1.作业头
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/SE2020-2 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/SE2020-2/homework/11769 |
| 这个作业的目标 | 知道怎么样在程序中读取文件,对文件的类型与作用有一个了解,对自己的程序在运行时间上进行一些了解和优化 |
| 学号 | 20209123 |
一、本周教学内容&目标
第6章 回顾数据类型和表达式,第12章 文件
二、本周作业(总分:50分)
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
代码图片:


####解题思路:
这道题目是要求我们给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数,
题目中要求我们写出一个函数f(N),所以,我们就可以自定义一个函数,我就自定义了int hanshu(int N),int是整型,
然后,我们就可以开始自定义变量,在主函数中我们可以用int型定义N,当然,如果数据太大,我们也可以用long int或
long long int型,输入N,打印主函数输出的文件,然后,在自定义函数中,我们自定义变量count, i, time,因为我们
题目的要求是求返回1到N之间出现的”1“的个数,所以我们可以很明确的知道这里要用循环,因为不知道N是多少,所以我选
择运用了for循环,为了避免数据混乱,所以,我们可以将i的数值赋值给time,之后,我们就可以运算1的个数了,再用一个
while循环,用count++,计算1的个数,因为是取余,所以,每一次循环我们都要将time除以10。
测试数据:
| 输入数据 | 输出数据 |
|---|---|
| 0 | f(0)=0 |
| 10 | f(10)=2 |
| 100 | f(100)=21 |
| 1000 | f(1000)=301 |
| 10000 | f(10000)=4001 |
| 100000 | f(100000)=50001 |
| 1000000 | f(1000000)=600001 |
2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大(5分)
| 输入数据 | 输出数据 | 运算时间 |
|---|---|---|
| 0 | f(0)=0 | 1.017 |
| 10 | f(10)=2 | 1.978 |
| 100 | f(100)=21 | 2.381 |
| 1000 | f(1000)=301 | 3.564 |
| 10000 | f(10000)=4001 | 4.144 |
| 100000 | f(100000)=50001 | 4.317 |
| 1000000 | f(1000000)=600001 | 5.227 |
3.思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。(10分)

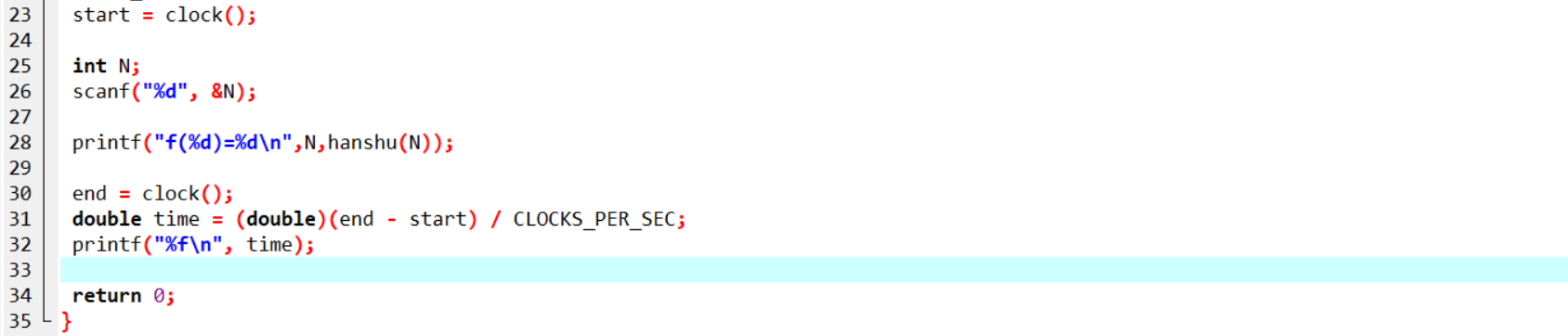
如何减少运算时间:
1.可以将数据先存储在文件中,在需要用的时候我们再去调用。这样可以减少内存的占用。
2.分析和剔除代码中的水分,将一些不必要的代码语句给剔除。
3.尽量将循环最简化,因为循环是真的很耗费时间的。
如何在原有算法基础上的改进算法和改进思路:
1.首先,我们可以从数据类型改起,不同的数据类型所运算的时间是有很大的不同的,像long long int的运算时间就比long int的要长,long int 的运算时间就比int类型的运算时间要长,所以,在数据可以容纳的情况下我们可以尽量用比较小的数据类型。
2.然后是循环,越多的循环嵌套运算的时间越久,我们可以优化循环,尽量减少循环的嵌套,优化代码。
满足条件”f(N)=N“的最大的N是:1111111110。
2.2 将上题中多组测试数据写入文件,并给出测试程序以检测你的代码有没有问题,贴出你的代码、运行结果和文件内容。(5分)
代码:

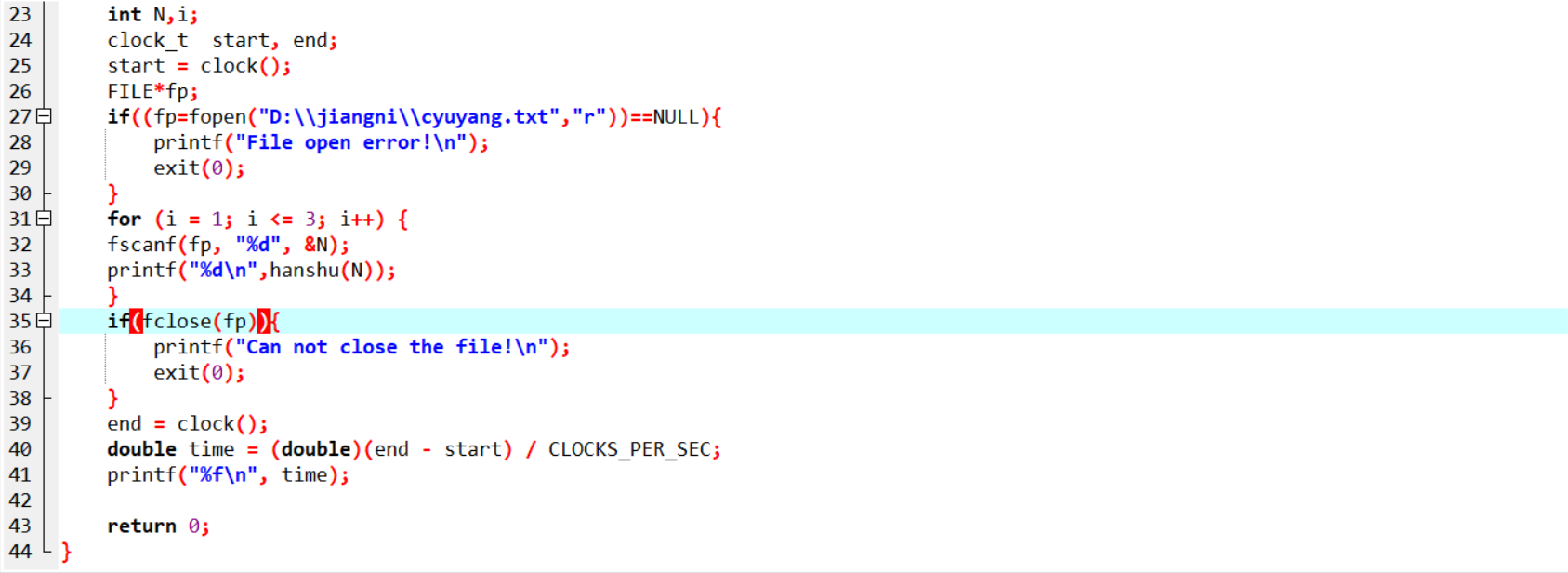
运行结果:

文件内容:

2.3 用自己的语言回答两个问题,并给出所查阅资料的引用(10分)
1.什么是文件缓冲系统?工作原理如何?
文件缓冲系统:
为了提高数据存取访问的效率,C程序对文件的处理采用缓冲文件系统的方式进行。根据文件缓冲的特性,把文件系统分为缓冲文件系统与非缓冲文件系统,对于缓冲文件系统,在进行文件操作时,系统自动为每一个文件分配一块文件内存缓冲区(内存单元),当程序要向磁盘文件写入数据时,先把数据存入缓冲区,然后再由操作系统把缓冲区的数据真正存入磁盘。文件缓冲区不是由系统自动分配,而需要编程者在程序中C语句实现分配。
工作原理:
缓冲文件系统规定磁盘与内存缓冲区之间的交互由操作系统自动完成,缓冲文件系统将会自动在内存中为被操作的文件开辟一块连续的内存单元(如512B)作为文件缓冲区。当要把数据存储到文件中时 首先把数据写入文件缓冲区,一旦写满了512B,操作系统自动把全部数据写入磁盘一个扇区,然后把文件缓冲区清空,新的数据继续写入到文件缓冲区,当要从文件读取数据时,系统首先自动把一个扇区的文件导入文件缓冲区,供C程序逐个读入数据,一旦512B数据都被读入,系统自动把一个扇区的内容导入文件缓冲区,供C程序继续读入新数据。
2.什么是文本文件和二进制文件?
文本文件:
一种按数据存储的编码形式分类的数据文件,以字符ASCLL码值进行存储与编码的文件,其文件内容就是字符,C语言源程序是文本文件。
二进制文件:
另一种种按数据存储的编码形式分类的数据文件,时存储二进制数据的文件,C程序的目标文件和可执行文件是二进制文件。
<查阅资料>
1.C语言程序设计第三版。
2.百度
2.4 请给出本周学习总结(15分)
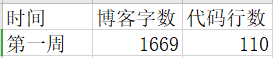
1 学习进度条(5分)
| 周/日期 | 这周所花的时间 | 代码行 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
| 3/1-3/7 | 10小时 | 110行 | 回顾了数据类型和表达式,问文件 | 对于文件这一章的内容还不是特别的清楚了解,尤其是怎么样将文本文件应用到代码中去 |
2 累积代码行和博客字数(5分)
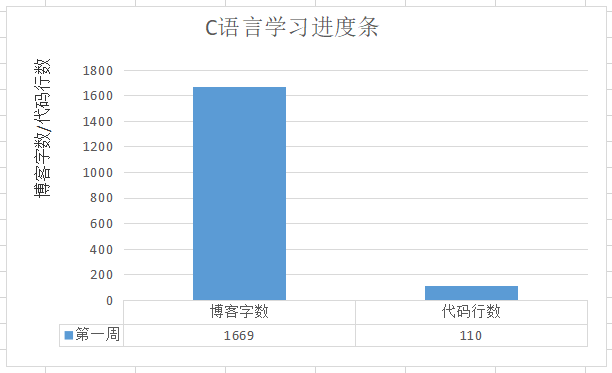
3 学习内容总结和感悟(5分)
学习内容总结
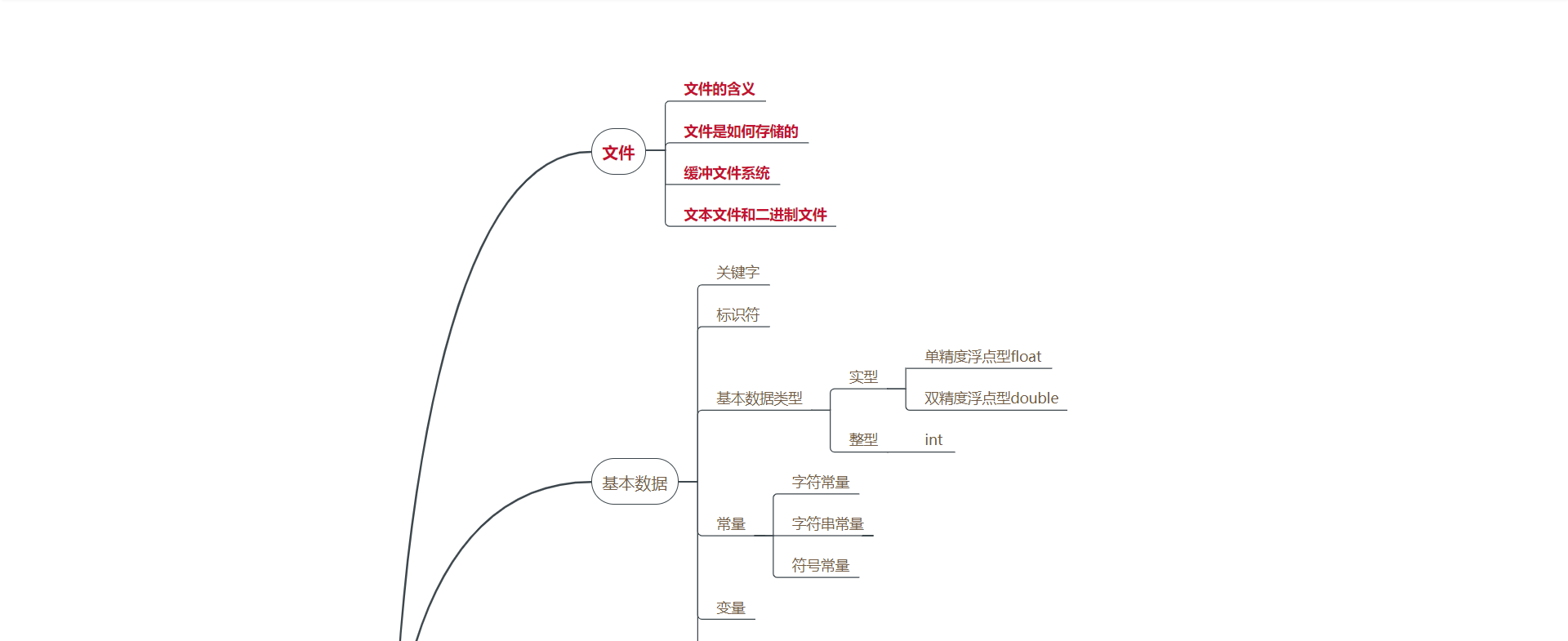
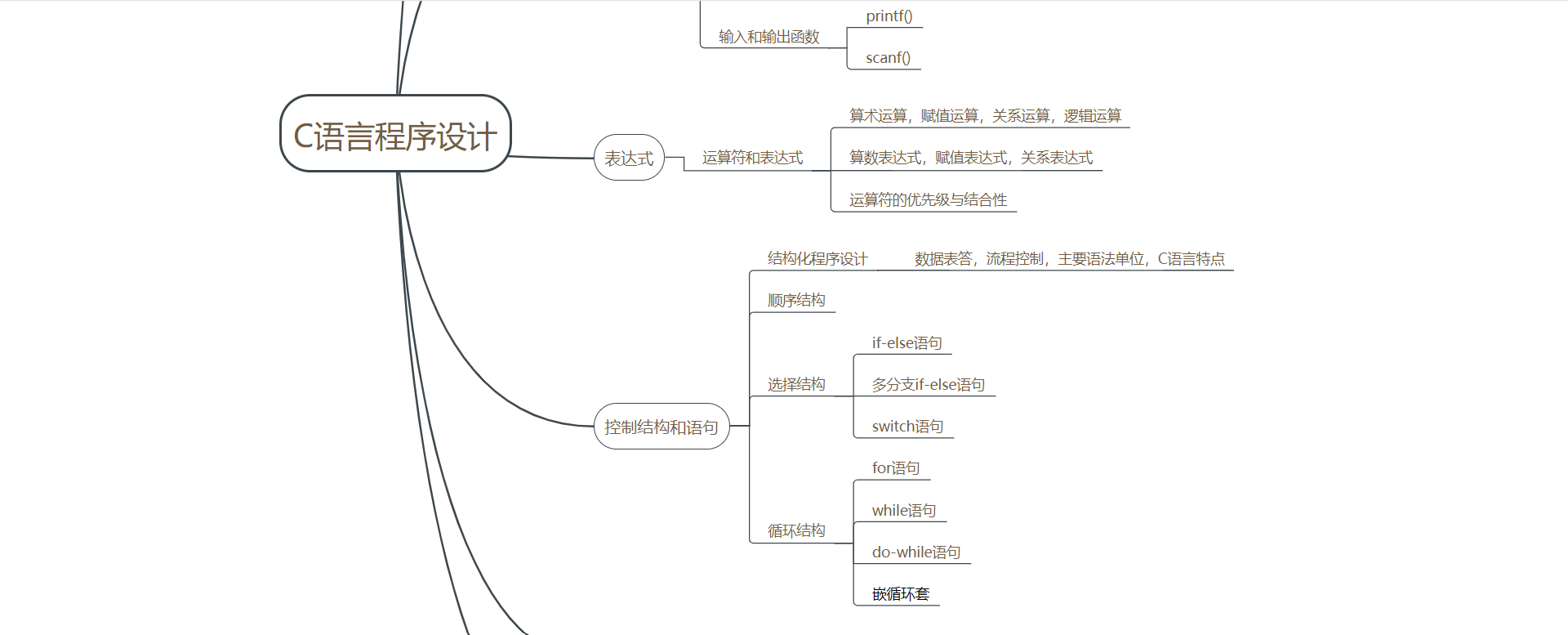

学习体会感悟
1.这是新学期的第一周,感觉对于上学期所学习的知识还是有的忘记了,所以,要通过多多看看书来对知识点进行一个巩固。
2.在上一学期,我觉得我自己还是有做的比较不好的地方,这一学期,应该加倍努力去学习,上课也应该更加集中精力的去听讲,然后课后要多多注意知识点的巩固,不要就满足于课上所学,多多去拓展一下自己的知识。
3.这一周所学的文件其实我还是有好多不太明白的,就自己多看看书,找找资料去巩固学习一下吧。
4.新的学期,新的期待,所以,我们还是努力去奋斗吧,C语言这门可是自己的专业课,虽然感觉有点难,学的时候有点累,但是,还是应该努力去学习吧,因为对于我们的专业,这门课程可是很重要的。平时没有事的时候就可以多去图书馆学习学习。