1. 什么是ETL,ETL都是怎么实现的?
ETL中文全称为:抽取.转换.加载 extract transform load
ETL是传数仓开发中的一个重要环节。它指的是,ETL负责将分布的、异构数据源中的数据如关系数据、平面数据文件等抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础。
ETL是数据仓库中的非常重要的一环。它是承前启后的必要一步
在传统数仓领域中,这项工序,大部分公司都是通过使用一些成熟的ETL软件来实现的,这些软件的使用,都不需要手工编程,只需要在软件的界面上,做一些参数配置,拖拽操作,就可以生成数据抽取任务并能够对这些任务进行“调度”。也可以写spark程序来进行ETL。
比较流行的ETL软件如下:

2. 什么是分析主题?各行业的数仓开发中都有哪些分析主题?(到神策上找)
主题:数据分析按它所围绕的“主题”做的逻辑分类
3. 什么是事实和维度?维表有什么用?维表设计模型都有哪些?
(1)事实:现实发生的某件事
维度:衡量事实的一个角度
(2)事实表通过关联维表可以使得自身数据的粒度更加小,更加有利于数据的分析
(3)星型模型,雪花模型,星座模型
4. 数仓开发为什么要分层管理?你们公司都分了哪些层?各层的特性是什么?
(1)空间换时间,让大量运算任务可以复用;把复杂问题简单化;便于解耦“底层业务的变化”对上层的影响
(2)我们公司分了4层,分别为:
- ODS层(Operation Data Store):操作数据层,也叫贴源层,其对应着外部数据源ETL到数仓体系之后的表
- DWD层(Data Warehouse Detail):数仓明细层,一般是对ODS层的表按主题进行加工和划分;本层中表记录的还是明细数据
- DWS层(Data WareHouse Servce):数仓汇总层(数据服务层)
- ADS层(Application Data Servce):应用服务层,应用层,主要是一些结果报表
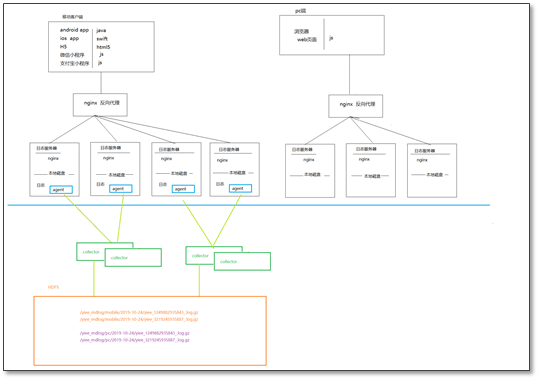
5. 埋点日志是怎么生成?埋点日志有哪几类?又是怎么采集的?
(1)当用户产生一些用户行为时,在业务程序中的埋点代码就能收集这些用户行为,然后埋点代码就向装有nginx的日志服务器发送请求,然后将日志(用户行为)记录到对应的日志服务器中
(2)移动端埋点日志(包括APP,H5,微信小程序等)
PC端埋点日志
(3)使用flume进行采集,具体流程见下图
5.1 衍生问题:
(1)讲下flume的高可用
flume高可用只是针对级联agent中的第二级而言的,第一级的agent是没有高可用的
(2)若第一级的agent坏掉了该怎么办?
找故障=====>重启机器
(3)若是agent坏了并且很久才被发现,这是就会造成数据积压,对实时计算有很大的影响,这该怎么解决?
没办法解决,只能在开始启动agent时,就写一个监控脚本,若该agent挂掉之后就去自动重启它
(4)假如日志数据的产生大于采集数据的速度,造成日志数据积压,这该怎么解决?
级联agent,第二级agent采用负载均衡,若是第一级的agent处(日志服务器上) 的网络带宽有限,造成数据积压,这是只能增加网络带宽或者是增加日志服务器的台数。
6. maven是干嘛的?父子工程有啥特点?什么叫传递依赖?怎么控制排除传递依赖?
(1)管理jar包
(2)依赖继承:父工程中引入的依赖,所有子工程都会自动继承;依赖管理:父工程通过dependencyManagement声明依赖的相关属性(版本),但并不会真正引入依赖,子工程在引入dependencyManagement所声明的依赖时,不需要指定版本,直接继承dependencyManagement中声明的版本!
(3)A依赖B,B依赖C则我们称C为A的传递依赖
(4)在maven中使用<exclusions>标签,期内不使用<exclusion>标签
7. 版本管理(svn)有啥用?它的大体机制是什么?
(1)通过版本管理,我们可以轻易的退回先前代码的版本,若新版本开发出现很大的问题就可以回到以前的版本
(2)其分为客户端和服务端,客户端往服务端每提交一次代码时,服务端就会在自身的版本库记下一个版本,当客户端因为开发需要需要回到某个历史版本,则可以直接回滚到该版本
8. 现在流行的版本管理系统叫什么?它的机制与传统的svn有啥差别?
(1)git
(2)区别:见此博客(https://www.cnblogs.com/mtl-key/p/6902627.html)
9. git和github、gitlab、gitee是什么关系?
git是一个版本管理系统,而github、gitlab、gitee则是不同开发者开发的git服务器,作用都是一样的