留坑待填,还没看课本(囧
照例说一下前置姿势
本次实验最大的难点估计在于配置实验环境,找了一整天的搜索引擎发现还是出墙香.....我在本次实验中遇到了如下情况:
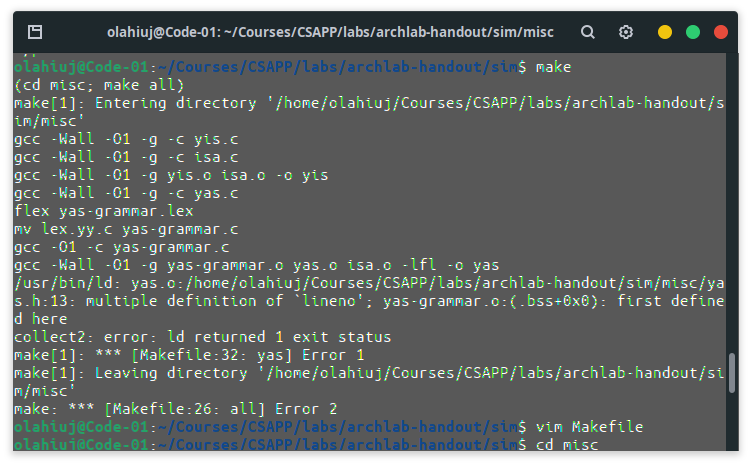
想了很久都想不到要怎么解决,翻了翻yas.h甚至没有#ifndef,总不可能是CMU的人写错了?
最后还是在Stack Overflow上翻到了这样一篇解决方案:戳这里
如果出不了墙可以看这里的解释中的-fno-common条目。在本次实验中只需要知道这是GCC在某次版本更新后改变了默认的编译选项造成的,要正确make只需要在所有的Makefile中的编译开关加入-fcommon就好了,实测要加的文件有两个、共三处
然后flex和bison是肯定要装的,这里CMU的老湿们实际上实现了一个小小的编译器(废话),想到我半死不活的C--,大佬还是太强大了OTZ
如果想要帅气的GUI还需要做一些修正,反正俺没用上....不管了(摔
最后编译成功会有一大段的显示
Part A
sum.ys
这里的.ys应该是Y86_64的.s,.yo就是Y86_64的.o辣
小彩蛋:你甚至能在VSCode中搜索到Y86的语法高亮,sublime屑
感觉没啥好讲的,实在不行GCC一下再翻译成Y86就完事了,当然一眼看出来也很行
我还做了寄存器的存档,看了看别人的代码貌似都没有....不过反正只有一个有用的函数,意会一下就好了
由于语法检测是CMU自己做的,因此文件最后要多一个换行(这有因果关系吗喂
# jjppp 20
# execution begins at address 0x0
.pos 0x0
irmovq stack,%rsp
call main
halt
# a sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
# implementation of sum_list
# list_ptr ls in %rdi
sum_list:
pushq %rdi
pushq %rbx
irmovq 0x0,%rax
jmp test
loop:
mrmovq (%rdi),%rbx
addq %rbx,%rax
mrmovq 0x8(%rdi),%rdi
test:
andq %rdi,%rdi
jne loop
popq %rbx
popq %rdi
ret
main:
irmovq ele1,%rdi
call sum_list
ret
# stack starts here and grows to lower addresses
.pos 0x200
stack:
rsum.ys
递归写起来就很好玩,说实话我是在写递归的时候想起来要储存寄存器的值得
这个也没啥好说的,常规
# jjppp 20
# execution begins at address 0x0
.pos 0x0
irmovq stack,%rsp
call main
halt
# a sample linked list
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
# implementation of rsum_list
rsum_list:
andq %rdi,%rdi
je return
pushq %rbx
pushq %rdi
mrmovq 0x8(%rdi),%rdi
call rsum_list
popq %rdi
mrmovq (%rdi),%rbx
addq %rbx,%rax
popq %rbx
ret
return:
irmovq 0x0,%rax
ret
main:
irmovq ele1,%rdi
call rsum_list
ret
# stack starts here and grows to lower addresses
.pos 0x200
stack:
copy.ys
这个的难点在于运算符的优先级
事实上*t++等价于*(t++),和(*t)++的区别在于操作的对象和取值(废话
然后照着翻译就好了,中途因为不能操作立即数和寄存器所以用到了很多pushq
# jjppp 20
# execution begins at address 0x0
.pos 0x0
irmovq stack,%rsp
call main
halt
.align 8
# source block
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
# destination block
dest:
.quad 0x111
.quad 0x222
.quad 0x333
# implementation of copy_block
# long *src in %rdi, long *dest in %rsi
# long len in %rdx
copy_block:
pushq %rdi
pushq %rsi
pushq %rdx
pushq %rbx
pushq %rcx
pushq %r8
irmovq 0x0,%rax
irmovq 0x8,%rcx
irmovq 0x1,%r8
jmp test
loop:
mrmovq (%rdi),%rbx
addq %rcx,%rdi
rmmovq %rbx,(%rsi)
addq %rcx,%rsi
xorq %rbx,%rax
subq %r8,%rdx
test:
andq %rdx,%rdx
jne loop
popq %r8
popq %rcx
popq %rbx
popq %rdx
popq %rsi
popq %rdi
ret
main:
irmovq src,%rdi
irmovq dest,%rsi
irmovq 0x3,%rdx
call copy_block
ret
# stack starts here and grows to lower addresses
.pos 0x200
stack:
至此archlab的part A就做完辣,先去睡觉了
Part B
这一部分我们要根据作业4.3的要求做一个IADDQ的指令
实际上这个part非常简单,我觉得没啥可讲的....只要看完课本相关内容就好了,实在不行对着示意图看改改hcl就行
在这里应该能体会到恰当的抽象和详细的文档能让让后续工作十分轻松这一点
课本这一章真的好长啊岂可修
Part C
比较有挑战的一个部分,但是说白了就是卡常数嘛...
C实际上是给出了一个流水线的y86模拟器和一个小汇编程序,你可以任意修改模拟器实现/汇编代码来尽可能降低CPE
目前我做到了Avg CPE: 8.66的样子,也就是36.7/60.0的分数,勉勉强强及格吧。俺是真的不知道还能在哪里卡一卡了,等看完书再说!
说一下我做了哪些事情:
- 实现指令
IADDQ,这个很显然毕竟只要翻一翻pipe-full.hcl就可以看到注释的提示 - 用
IADDQ替换%rdi、%rsi和%rdx的增减 - 循环展开了8层
- 去掉了一开始的赋值,毕竟默认寄存器初值都是0
然后就没了....有空再写(一定不鸽
明天就开学了,希望能活下去吧