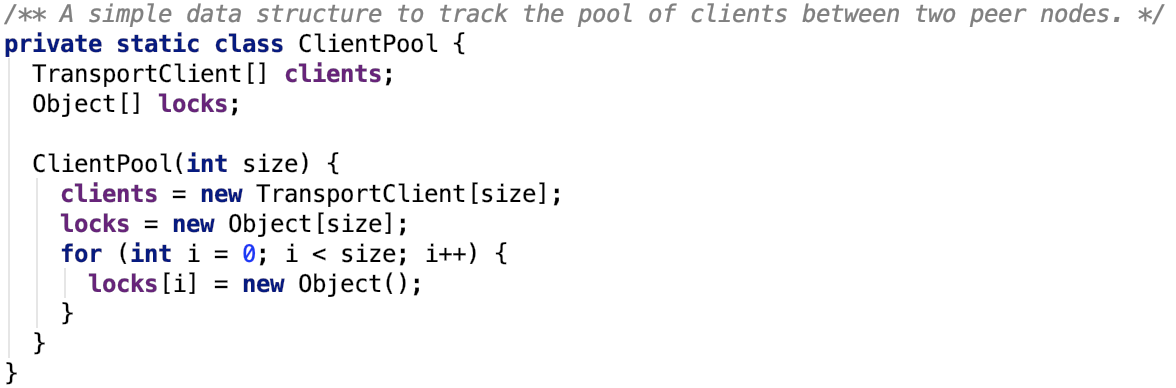
其内部维护了一个连接池,如下:
TransportClientFactory 类图如下:

TransportClientFactory成员变量如下:
1. logger 日志类
2. context 是 TransportContext 实例
3. conf 是 TransportConf 实例
4. clientBootstraps是一个 List<TransportClientBootstrap>实例
5. connectionPool 是一个 ConcurrentHashMap<SocketAddress, ClientPool>实例,维护了 SocketAddress和ClientPool的映射关系,即连接到某台机器某个端口的信息被封装到
6. rand是一个Random 随机器,主要用于在ClientPool中选择TransportClient 实例
7. numConnectionsPerPeer 表示到一个rpcAddress 的连接数
8. socketChannelClass 是一个 Channel 的Class 对象
9. workerGroup 是一个EventLoopGroup 主要是为了注册channel 对象
10. pooledAllocator是一个 PooledByteBufAllocator 对象,负责分配buffer 的 11.metrics是一个 NettyMemoryMetrics对象,主要负责从 PooledByteBufAllocator 中收集内存使用metric 信息
其成员方法比较简单,简言之就是几个创建TransportClient的几个方法。
创建受管理的TransportClient,所谓的受管理,其实指的是创建的对象被放入到了connectionPool中:

创建不受管理的TransportClient,新对象创建后不需要放入connectionPool中:

上面的两个方法都调用了核心方法 createClient 方法,其源码如下:

其中Bootstrap类目的是为了让client 更加容易地创建channel。Bootstrap可以认为就是builder模式中的builder。
将复杂的channel初始化过程隐藏在Bootstrap类内部。
至于TransportClient是在初始化channel过程中被初始化的,由于本篇文章长度限制,我们下节剖析。