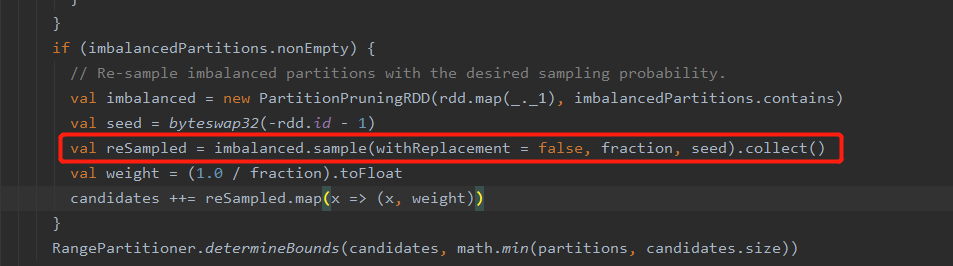
1. sortBy是Transformation算子,为什么会触发Action
sortBy需要对数据进行全局排序,其需要用到RangePartitioner,而在创建RangePartitioner时需要大概知道有多少数据,以及数据的范围(采样),其内部获取这个范围(rangeBounds)是通过调用sample方法得到,在调用完sample后会调用collect方法,所以会触发Action
2. Spark SQL概述
2.1 Spark SQL定义:
Spark SQL是Spark用来处理结构化数据的一个模块
2.1.1 什么是DataFrames:
与RDD类似,DataFrame也是一个分布式数据容器【抽象的】。然而DataFrame更像DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也是支持嵌套数据类型(struct、array和map)。从API易用性角度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好的继承了传统单机数据分析的开发体验
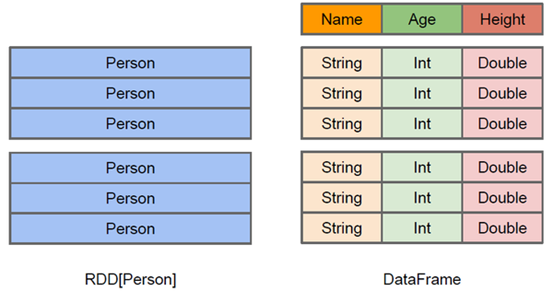
DataFrame = RDD + Schema【更加详细的结构化描述信息】,以后在执行就可以生成执行计划,进行优化。它提供了一个编程抽象叫做DataFrame/Dataset,它可以理解为一个基于RDD数据模型的更高级数据模型,带有结构化元信息(schema),以及sql解析功能
Spark SQL可以将针对DataFrame/Dataset的各类SQL运算,翻译成RDD的各类算子执行计划,从而大大简化数据运算编程(请联想Hive)
3 DateFrame的创建
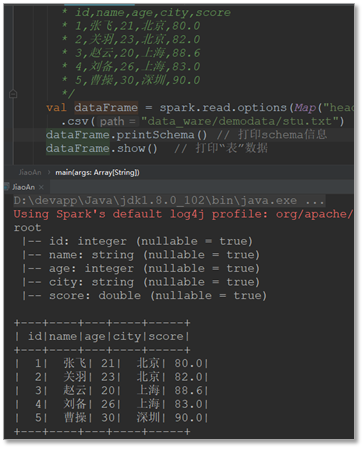
3.1 sparksql1.x创建DataFrame(SQLContext)
这种形式的写法能更好的理解SQLContext就是对SparkContext的包装增强


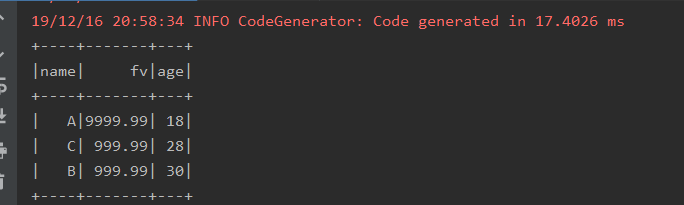
package com._51doit.spark07 import com._51doit.spark05.Boy import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.sql.{SQLContext,DataFrame} object DataFrameDemo1 { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSQL1x").setMaster("local[*]") //sc是sparkcore,是用来创建RDD的 val sc = new SparkContext(conf) // 要创建SQLContext,其相当于是对SparkContext包装增强 //SQLContext就可以创建DataFrame val sqlContext: SQLContext = new SQLContext(sc) // 使用SQLContext创建DataFrame(RDD+Schema) val rdd = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99")) //RDD跟schema val rdd1: RDD[Boy] = rdd.map(line => { val fields = line.split(",") val n = fields(0) val a = fields(1) val f = fields(2) Boy(n, a.toInt, f.toDouble) }) //导入隐式转换 import sqlContext.implicits._ //将RDD转成DataFrame val df = rdd1.toDF // 使用SQL风格的API df.registerTempTable("boy") // 传入SQL // sql方法是Transformation val res: DataFrame = sqlContext.sql("SELECT name, fv, age FROM boy ORDER BY fv DESC, age ASC") //触发Action,将sql运行的结果收集到Driver端返回 res.show() //释放资源 sc.stop() } }
运行结果
3.2 sparksql2.x创建DataFrame(SparkSession)
SparkSession是对SparkContext的封装,里面有SparkContext的引用,想获得sc直接使用SparkSession调用sparkContext
package com._51doit.spark07 import com._51doit.spark05.Boy import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} object SparkSQL2x { def main(args: Array[String]): Unit = { // 编程SparkSQL程序,创建DataFrame val session: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() // SparkSession 是对SparkContext的封装,里面持有SparkContext的引用 val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99")) val boyRDD: RDD[Boy] = rdd.map(line => { val fields: Array[String] = line.split(",") val n = fields(0) val a = fields(1) val f = fields(2) Boy(n, a.toInt, f.toDouble) }) // 导入隐式转换 import session.implicits._ // 使用SparkSession创建DataFrame val df: DataFrame = boyRDD.toDF() df.createTempView("v_boy") // 写SQL val res: DataFrame = session.sql("SELECT name, fv, age FROM v_boy ORDER BY fv DESC, age ASC") // 触发action res.show() session.stop() } }
运行结果同上
3.3 使用Scala的case class方式创建DataFrame
Boy
case class Boy(name:String, age:Int, fv: Double)
DataFrameDemo1(同2.2.2)
此处创建DF的方法
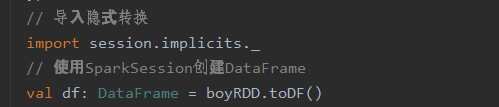
可变成如下(完整的写法):

3.4 使用Scala的 class方式创建DataFrame
Man(此处要用到set方法设置属性,所以需要用@BeanProperty)
class Man { @BeanProperty var name:String = _ @BeanProperty var age:Integer = _ @BeanProperty var fv:Double = _ def this(name: String, age: Int, fv: Double) { this() this.name = name this.age = age this.fv = fv } }
DataFrameDemo2
package com._51doit.spark07 import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} object DataFrameDemo2 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame val session: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() // 获取SparkContext val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9")) val manRDD: RDD[Man] = rdd.map(line => { val fields: Array[String] = line.split(",") val name: String = fields(0) val age: Int = fields(1).toInt val fv: Double = fields(2).toDouble new Man(name, age, fv) }) // 创建DataFrame // import session.implicits._ // manRDD.toDF() val df: DataFrame = session.createDataFrame(manRDD, classOf[Man]) //建df创建一个视图 df.createTempView("v_boy") //写SQL val result: DataFrame = session.sql("SELECT name, fv, age FROM v_boy ORDER BY fv DESC, age ASC") //触发Action result.show() session.stop() } }
注意,此处用不了rdd.toDF的形式来创建DataFrame

3.5 使用java的 class方式创建DataFrame
形式和scala的class几乎一样
package com._51doit.spark07 import org.apache.spark.SparkContext import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} object DataFrameDemo3 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame val session: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() // 获取SparkContext val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9")) val jPersonRDD: RDD[JPerson] = rdd.map(line => { val fields: Array[String] = line.split(",") val name: String = fields(0) val age: Int = fields(1).toInt val fv: Double = fields(2).toDouble new JPerson(name, age, fv) }) // 创建DateFrame val df: DataFrame = session.createDataFrame(jPersonRDD, classOf[JPerson]) // 创建一个视图 df.createTempView("v_person") //写SQL val result: DataFrame = session.sql("SELECT name, fv, age FROM v_person ORDER BY fv DESC, age ASC") //触发Action result.show() session.stop() } }
3.6 使用scala元组的方式创建DataFrame
创建形式如下:
object DataFrame4 { def main(args: Array[String]): Unit = { val session = SparkSession.builder() .appName("DataFrame4") .master("local[*]") .getOrCreate() // 获取SparkSession val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9")) val tpRDD: RDD[(String, Int, Double)] = rdd.map(line => { val fields: Array[String] = line.split(",") val n = fields(0) val a = fields(1) val f = fields(2) (n, a.toInt, f.toDouble) }) // 创建DataFrame import session.implicits._ val df: DataFrame = tpRDD.toDF // 使用df创建一个视图 df.createTempView("v_person") df.printSchema() } }
打印结果

这样写想要从表中获取数据是就只能使用_n,非常不方便
简单改变,在DF()方法中加入参数,如下
object DataFrame4 { def main(args: Array[String]): Unit = { val session = SparkSession.builder() .appName("DataFrame4") .master("local[*]") .getOrCreate() // 获取SparkSession val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("小明,18,999.99","老王,35,99.9","小李,25,99.9")) val tpRDD: RDD[(String, Int, Double)] = rdd.map(line => { val fields: Array[String] = line.split(",") val n = fields(0) val a = fields(1) val f = fields(2) (n, a.toInt, f.toDouble) }) // 创建DataFrame import session.implicits._ val df: DataFrame = tpRDD.toDF("name", "age", "face_value") df.createTempView("v_person") val result: DataFrame = session.sql("SELECT name, age, face_value FROM v_person ORDER BY face_value DESC, age ASC") //触发Action result.show() session.stop() }
3.7 通过row方法的形式创建DataFrame
代码如下
package cn._51doit.spark.day07 import org.apache.spark.rdd.RDD import org.apache.spark.sql.types.{DoubleType, IntegerType, StringType, StructField, StructType} import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * * 使用SparkSQL的ROW的方式 */ object DataFrameDemo5 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame val session: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() //SparkSession是对SparkContext的封装,里面持有SparkContext的引用 val sc = session.sparkContext val rdd = sc.parallelize(List("laozhao,18,9999.99", "laoduan,30,999.99", "nianhang,28,999.99")) //RowRDD val rowRDD: RDD[Row] = rdd.map(line => { val fields = line.split(",") val n = fields(0) val a = fields(1) val f = fields(2) Row(n, a.toInt, f.toDouble) }) //schema // val schema = StructType( // List( // StructField("name", StringType), // StructField("age", IntegerType), // StructField("fv", DoubleType) // ) // ) val schema = new StructType() .add(StructField("name", StringType)) .add(StructField("age", IntegerType)) .add(StructField("fv", DoubleType)) val df: DataFrame = session.createDataFrame(rowRDD, schema) df.printSchema() session.stop() } }
3.8 通过解析json文件的形式创建DataFrame
package cn._51doit.spark.day07 import org.apache.spark.rdd.RDD import org.apache.spark.sql.types._ import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * * 读取JSON文件创建DataFrame */ object DataFrameDemo6 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame val spark: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() //从JSON文件中读取数据,并创建DataFrame //RDD + Schema【json文件中自带Schema】 // val df: DataFrame = spark.read.json("/Users/star/Desktop/user.json") //df.printSchema() df.createTempView("v_user") val result: DataFrame = spark.sql("SELECT name, age, fv FROM v_user WHERE _corrupt_record IS NULL") result.show() spark.stop() } }
3.9 读取csv文件的形式创建DataFrame
package cn._51doit.spark.day07 import org.apache.spark.sql.{DataFrame, SparkSession} /** * * 读取csv文件创建DataFrame */ object DataFrameDemo7 { def main(args: Array[String]): Unit = { //编程SparkSQL程序,创建DataFrame val spark: SparkSession = SparkSession.builder() .appName("SparkSQL2x") .master("local[*]") .getOrCreate() //从JSON文件中读取数据,并创建DataFrame //RDD + Schema【csv文件中自带Schema】 // val df: DataFrame = spark.read .option("header", true) //将第一行当成表头 .option("inferSchema",true) //推断数据的类型,默认都是string .csv("/Users/star/Desktop/user.csv") //默认指定名称为 _c0, _c1, _c2 //val df1: DataFrame = df.toDF("name", "age", "fv") //给指定字段重命名 //val df1 = df.withColumnRenamed("_c0", "name") df.printSchema() //df.createTempView("v_user") //val result: DataFrame = spark.sql("SELECT name, age, fv FROM v_user WHERE _corrupt_record IS NULL") df.show() spark.stop() } }
4. DSL风格API语法
DSL风格API,就是用编程api的方式,来实现sql语法
使用DSL风格API【就是直接调用DataFrame的算子,Transformation和Action】

DataFrameDSLAPI
object DataFrameDSLAPI { def main(args: Array[String]): Unit = { // 编程SparkSQL程序,创建DataFrame val session: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // 获取SparkContext val sc: SparkContext = session.sparkContext val rdd: RDD[String] = sc.parallelize(List("A,18,9999.99", "B,30,999.99", "C,28,999.99")) val boyRDD: RDD[Boy] = rdd.map(line => { val fields: Array[String] = line.split(",") val name: String = fields(0) val age: String = fields(1) val fv: String = fields(2) Boy(name, age.toInt, fv.toDouble) }) // 导入隐式转换,创建DF import session.implicits._ val df: DataFrame = boyRDD.toDF() // 使用DSL风格API val result: Dataset[Row] = df.select("name","fv").where($"fv" >= 1000) //触发Action result.show() session.stop() } }
5.案例
wordcount案例
5.1 SQL风格
(1)结合flatmap算子(DSL风格的API,即算子)进行操作
package com._51doit.spark07 import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SQLWordCount { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // Dataset是更加智能的RDD,只有一列,命名默认为value val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt") // 导入隐式转换 import spark.implicits._ val words: Dataset[String] = lines.flatMap(_.split(" ")) // 将words注册成视图 words.createTempView("v_words") // 写SQL val res: DataFrame = spark.sql("SELECT value word, count(1) counts FROM v_words GROUP BY word ORDER BY counts DESC") res.write.csv("E:/javafile/out1") spark.stop() } }
(2)直接通过SQL的形式
object SQLWordCountAdv { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // Dataset是更加智能的RDD,只有一列,命名默认为value val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt") // 将words注册成视图 lines.createTempView("v_lines") // 写SQL spark.sql( s""" |SELECT word, COUNT(1) counts FROM | (SELECT EXPLODE(words) word FROM | (SELECT SPLIT(value, ' ') words FROM v_lines) | ) | GROUP BY word ORDER BY counts DESC |""".stripMargin ).show() spark.stop() } }
5.2 DSL风格(更方便)
(1)
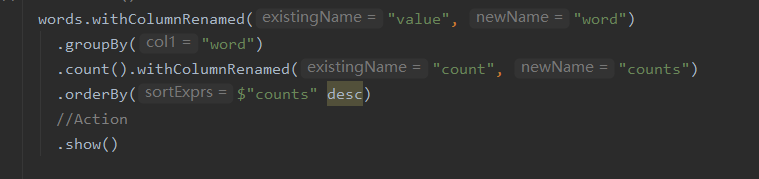
object DataSetWordCount1 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // Dataset是更加智能的RDD,只有一列,命名默认为value val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt") // 导入隐式转换 import spark.implicits._ // 调用DSL风格的API val words: Dataset[String] = lines.flatMap(_.split(" ")) words.groupBy("value") .count() .orderBy($"count" desc) .show() spark.stop() } }
这种写法只能使用默认的列名,若想自己命名列的话可以使用withColumnRenamed,如下
(2)将结果写入数据库(Mysql)
package com._51doit.spark07 import java.util.Properties import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession} object DataSetWordCount2 { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getSimpleName) .master("local[*]") .getOrCreate() // Dataset是更加智能的RDD,只有一列,命名默认为value val lines: Dataset[String] = spark.read.textFile("F:/大数据第三阶段/spark/spark-day07/资料/words.txt") // 导入隐式转换 import spark.implicits._ // 调用DSL风格的API val words: DataFrame = lines.flatMap(_.split(" ")).withColumnRenamed("value", "word") //使用DSL风格的API //导入agg里面使用的函数 import org.apache.spark.sql.functions._ val result: DataFrame = words.groupBy("word").agg(count("*") as "counts").sort($"counts" desc) //将数据保存到MySQL val props = new Properties() props.setProperty("driver", "com.mysql.jdbc.Driver") props.setProperty("user", "root") props.setProperty("password", "feng") //触发Action result.write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/db_user?characterEncoding=UTF-8&useSSL=true", "words", props) println("haha") spark.stop() } }
运行结果
