前言:继LVS概述,本篇实现NAT模型和DR模型下的负载均衡。
NAT模型:
LVS-NAT基于cisco的LocalDirector。VS/NAT不需要在RealServer上做任何设置,其只要能提供一个tcp/ip的协议栈即可,甚至其无论基于什么OS。基于VS/NAT,所有的入站数据包均由Director进行目标地址转换后转发至内部的RealServer,RealServer响应的数据包再由Director转换源地址后发回客户端。
VS/NAT模式不能与netfilter兼容,因此,不能将VS/NAT模式的Director运行在netfilter的保护范围之中。现在已经有补丁可以解决此问题,但尚未被整合进ip_vs code。
环境:
director:
公网VIP:192.168.2.168
私网DIP:172.16.2.170
realserver网关指向DIP
realserver1 RIP:172.16.2.171 Gateway 172.16.2.170 安装apache
realserver2 RIP:172.16.2.172 Gateway 172.16.2.170 安装apache
各节点之间的时间偏差不应该超出1秒钟;
使用校时协议NTP:Network Time Protocol
director上定义集群:
打开网卡转发:echo 1 > /proc/sys/net/ipv4/ip_forward 轮调算法: ipvsadm -A -t 192.168.2.168:80 -s rr ipvsadm -a -t 192.168.2.168:80 -r 172.16.2.171 -m ipvsadm -a -t 192.168.2.168:80 -r 172.16.2.172 -m
查看集群服务:
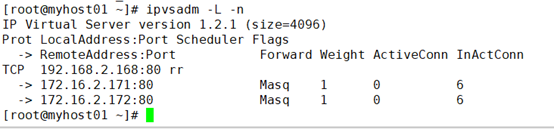
访问测试:


查看连接状态:
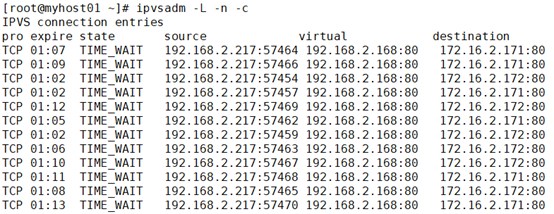
也可以使用其他算法,调整为权重wrr:
ipvsadm -E -t 192.168.2.168:80 -s wrr ipvsadm -e -t 192.168.2.168:80 -r 172.16.2.171 -m -w 3 ipvsadm -e -t 192.168.2.168:80 -r 172.16.2.172 -m -w 1 测试:ab -n 1000 -c 100 http://192.168.2.168/index.html
测试结果,连接3倍左右:

保存规则:
[root@myhost01 ~]# service ipvsadm save
ipvsadm: Saving IPVS table to /etc/sysconfig/ipvsadm: [确定]
保存其他地方:
[root@myhost01 ~]# ipvsadm -S > /home/zdjiang/ipvsadm.web
重新载入:
ipvsadm -R < /home/zdjiang/ipvsadm.web
NAT模型实现起来较为简单。
DR模型:
ARP问题:
__________
| |
| client |
|________|
|
|
(router)
|
|
| __________
| DIP | |
|------| director |
| VIP |__________|
|
|
|
------------------------------------
| | |
| | |
RIP1, VIP RIP2, VIP RIP3, VIP
______________ ______________ ______________
| | | | | |
| realserver1 | | realserver2 | | realserver3 |
|______________| |______________| |______________|
在如上图的VS/DR或VS/TUN应用的一种模型中(所有机器都在同一个物理网络),所有机器(包括Director和RealServer)都使用了一个额外的IP地址,即VIP。当一个客户端向VIP发出一个连接请求时,此请求必须要连接至Director的VIP,而不能是RealServer的。因为,LVS的主要目标就是要Director负责调度这些连接请求至RealServer的。
因此,在Client发出至VIP的连接请求后,只能由Director将其MAC地址响应给客户端(也可能是直接与Director连接的路由设备),而Director则会相应的更新其ipvsadm table以追踪此连接,而后将其转发至后端的RealServer之一。
如果Client在请求建立至VIP的连接时由某RealServer响应了其请求,则Client会在其MAC table中建立起一个VIP至RealServer的对就关系,并以至进行后面的通信。此时,在Client看来只有一个RealServer而无法意识到其它服务器的存在。
为了解决此问题,可以通过在路由器上设置其转发规则来实现。当然,如果没有权限访问路由器并做出相应的设置,则只能通过传统的本地方式来解决此问题了。这些方法包括:
1、禁止RealServer响应对VIP的ARP请求;
2、在RealServer上隐藏VIP,以使得它们无法获知网络上的ARP请求;
3、基于“透明代理(Transparent Proxy)”或者“fwmark (firewall mark)”;
4、禁止ARP请求发往RealServers;
传统认为,解决ARP问题可以基于网络接口,也可以基于主机来实现。Linux采用了基于主机的方式,因为其可以在大多场景中工作良好,但LVS却并不属于这些场景之一,因此,过去实现此功能相当麻烦。现在可以通过设置arp_ignore和arp_announce,这变得相对简单的多了。
Linux 2.2和2.4(2.4.26之前的版本)的内核解决“ARP问题”的方法各不相同,且比较麻烦。幸运的是,2.4.26和2.6的内核中引入了两个新的调整ARP栈的标志(device flags):arp_announce和arp_ignore。基于此,在DR/TUN的环境中,所有IPVS相关的设定均可使用arp_announce=2和arp_ignore=1/2/3来解决“ARP问题”了。
arp_ignore: 定义接收到ARP请求时的响应级别;
0:只要本地配置的有相应地址,就给予响应;
1:仅在请求的目标地址配置请求到达的接口上的时候,才给予响应;
arp_announce:定义将自己地址向外通告时的通告级别;
0:将本地任何接口上的任何地址向外通告;
1:试图仅向目标网络通告与其网络匹配的地址;
2:仅向与本地接口上地址匹配的网络进行通告;
在RealServers上,VIP配置在本地回环接口lo上。如果回应给Client的数据包路由到了eth0接口上,则arp通告或请应该通过eth0实现,因此,需要在sysctl.conf文件中定义如下配置:
#vim /etc/sysctl.conf
net.ipv4.conf.eth0.arp_ignore = 1
net.ipv4.conf.eth0.arp_announce = 2
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
以上选项需要在启用VIP之前进行,否则,则需要在Drector上清空arp表才能正常使用LVS。
到达Director的数据包首先会经过PREROUTING,而后经过路由发现其目标地址为本地某接口的地址,因此,接着就会将数据包发往INPUT(LOCAL_IN HOOK)。此时,正在运行内核中的ipvs(始终监控着LOCAL_IN HOOK)进程会发现此数据包请求的是一个集群服务,因为其目标地址是VIP。于是,此数据包的本来到达本机(Director)目标行程被改变为经由POSTROUTING HOOK发往RealServer。这种改变数据包正常行程的过程是根据IPVS表(由管理员通过ipvsadm定义)来实现的。
如果有多台Realserver,在某些应用场景中,Director还需要基于“连接追踪”实现将由同一个客户机的请求始终发往其第一次被分配至的Realserver,以保证其请求的完整性等。其连接追踪的功能由Hash table实现。Hash table的大小等属性可通过下面的命令查看:
# ipvsadm -lcn
为了保证其时效性,Hash table中“连接追踪”信息被定义了“生存时间”。LVS为记录“连接超时”定义了三个计时器:
1、空闲TCP会话;
2、客户端正常断开连接后的TCP会话;
3、无连接的UDP数据包(记录其两次发送数据包的时间间隔);
上面三个计时器的默认值可以由类似下面的命令修改,其后面的值依次对应于上述的三个计时器:
# ipvsadm --set 28800 30 600
数据包在由Direcotr发往Realserver时,只有目标MAC地址发生了改变(变成了Realserver的MAC地址)。Realserver在接收到数据包后会根据本地路由表将数据包路由至本地回环设备,接着,监听于本地回环设备VIP上的服务则对进来的数据库进行相应的处理,而后将处理结果回应至RIP,但数据包的原地址依然是VIP。
ipvs的持久连接:
无论基于什么样的算法,只要期望源于同一个客户端的请求都由同一台Realserver响应时,就需要用到持久连接。比如,某一用户连续打开了三个telnet连接请求时,根据RR算法,其请求很可能会被分配至不同的Realserver,这通常不符合使用要求。
环境:
director:
VIP eth0:0:192.168.2.170
DIP eth0:192.168.2.168
realserver1 RIP eth0:192.168.2.171 VIP lo:0 192.168.2.170
realserver2 RIP eth0:172.168.2.172 VIP lo:0 192.168.2.170
各节点之间的时间偏差不应该超出1秒钟;
realserver先设置arp,再设置lo:0
改2个接口,一个all的,一个eth0或lo的
echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce ifconfig lo:0 192.168.2.170 broadcast 192.168.2.170 netmask 255.255.255.255 up route add -host 192.168.2.170 dev lo:0 director配置: ifconfig eth0:0 192.168.2.170 broadcast 192.168.2.170 netmask 255.255.255.255 up route add -host 192.168.2.170 dev eth0:0 echo 1 > /proc/sys/net/ipv4/ip_forward /sbin/ipvsadm -C ipvsadm -A -t 192.168.2.170:80 -s wlc ipvsadm -a -t 192.168.2.170:80 -r 192.168.2.171 -g -w 2 ipvsadm -a -t 192.168.2.170:80 -r 192.168.2.172 -g -w 1
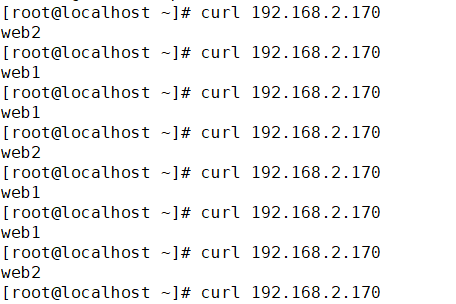
LVS持久连接:
无论使用算法,LVS持久都能实现在一定时间内,将来自同一个客户端请求派发至此前选定的RS。
为什么使用持久连接,为了用户访问的session和cookie,也可以使用session共享替代持久连接。
持久连接模板(内存缓冲区):
每一个客户端 及分配给它的RS的映射关系;
ipvsadm -A|E ... -p timeout:
timeout: 持久连接时长,默认300秒;单位是秒;
在基于SSL,需要用到持久连接;
PPC:将来自于同一个客户端对同一个集群服务的请求,始终定向至此前选定的RS; 持久端口连接
PCC:将来自于同一个客户端对所有端口的请求,始终定向至此前选定的RS; 持久客户端连接
把所有端口统统定义为集群服务,一律向RS转发;
PNMPP:持久防火墙标记连接
iptables -t mangle -A PREROUTING -d $VIP -p tcp --dport $ClusterPORT -i $INCARD -j MARK --set-mark 10
PPC:
ipvsadm -E -t 192.168.2.170:80 -s rr -p 600
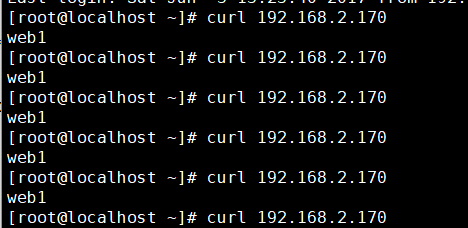

PCC:把所有端口统统定义为集群服务
ipvsadm -A -t 192.168.2.170:0 -s rr -p 600 ipvsadm -a -t 192.168.2.170:0 -r 192.168.2.172 -g ipvsadm -a -t 192.168.2.170:0 -r 192.168.2.171 -g

PNMPP:持久防火墙标记连接
把80和23归并为同一个realserver
80: RS1 注:一般和443归并
22: 同一个RS
ipvsadm -C iptables -t mangle -A PREROUTING -d 192.168.2.170 -i eth0 -p tcp --dport 80 -j MARK --set-mark 10 iptables -t mangle -A PREROUTING -d 192.168.2.170 -i eth0 -p tcp --dport 22 -j MARK --set-mark 10 ipvsadm -A -f 10 -s rr ipvsadm -a -f 10 -r 192.168.2.171 -g ipvsadm -a -f 10 -r 192.168.2.172 -g
上面,没有使用持久连接,启用持久连接:ipvsadm -E -f 10 -s rr -p 600
验证不再给出。