阅读目录
当我们试图从新浪微博抓取数据时,我们会发现网页上提示未登录,无法查看其他用户的信息。
模拟登录是定向爬虫制作中一个必须克服的问题,只有这样才能爬取到更多的内容。
实现微博登录的方法有很多,一般我们在模拟登录时首选WAP版。
因为PC版网页源码中包括很多的js代码,提交的内容也更多,不适合机器模拟登录。
我们实现微博登录的大体思路是这样的:
- 用抓包工具把正常登录时要提交的字段都记录下来;
- 模拟提交这些字段;
- 判断是否登录成功;
原理很简单,让我们一步一步来实现吧。
一.抓包利器Fiddler
在电脑和互联网之间的通信是通过不同的数据包收发来实现的。
Fiddler可以从中间对数据进行拦截,拷贝一份数据以后再将数据发送给目的端。(这也是为什么说咖啡馆的公共WIFI不安全的原因)
同类的还有WireShark。为何这儿不用WireShark呢?
Wireshark太过于专业了,它可以实现抓取各种包,抓下来的包也很乱,针对性没Fiddler那么强。
- 下载安装
1.下载地址:http://www.telerik.com/fiddler
2.安装方法:fiddler依赖.Net环境,如果已经有则无需配置,直接点击下一步就行。
- 使用方法
1.启动Fiddler
2.配置Fiddler
点击左上角的“ WinConfig”,找到你使用的浏览器并勾选,点击“Save Changes”
3.使用Fiddler开始抓包
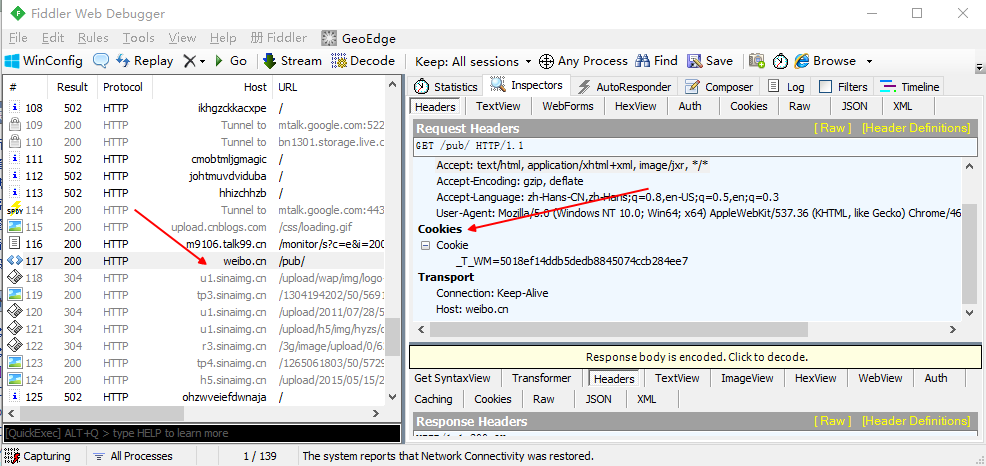
打开浏览器访问WAP版新浪微博网站weibo.cn
Fiddler窗口左侧找到weibo.cn /pub/的数据包,并双击,这时我们就能够在右侧看到抓取到的信息.
找到Cookies字段,这正是我们需要的.
二.Cookies与保持登录
- 关于Cookies
维基百科是这样解释的:
Cookie(复数形态Cookies),中文名称为“小型文本文件”或“小甜饼”,指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。
通俗来说就是服务器端为了确认用户终端的身份而设定的一种加密标识,它是存储在本地终端上的。
当然,随着Cookies技术的发展,Cookies的作用已经不止于用户身份标识。
当登陆一个网站时,网站往往会请求用户输入用户名和密码,并且用户可以勾选“下次自动登录”。
如果勾选了,那么下次访问同一个网站时,用户会发现没输入用户名和密码就已经登录了。
这正是因为前一次登陆时服务器发送了包含登录凭据(用户名+密码的某种加密形式)的Cookie到用户的硬盘上。
第二次登录时,如果该Cookies尚未到期,浏览器会发送该Cookies,服务器验证凭据,于是不必输入用户名和密码就让用户登录了。
三.Cookies模拟登录
下面将介绍使用 Fiddler 获取新浪微博 Cookies,然后使用 Requests 提交 Cookies 从而实现模拟登录。
- 抓取登录数据包
使用Fiddler抓取数据包.
- 获取Cookies
打开新浪微博WAP版页面(weibo.cn),点击登录,然后填写账号密码,勾选“记住登录状态”,切记要勾选此项.
登录成功后,从Fiddler中选择最新的那个weibo.cn,然后复制Cookies字段的内容,填写到代码内.
代码如下:

#!/usr/bin/env python
#coding=utf8
""" Simulate a user login to Sina Weibo with cookie.
You can use this method to visit any page that requires login.
"""
import urllib2
import re
# get your cookie from Fiddler11
cookie = 'your-cookie'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:24.0) Gecko/20100101 Firefox/24.0',
'cookie': cookie
}
def visit():
url = 'http://weibo.com'
req = urllib2.Request(url, headers=headers)
text = urllib2.urlopen(req).read()
# print the title, check if you login to weibo sucessfully
pat_title = re.compile('<title>(.+?)</title>')
r = pat_title.search(text)
if r:
print(r.group(1))
if __name__ == '__main__':
visit()
四.使用 Post 提交数据的方法实现模拟登录
由于使用Cookies登录存在很多的弊端,一般我们都使用Post提交数据的方法来实现模拟登录.
- 通过Fiddler来抓取http数据包来分析该网站的登录流程;
- 分析抓到的post包的数据结构和header,要根据提交的数据结构和heander来构造自己的post数据和header;
- 构造自己的HTTP数据包,并发送给指定url;
- 通过urllib2等几个模块提供的API来实现request请求的发送和相应的接收;
大部分网站登录时需要携带cookie,所以我们还必须设置cookie处理器来保证cookie.
notice:如果遇到登录后网站重定向到其他url这种情况,我们可以使用chrome的审查元素功能找出重定向后的网站url和该网站的提交数据,再次使用post方法就行.
代码如下:
#!/usr/bin/python
import HTMLParser
import urlparse
import urllib
import urllib2
import cookielib
import string
import re
#登录的主页面
hosturl = '******' //自己填写
#post数据接收和处理的页面(我们要向这个页面发送我们构造的Post数据)
posturl = '******' //从数据包中分析出,处理post请求的url
#设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie
cj = cookielib.LWPCookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
urllib2.install_opener(opener)
#打开登录主页面(他的目的是从页面下载cookie,这样我们在再送post数据时就有cookie了,否则发送不成功)
h = urllib2.urlopen(hosturl)
#构造header,一般header至少要包含一下两项。这两项是从抓到的包里分析得出的。
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1',
'Referer' : '******'}
#构造Post数据,他也是从抓大的包里分析得出的。
postData = {'op' : 'dmlogin',
'f' : 'st',
'user' : '******', //你的用户名
'pass' : '******', //你的密码
'rmbr' : 'true', //特有数据,不同网站可能不同
'tmp' : '0.7306424454308195' //特有数据,不同网站可能不同
}
#需要给Post数据编码
postData = urllib.urlencode(postData)
#通过urllib2提供的request方法来向指定Url发送我们构造的数据,并完成登录过程
request = urllib2.Request(posturl, postData, headers)
print request
response = urllib2.urlopen(request)
text = response.read()
print text