更多内容见文档
1. 区域字典的生成
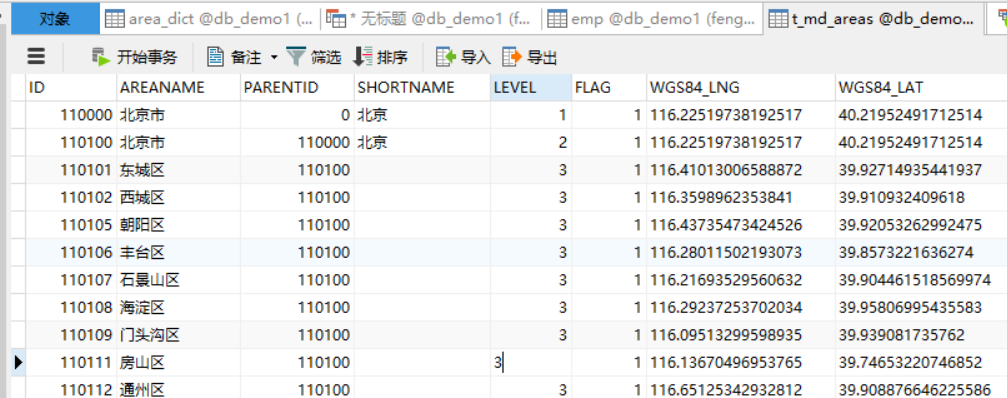
mysql中有如下表格数据
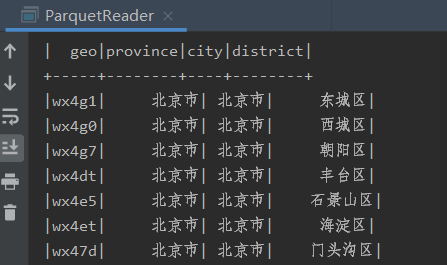
现要将这类数据转换成(GEOHASH码, 省,市,区)如下所示
(1)第一步:在mysql中使用sql语句对表格数据进行整理(此处使用到了自关联,具体见文档大数据学习day03)
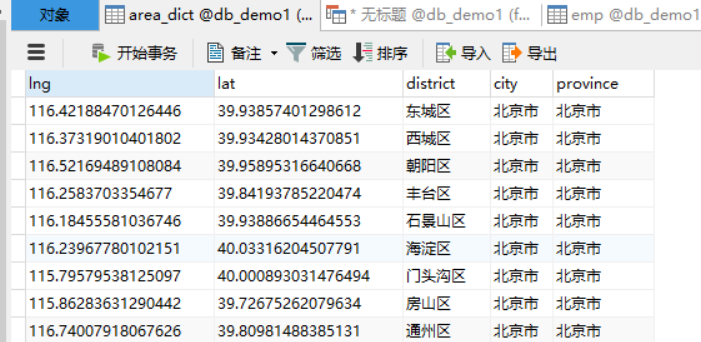
create table area_dict as SELECT a.BD09_LNG as lng, a.BD09_LAT as lat, a.AREANAME as district, b.AREANAME as city, c.AREANAME as province from t_md_areas a join t_md_areas b on a.`LEVEL`=3 and a.PARENTID=b.ID join t_md_areas c on b.PARENTID = c.ID
得到结果如下
(2)第二步:使用spark sql读取这些数据,并将数据使用GeoHash编码,具体代码如下(这里涉及到parquet数据源,spark喜欢的数据格式)
AreaDictGenerator


package com._51doit import java.util.Properties import ch.hsr.geohash.GeoHash import org.apache.spark.sql.{DataFrame, SparkSession} object AreaDictGenerator { def main(args: Array[String]): Unit = { // 创建SparkSession实例 val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 创建连接数据库需要的参数 val probs: Properties = new Properties() probs.setProperty("driver", "com.mysql.jdbc.Driver") probs.setProperty("user","root") probs.setProperty("password", "feng") // 以读取mysql数据库的形式创建DataFrame val df: DataFrame = spark.read.jdbc("jdbc:mysql://localhost:3306/db_demo1?characterEncoding=UTF-8", "area_dict", probs) // 运算逻辑 import spark.implicits._ val res: DataFrame = df.rdd.map(row => { val lng = row.getAs[Double]("lng") val lat = row.getAs[Double]("lat") val district = row.getAs[String]("district") val city = row.getAs[String]("city") val province = row.getAs[String]("province") val geoCode: String = GeoHash.withCharacterPrecision(lat, lng, 5).toBase32 (geoCode, province, city, district) }).toDF("geo", "province", "city", "district") res.write.parquet("E:/javafile/spark/out11") } }
这一步即可得到上述格式的数据。
(3)验证
ParquetReader
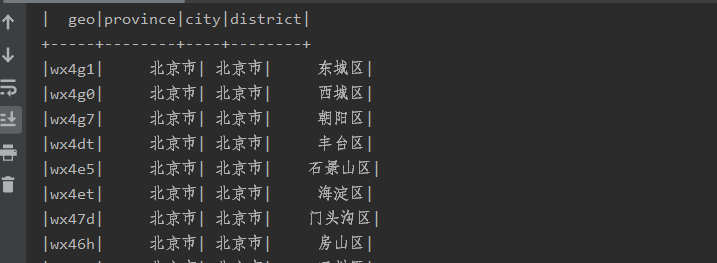
package com._51doit import org.apache.spark.sql.{DataFrame, SparkSession} object ParquetReader { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() val df: DataFrame = spark.read.parquet("E:/javafile/spark/out11") df.show() } }
结果