目录
前文列表
Openstack 实现技术分解 (1) 开发环境 — Devstack 部署案例详解
扩展阅读
Documentation — Cloud-Init 0.7.9 documentation
系统环境
- Devstack-M
- Ubuntu TLS 14.04
前言
Cloud-Init + metadata + userdata 是一套初始化定制云平台虚拟机的解决方案, 最主要解决了下列功能需求:
- 能够自动化的完成对云平台虚拟机的初始设置, EG. set-hostname/set-ipv4/set-disk-size/upgrade/exec-script 等等
- 支持云平台与虚拟机的通信, 以此来获取虚拟机的具体信息
简单来说就是能够 注入/获取 虚拟机的信息, 并以此衍生出对虚拟机的初始化定制能力. 其生产价值类似于无人值守技术, 避免了单独为每一台虚拟机进行人工初始化的繁琐.
Cloud-init
Everything about cloud-init, a set of python scripts and utilities to make your cloud images be all they can be!
Cloud-Init 是一组 Python Script 的集合, 是一个能够定制 Cloud Images 的实用工具.
所以 Cloud-init 一般会被包含在用于启动云平台虚拟机的 Images 文件中, 并且使用该镜像启动虚拟机时, Cloud-init 应该是自启动的, 因为其工作在虚拟机的启动过程中, 对虚拟机进行定制化的初始配置.
安装 Cloud-init 方法非常简单, 基本上常规的系统发行版都有原生的软件源, EG. ubuntu 安装:
sudo apt-get install cloud-initNOTE: Cloud-init 安装在虚拟机中, 然后再将该虚拟机制作成有如 qcow2 格式的 Image 文件.
那么, 第一个问题: Cloud-init 是怎么定制虚拟机配置的呢?
答案就是 Cloud-init 的配置文件 cloud.cfg.
Cloud-init 的配置文件
一般我们也只需要关心 Cloud-init 配置文件的定义, /etc/cloud/cloud.cfg:
stack@fanguiju-dev:~/devstack$ cat /etc/cloud/cloud.cfg | grep -v ^# | grep -v ^$
users:
- default
disable_root: true
preserve_hostname: false
cloud_init_modules:
- migrator
- seed_random
- bootcmd
- write-files
- growpart
- resizefs
- set_hostname
- update_hostname
- update_etc_hosts
- ca-certs
- rsyslog
- users-groups
- ssh
cloud_config_modules:
- emit_upstart
- disk_setup
- mounts
- ssh-import-id
- locale
- set-passwords
- grub-dpkg
- apt-pipelining
- apt-configure
- package-update-upgrade-install
- landscape
- timezone
- puppet
- chef
- salt-minion
- mcollective
- disable-ec2-metadata
- runcmd
- byobu
cloud_final_modules:
- rightscale_userdata
- scripts-vendor
- scripts-per-once
- scripts-per-boot
- scripts-per-instance
- scripts-user
- ssh-authkey-fingerprints
- keys-to-console
- phone-home
- final-message
- power-state-changeCloud-Init 根据配置文件的内容, 来定制虚拟机配置, 其中最主要配置项的就是下列三个模块列表:
- cloud_init_modules
- cloud_config_modules
- cloud_final_modules
在虚拟机启动时, 会顺序的根据模块列表中含有的各个模块的变量值来对其进行配置, EG. 模块列表 cloud_init_modules 中包含的模块 update_etc_hosts (/usr/lib/python2.7/dist-packages/cloudinit/config/cc\_update\_etc\_hosts.py). 从该模块的代码可以看出其能够配置虚拟机的 hostname/fqdn/manage_etc_hosts 等信息. Cloud-Init 首先会尝试从配置文件 /etc/cloud/cloud.cfg 读取变量 hostname/fqdn/manage_etc_hosts 的值, 如果没有定义, 则尝试从其他的数据源中获取并实现配置. EG. Openstack 可以通过 Metadata 来获取 hostname 等变量值.
NOTE 1: 除此之外, Cloud-Init 还会按照上述模块列表的顺序来进行配置, 这是因为有些模块的执行对虚拟机操作系统当前的状态是有要求的, 后面模块的配置可能需要前面模块的配置做支撑.
NOTE 2: 而且, 模块列表中的模块具有多种运行模式:
- per-once: 仅执行一次, 在执行完毕之后会在 sem 目录中创建一个信号文件, 防止在下次启动虚拟机时重复执行.
- per-always: 每次启动都会执行
- per-instance: 每一个虚拟机都会执行
EG.
cloud_final_modules:
- scripts-per-once
- scripts-per-boot
- scripts-per-instance配置文件 cloud.cfg 更相信的用法请查阅官网, 一般而言, 默认的就够用了.
第二个问题: Cloud-init 定制虚拟机操作系统配置时, 配置项目的值, 从哪里获取?
答案就是 metadata/userdata
metadata & userdata
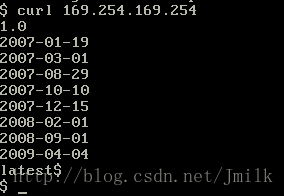
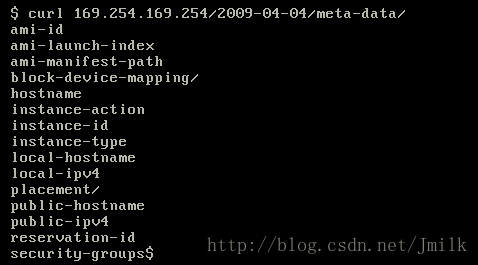
metadata 是一个数据源, 在 Openstack 中是由 nova-api service 提供的, 一般我们会在虚拟机中通过IP 169.254.169.254 来获取.
选择一个版本
选择一个配置项目

显然, Cloud-init 能够通过访问这些 URL 来获取其所需要的信息, 然后再进行配置. 但是需要说明的一点是 169.254.169.254 这个 IP 实际是不存在的, 本质上提供 metadata 的是 nova-api service, 所以通常都需要设定防火墙 DNAT 将 169.254.169.254 映射到 nova-api-service-ip:port 这个 IP.
metadata 和 userdata 的区别
其实 userdata 与 metadata 本质上都是提供配置信息的数据源, 使用了相同的信息注入机制, 只是两者代表了不同的信息类型而已:
metadata 主要提供了虚拟机的常用属性, EG. hostname/network/SSH/…, 其以 key/value 的形式进行注入, 所以非常适合应用到 REST 的场景中.
userdata 主要提供了 Shell 相关的 CLI 和 Script 等, 其通过文件的方式进行注入, 支持多种文件格式(EG. gzip/Bash/cloud-init/…).
所以, 两者的区别仅在于虚拟机在获取到信息后, 对两者的处理方式不尽相同而已.
第三个问题: metadata 和 userdata 含有的配置信息是怎么被注入到虚拟机中的?
答案就是 ConfigDrive/RESTful API
metadata 的服务机制
ConfigDrive
手动指定使用 ConfigDrive:
nova boot --config-drive=true ...启动虚拟机时, 使用 --config-drive=true 就是使用 ConfigDrive 机制来注入 metadata 信息.
修改配置文件默认使用 ConfigDrive:
vim /etc/nova/nova.conf
[DEFAULT]
...
force_config_drive = TrueConfigDrive 机制: OpenStack 会将 metadata 信息写入虚拟机的特殊设备中, 然后在虚拟机启动时, 会将该设备挂载到虚拟机上并由 Cloud-init 读取内含的 metadata 信息, 从而实现信息注入.
例如, 初始化定制 Openstack 默认支持的 Libvirt 虚拟机配置时, OpenStack 就会将 metadata 写入虚拟机的 vdisk 文件中, 并将 vdisk 指定为 cdrom 设备.

我们启动一个测试用的 Libvirt 虚拟机, 其 id 为 30ba8cc0-b2f9-4e38-9a27-6bfa9d82f5f2. 然后找到该虚拟机的 XML 文件, 其中含有以下配置内容:
vim /opt/stack/data/nova/instances/30ba8cc0-b2f9-4e38-9a27-6bfa9d82f5f2/libvirt.xml
<disk type="file" device="cdrom">
<driver name="qemu" type="raw" cache="none"/>
<source file="/opt/stack/data/nova/instances/30ba8cc0-b2f9-4e38-9a27-6bfa9d82f5f2/disk.config"/>
<target bus="ide" dev="hdd"/>
</disk>所以, 这里的 cdrom 设备就是以 ConfigDrive 方式进行 metadata 信息注入所使用到的特殊设备.
但是需要注意的是: 显然, 不同的底层 hypervisor 支撑, 其所挂载的设备类型也不尽相同.
在虚拟机中查看 metadata 信息:
ubuntu@auto-dep-db:~$ sudo mount /dev/disk/by-label/config-2 /mnt/
mount: block device /dev/sr0 is write-protected, mounting read-only
ubuntu@auto-dep-db:~$ cd /mnt/
ubuntu@auto-dep-db:/mnt$ ls
ec2 openstack
ubuntu@auto-dep-db:/mnt$ cd openstack/
ubuntu@auto-dep-db:/mnt/openstack$ ls
2012-08-10 2013-04-04 2013-10-17 2015-10-15 latest
ubuntu@auto-dep-db:/mnt/openstack$ cd 2015-10-15/
ubuntu@auto-dep-db:/mnt/openstack/2015-10-15$ ls
meta_data.json network_data.json user_data vendor_data.json
ubuntu@auto-dep-db:/mnt/openstack/2015-10-15$ vim user_data其中 user_data 文件就是我们在创建虚拟机时, 指定需要执行的脚本文件.
Metadata RESTful
Openstack 中的虚拟机也可以通过 RESTful API 来获取 metadata 信息, 提供该服务的组件为 nova-api-metadata service + neutron-metadata-agent + neutron-ns-metadata-proxy.
注意, 如果在 Nova-Network 网络模式中后两个服务是不存在也不需要的.
Nova-api-metadata: 负责接收并处理虚拟机发出的 REST API 请求(EG.curl 169.254.169.254), 从 HTTP Request Header 中能够获得获得虚拟机 id, 继而从 database 中读取虚拟机的 metadata 信息并返回结果给虚拟机.
Neutron-metadata-agent: 负责将自身节点中的虚拟机发出的 metadata 请求转发到运行 nova-api-metadata 服务的节点中, neutron-metadata-agent 会将虚拟机 id 和 project id 添加到 HTTP Request Header, 最后由 nova-api-metadata 会根据这些信息到 database 中获取 metadata 并返回结果给虚拟机.
Neutron-ns-metadata-proxy: 为了解决 Node 中的物理网段和 Project 中的虚拟网段重复的问题, OpenStack 引入了 network namespace 的概念, 每个 namespace 都是独立的, 其包含了各自拥有的 Route 和 DHCP Server. 由于虚拟机的 metadata 请求都是以 Route 和 DHCP Server 作为网络出口的, 所以需要通过 neutron-ns-metadata-proxy 来打通不同的 namespace, 让该请求在不同的 namespace 间跳转, 其实现原理是利用了在 Unix domain socket 基础之上的 HTTP 技术, 并在 HTTP Request Header 中添加
X-Neutron-Router-ID和X-Neutron-Network-ID字段信息, 使得 neutron-metadata-agent 能够定位发出请求的虚拟机并获取其 id.
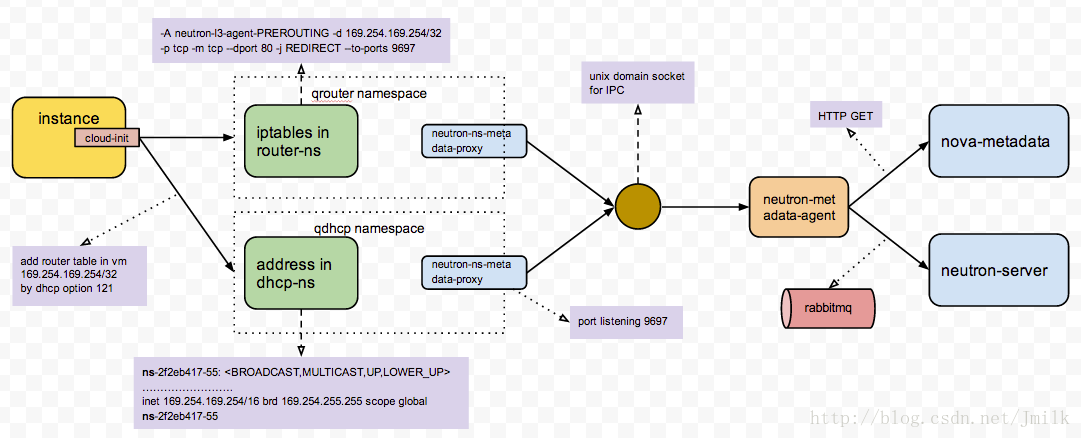
- Instance 发送 metadata 请求被发送至 network namespace
- 再由 namespace 中的 neutron-ns-metadata-proxy service(添加 router-id/network-id 到请求头) 通过 unix domian socket for IPC 技术转发给 neutron-metadata-agent
- 在 neutron-metadata-agent 中, 其会根据请求头中的 router-id/network-id/ip/port , 来获取并添加 instance-id/tenant-id 到请求头中
- 然后由 neutron-metadata-agent 将请求被转发给 nova-api-metadata, 并且利用请求头中的 instance-id/tenant-id 从数据库中获取虚拟机的 metadata
- 最终原路返回 metadata 到虚拟机中
NOTE: 上面已经提到过了如果虚拟机希望访问 169.254.169.254 首先需要在 Node 上设置 DNET:
sudo iptables -t nat -A PREROUTING -d 169.254.169.254/32 -p tcp -m multiport --dport 80 -j DNAT --to-destination <nova_api_server_ip>:8775