1. 什么是数据仓库
1.1 什么是数据库
- 数据库是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库
- 数据库是长期存储在计算机内、有组织的、可共享的数据集合。数据库中的数据指的是以一定的数据模型组织、描述和存储在一起、具有尽可能小的冗余度、较高的数据独立性和易扩展性的特点并可在一定范围内为多个用户共享。
1.1 什么是数据库
- 数据库是按照数据结构来组织、存储和管理数据的建立在计算机存储设备上的仓库
- 数据库是长期存储在计算机内、有组织的、可共享的数据集合。数据库中的数据指的是以一定的数据模型组织、描述和存储在一起、具有尽可能小的冗余度、较高的数据独立性和易扩展性的特点并可在一定范围内为多个用户共享。
1.2 什么是数据仓库
定义:面向主题的,集成的,相对稳定的,反应历史变化的数据集合,用于支持管理决策
- **面向主题**:
在较高层次上将企业信息系统数据综合归并及逆行分析利用的抽象的概念。每个主题基本上对应一个相应的分析领域
- **集成的**:
数仓数据源有多个,集成的同时一定要保证数据的一致性、完整性、有效性、精确性。
(1)**一致性**:数据类型必须与手机的数据的预期版本一致,各个数据源若存在相同字段但含义不同时也要及逆行转换处理。
(2)**完整性**:确保数据中应该收集的和实际收集的数据之间没有差距
(3)**精确性**:收集的数据是正确的
(4)**有效性**:
- **稳定的**:
从某个时间段来看是保持不变的,没有更新操作、删除操作,以查询分析为主
- **变化的**:
反应历史变化
定义:面向主题的,集成的,相对稳定的,反应历史变化的数据集合,用于支持管理决策
- **面向主题**:
在较高层次上将企业信息系统数据综合归并及逆行分析利用的抽象的概念。每个主题基本上对应一个相应的分析领域
- **集成的**:
数仓数据源有多个,集成的同时一定要保证数据的一致性、完整性、有效性、精确性。
(1)**一致性**:数据类型必须与手机的数据的预期版本一致,各个数据源若存在相同字段但含义不同时也要及逆行转换处理。
(2)**完整性**:确保数据中应该收集的和实际收集的数据之间没有差距
(3)**精确性**:收集的数据是正确的
(4)**有效性**:
- **稳定的**:
从某个时间段来看是保持不变的,没有更新操作、删除操作,以查询分析为主
- **变化的**:
反应历史变化
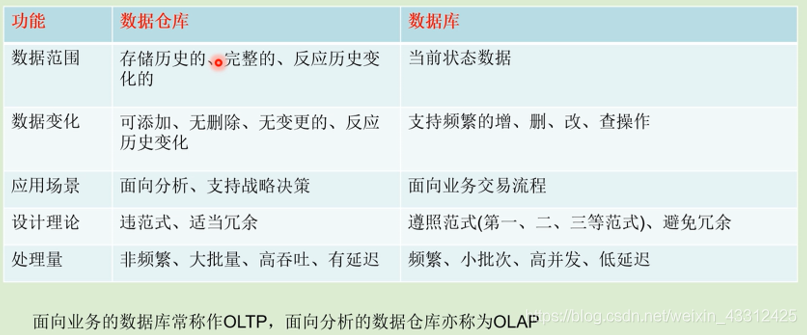
1.3 数据仓库和数据库的比较
**2. 数据仓库的发展历程**
- (1) 萌芽阶段:20世纪70年代MIT提出将业务处理系统和分析系统分开,针对各自不同特点设计不同的架构
- (2)探索阶段: 20世纪80年代,建立TA2(Technical Architecture2)规范,此明确定义了分析系统的四个组成部分:数据获取,数据访问,目录,用户服务。
- (3) 雏形阶段:1988年,IBM第一次提出信息仓库的概念:一个结构化的环境,能支持最终用户管理其全部的业务,并支持信息技术部门保证数据质量;抽象出基本组件:数据抽取、转换、有效性验证、加载、cube开发等,基本明确了数据仓库的基本原理、框架结构,以及分析系统的主要原则。
- (4) 确立阶段:1991年,Bill Inmon出版《Building the Data Warehouse》提出了更具体的数据仓库原则:
面向主题的、集成的、包含历史的、不可更新的、面向决策支持的、面向全企业的、最明细的数据存储、快照式的数据获取。尽管有些理论目前仍有争议,但凭借此书获得数据仓库之父的殊荣。
**3 数仓架构的来源**
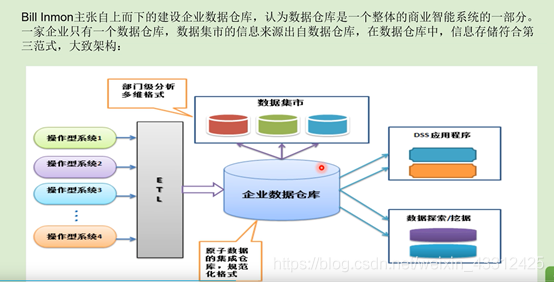
3.1 Bill Inmon主张的架构
 3.2 Ralph Kimball提出的数仓架构
3.2 Ralph Kimball提出的数仓架构
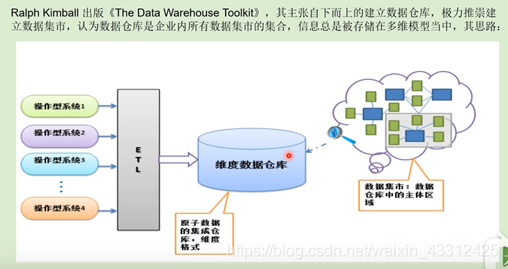 该架构的核心思想就是围绕维度建立很多数据集市,这些数据集市加上维度数据仓库就是数据仓库了。
该架构的核心思想就是围绕维度建立很多数据集市,这些数据集市加上维度数据仓库就是数据仓库了。
3.1 Bill Inmon主张的架构
3.2 Ralph Kimball提出的数仓架构
该架构的核心思想就是围绕维度建立很多数据集市,这些数据集市加上维度数据仓库就是数据仓库了。以上2种思路和观点在实际的操作种都很难成功的完成项目交付,直至最终Bill Inmon提出了新的BI架构CIF(Corporation information factory),,把数据集市包含了进来(相比其原先的理念)。CIF的核心是将数仓架构划分为不同的层次以满足不同场景的需求,比如ODS、DW、DM等,每层根据实际场景采用不同的建设方案,该思路也是目前数据仓库的架构指南,但自上而下还是自下而上的进行数据仓库建设还未统一。
Bill Inmon一开始提出的自上而下的方法,致命的缺点就是数据仓库要符合三泛式,但是一个企业内要按照三范式梳理清楚各个体系关系的话,需要花费大量的时间,并且还可能会有遗漏,所以这种方式建数仓的成功率是比较低的。后来有了kimball的理论,大家像找到一个方向一样,其所强调的就是先建立一个公共的维度,同时围绕相应的主题去做相应的数据集市,这样的话就比较简单了,比如我们可以先做财务系统的数据集市,然后再去做其他体系的数据集市,这样就能得到一个数仓。但这种情形也存在一个比较大的问题,就是数据的一致行和完整性得不到保障,特别是数据集市比较多的情况下,所以这种方式是不适合做企业级数仓的(小型公司可以考虑用这种)。所以后来有了CIF,CIF将数据集市的概念包含到数仓中了,于是就出现了数据的分层。ODS(操作型数据这一层),DW(就是最初定义的数仓,包括上层的数据集市),DW层又细分成了明细数据,上层的汇总数据,到集市的话就是按照主题进行分析的了。就因为这种分层架构的采用,于是就有了不同的建模方法论都可以融入数仓的开发当中去。比如ODS(贴源,所以不需要数据模型),然后再往下,数仓底层明细数据DWD(现在很多企业在用ER实体模型来构建),DWS这层的话就存在维度建模的概念。所以说可以在不同的层次采用不同的建模方法论。