将sqlserver Profile收集到的trace 比如 duration >5000ms 的trace 文件 导入到sample 表分析或者用查询优化器顾问分析

2.可以用DMV 动态管理视图来查询分析 sqlserver性能,使用情况,比如 查询最近50条最耗时的sql.

--总耗CPU最多的前个SQL:
SELECT TOP 20
total_worker_time / 1000 AS [总消耗CPU 时间(ms)] ,
execution_count [运行次数] ,
qs.total_worker_time / qs.execution_count / 1000 AS [平均消耗CPU 时间(ms)] ,
last_execution_time AS [最后一次执行时间] ,
max_worker_time / 1000 AS [最大执行时间(ms)] ,
SUBSTRING(qt.text, qs.statement_start_offset / 2 + 1,
( CASE WHEN qs.statement_end_offset = -1
THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset ) / 2 + 1) AS [使用CPU的语法] ,
qt.text [完整语法] ,
qt.dbid ,
dbname = DB_NAME(qt.dbid) ,
qt.objectid ,
OBJECT_NAME(qt.objectid, qt.dbid) ObjectName
FROM sys.dm_exec_query_stats qs WITH ( NOLOCK )
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
WHERE execution_count > 1
ORDER BY total_worker_time DESC;
--平均耗CPU最多的前个SQL:
SELECT TOP 20
total_worker_time / 1000 AS [总消耗CPU 时间(ms)] ,
execution_count [运行次数] ,
qs.total_worker_time / qs.execution_count / 1000 AS [平均消耗CPU 时间(ms)] ,
last_execution_time AS [最后一次执行时间] ,
min_worker_time / 1000 AS [最小执行时间(ms)] ,
max_worker_time / 1000 AS [最大执行时间(ms)] ,
SUBSTRING(qt.text, qs.statement_start_offset / 2 + 1,
( CASE WHEN qs.statement_end_offset = -1
THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset ) / 2 + 1) AS [使用CPU的语法] ,
qt.text [完整语法] ,
qt.dbid ,
dbname = DB_NAME(qt.dbid) ,
qt.objectid ,
OBJECT_NAME(qt.objectid, qt.dbid) ObjectName
FROM sys.dm_exec_query_stats qs WITH ( NOLOCK )
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS qt
WHERE execution_count > 1
ORDER BY ( qs.total_worker_time / qs.execution_count / 1000 ) DESC;
找出执行时间最长的10条SQL(适用于SQL SERVER 2005及其以上版本)
SELECT TOP 10
( total_elapsed_time / execution_count ) / 1000 N'平均时间ms' ,
total_elapsed_time / 1000 N'总花费时间ms' ,
total_worker_time / 1000 N'所用的CPU总时间ms' ,
total_physical_reads N'物理读取总次数' ,
total_logical_reads / execution_count N'每次逻辑读次数' ,
total_logical_reads N'逻辑读取总次数' ,
total_logical_writes N'逻辑写入总次数' ,
execution_count N'执行次数' ,
creation_time N'语句编译时间' ,
last_execution_time N'上次执行时间' ,
SUBSTRING(st.text, ( qs.statement_start_offset / 2 ) + 1,
( ( CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset ) / 2 ) + 1) N'执行语句' ,
qp.query_plan
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE SUBSTRING(st.text, ( qs.statement_start_offset / 2 ) + 1,
( ( CASE statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset ) / 2 ) + 1) NOT LIKE '%fetch%'
ORDER BY total_elapsed_time / execution_count DESC;
----查看当前表的所有索引
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID ('tStudent'),null,null,null)
-----测试
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
SET STATISTICS PROFILE ON
SELECT * FROM dbo.tStudent WHERE
studentId='1001'
AND name='T997'
AND createDate>'2017-06-30 13:49:35.510'
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.tStudent WHERE
studentId='1001'
AND createDate>''
AND name='T997'
ORDER BY name
SET STATISTICS IO OFF
2017-06-30 13:49:35.510
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.tStudent WHERE
studentId='1001'
or name='T997'
--ORDER BY name
SET STATISTICS IO OFF
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.tStudent WHERE
studentId='1001'
and sex='男'
--ORDER BY name
SET STATISTICS IO OFF
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.tStudent WHERE
sex='男' and
studentId='1001'
--ORDER BY name
SET STATISTICS IO OFF
DBCC DROPCLEANBUFFERS
SELECT * FROM dbo.tStudent WHERE
CONVERT(NVARCHAR(20),CreateDate,120) >'2017-06-30 13:49:35.510'
AND rowNumber BETWEEN 100 AND 2000
--ORDER BY name
SET STATISTICS IO OFF
CREATE NONCLUSTERED INDEX PK_Non_Name ON dbo.tStudent(name)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname ON dbo.tStudent(studentId,name)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname2 ON dbo.tStudent(studentId,name,createDate)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname3 ON dbo.tStudent(studentId,createDate,name)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname5 ON dbo.tStudent(studentId,sex)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname6 ON dbo.tStudent(sex,studentId)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname7 ON dbo.tStudent(id,createDate)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname8 ON dbo.tStudent(rowNumber)
CREATE NONCLUSTERED INDEX PK_Non_StIdAndname9 ON dbo.tStudent(rowNumber,createDate)
DROP INDEX tStudent.PK_Non_StIdAndname2
DROP INDEX tStudent.PK_Non_StIdAndname3
DROP INDEX tStudent.PK_Non_StIdAndname4
DROP INDEX tStudent.PK_Non_StIdAndname5
DROP INDEX tStudent.PK_Non_StIdAndname6
DROP INDEX tStudent.PK_Non_StIdAndname7
DROP INDEX tStudent.PK_Non_StIdAndname9
---重整索引
ALTER INDEX [PK_Non_StIdAndname9] ON tStudent
REORGANIZE
GO
ALTER INDEX [PK_Non_StIdAndname8] ON tStudent
REORGANIZE
GO
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID ('tStudent'),null,null,null)

-----重整索引,删除碎片
-- 重整 "ordDemo" 表上的 "idx_refno" 索引ALTER INDEX [idx_refno] ON [ordDemo]REORGANIZEGO-- 重整 ordDemo 表上所有索引ALTER INDEX ALL ON [ordDemo]REORGANIZEGO-- 重整 AdventureWorks2012 数据库中 ordDemo 表上所有索引DBCC INDEXDEFRAG ('AdventureWorks2012','ordDemo')GO-- 重整 AdventureWorks2012 数据库中 ordDemo 表上索引 idx_refnoDBCC INDEXDEFRAG ('AdventureWorks2012','ordDemo','idx_refno')GO |
注意:执行该操作的用户必须是该表的所有者,或是该服务器的sysadmin一员,或是该数据库的db_owner / db_ddladmin。
5.DBA 日志维护任务

6 在备用服务器上 dbcc checkDB.昂贵的任务。有可能一天都运行不完。

7 多种方式,自动更新,也可手工通过命令。
1.update statistics [dbo].[tStudent]
2.
USE [test]
GO
EXEC sp_updatestats;
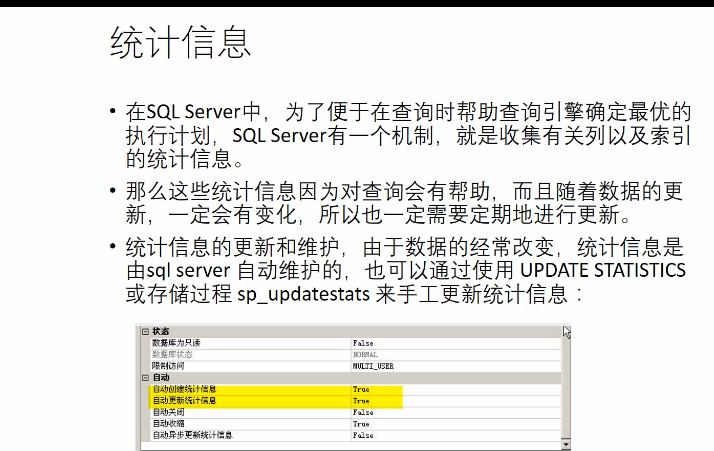
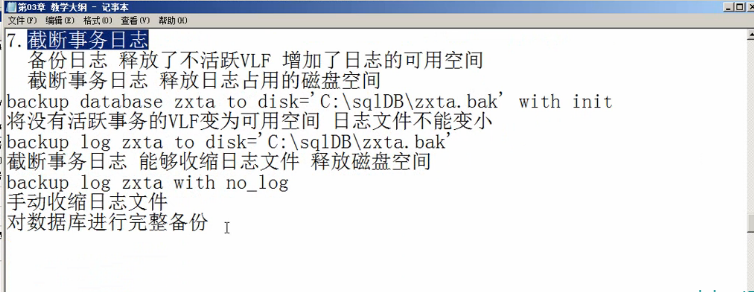
7.备份


8 dbcc show_statistics(tstudent,sss) 显示统计信息
dbcc showcontig(tstudent) 显示页面信息 碎片信息
9 第三方工具 恢复删除数据
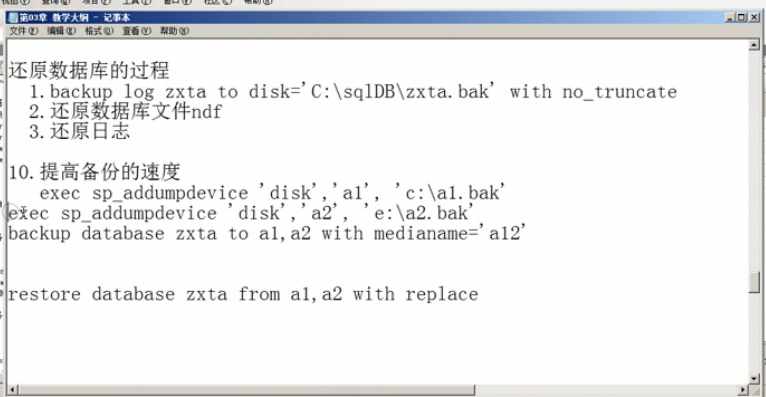
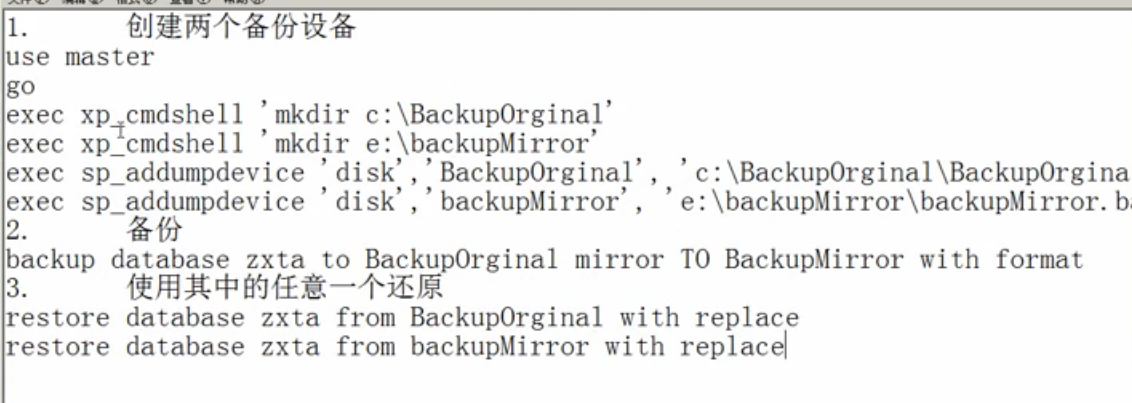
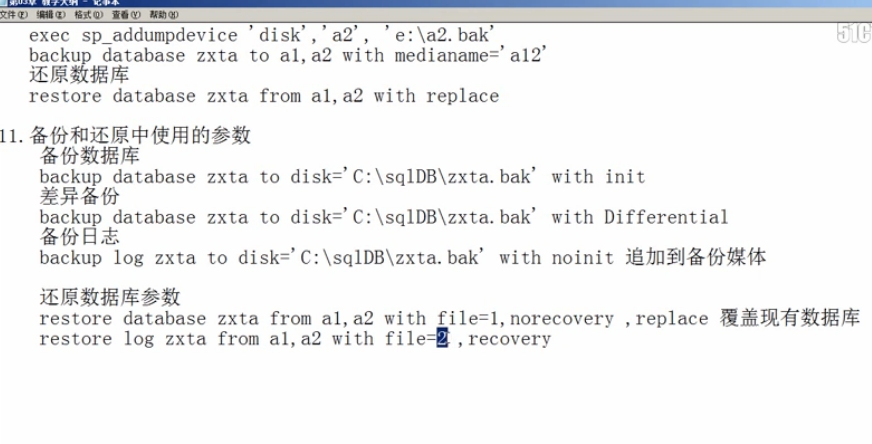
10.备份还原
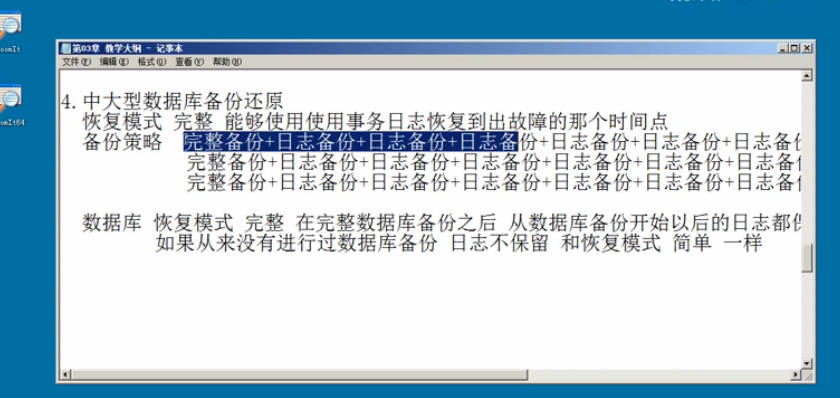
10.备份还原数据库
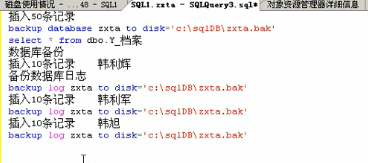
a.

b.
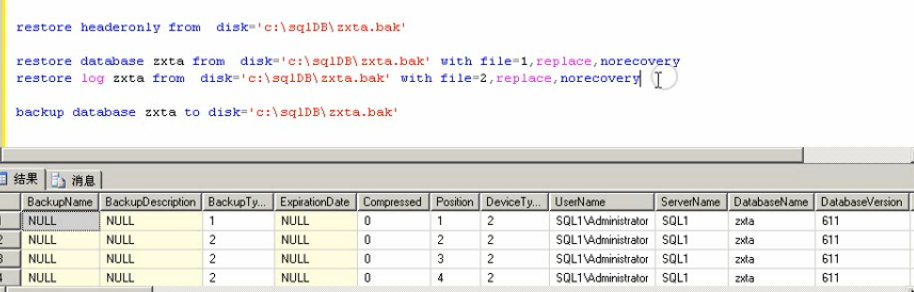
c.恢复到某个时间点
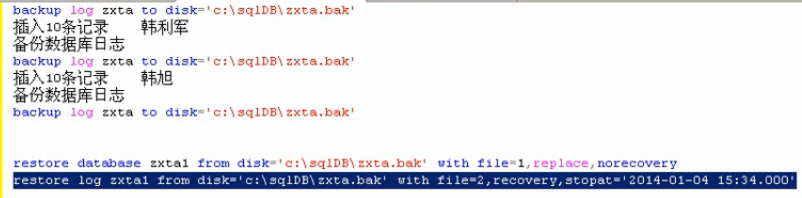
d.