什么是浅拷贝?什么是深拷贝?浅显易懂的说:假设B复制了A,如果B发生变化,A也随之变化,那么说明为浅拷贝;若B发生变化,并不会导致A也发生变化,则称之为深拷贝。
举个例子:
let a = [0,1,2]
let b = a
b[0] = 1
console.log(a,b)
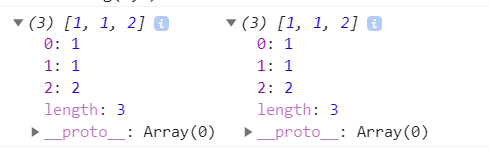
不禁疑惑,数组b复制了数组a,明明只修改了数组b,为什么数组a也随着改变呢?
此时需要引入基本数据类型和引用数据类型的概念
基本数据和引用数据
基本数据类型有哪些?
null,undefined,number,string,boolean,symbol
引用数据类型?
有常规名值对的无序对象{a:1},还有数组[1,2,3]和以及函数
有了解过基本数据类型和引用数据类型的存储方式吗?
-
基本数据类型的变量名和值都存储在栈内存中
//当执行了直接赋值时 let a = 1 let b = a//在栈内存中开辟了新的内存来保存名与值 b = 2 console.log(a,b)//1,2栈内存 name val a 1 b 1
-
引用数据类型的变量名存放在栈内存中,但是值却存放在堆内存中,栈内存会提供一个引用地址指向堆内存中的值
let a = [0,1]
let b = a
b[0] = 1
console.log(a,b)//1,1 1,1分析:复制时,只拷贝了引用地址,而并非堆内存中的值
修改时,由于a和b同时指向了同一个引用,因此两者会互相影响,也就是所谓的浅拷贝了
栈内存 堆内存 name val a 引用地址 [1,1] b 引用地址 [1,1] 不禁发出疑问:假如拷贝时,在堆内存中也能开辟新的内存来专门存放b的值,如同基本数据类型在栈内存中的表现一样,应该便能实现深拷贝了。
实现深拷贝
递归实现深拷贝
//只适用于对象和数组的深拷贝
function deepclone(targetObj){
let cloneObj = Array.isArray(targetObj) ? [] : {}
//如果目标对象为引用类型
if(targetObj && typeof targetObj === 'object') {
for(let key in targetObj){
//判断目标对象的属性是否也是引用类型,
if(targetObj[key] && typeof targetObj[key] === 'object'){
cloneObj[key] = deepclone(targetObj[key])
}else {
//如果是基本类型,那么可以直接赋值复制
cloneObj[key] = targetObj[key]
}
}
}
return cloneObj
}
let arr = [0,1,2,[0,1]]
let copy = deepclone(arr)
copy[0] = 1
copy[3][0] = 1
console.log(arr,copy)

借用JSON对象的parse和stringify
function deepClone(obj){
let _obj = JSON.stringify(obj)
let cloneObj = JSON.parse(_obj)
return cloneObj
}
let obj = {name:'mike',age:16,son:{name:'tom'}}
let copy = deepClone(obj)
copy['name'] = 'john'
copy.son.name = 'Tom'
console.log(obj,copy)
某些API所实现的深浅拷贝
Array.prototype.concat()实现数组的不完全深拷贝
let arr = [0,1,2,[1,2]]
let copy = arr.concat()
copy[0] = 1
copy[3][0] = 2
console.log(arr,copy)

Array.prototype.slice()实现数组不完全深拷贝
只能实现第一层属性的深拷贝,原因在于,方法返回一个新的数组对象
let a=[0,1,[2,3],4],
b=a.slice();
a[0]=1;
a[2][0]=1;
console.log(a,b);

Object.assign()实现的不完全深拷贝
let obj = {name:'mike',son:{name:'son'}}
let copy = Object.assign({}, obj)//因为方法返回目标对象{},实现了第一层的深拷贝
copy['name'] = 'john'
copy.son.name = 'Son'//第二层为浅拷贝了,所以修改copy对象时,obj对象的第二层也改变了
console.log(obj,copy)

深拷贝的实用性
后台返回一堆数据时,在多人开发中,我们不知道数据是否有其他的开发需求,因此我们不能直接修改数据,深拷贝可以使我们安心操作拷贝的数据,而无需担心修改原数据带来的隐性问题。