0.前言
0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例)
提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而产生任务(有多少个MapTask以及多少个ReduceTask),然后根据各个nodemanage节点资源情况进行任务划分。最后得到结果存入hdfs中或者是数据库中
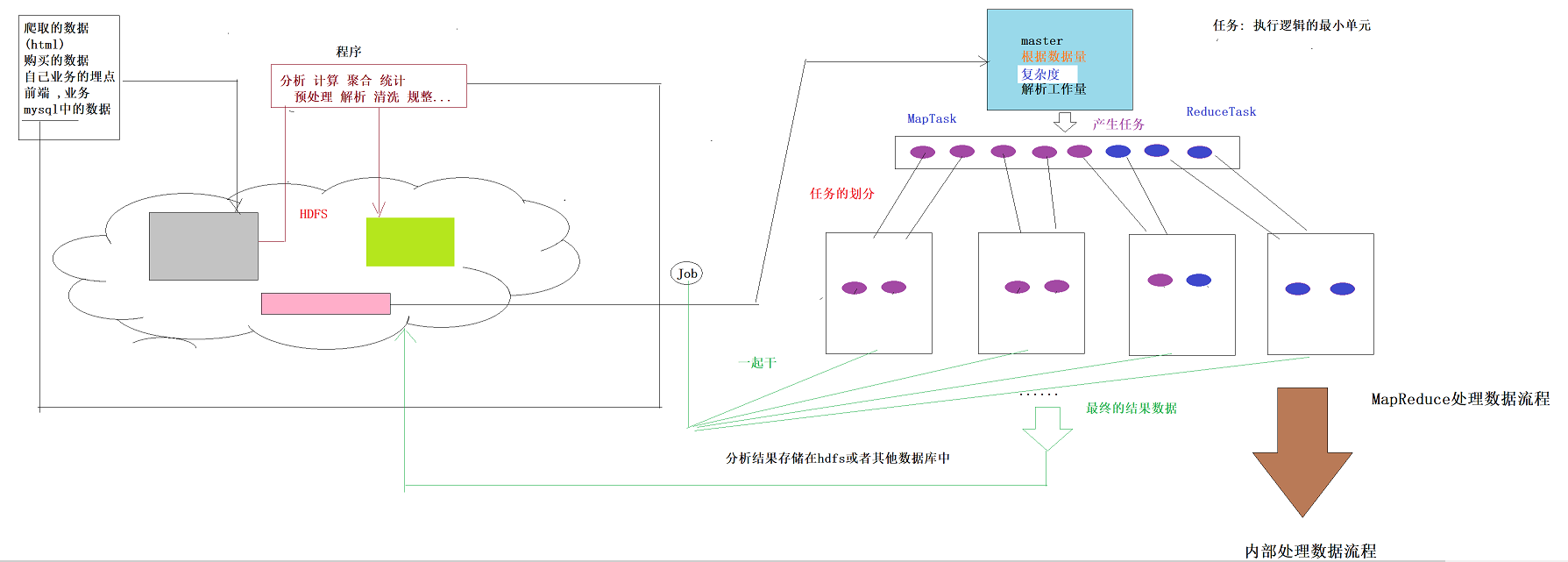
注意:由图可知,map任务和reduce任务在不同的节点上,那么reduce是如何获取经过map处理的数据呢?======>shuffle
0.2 MR与Spark的简单比较
mapreduce:读--处理---写磁盘---读---处理---写磁盘。。。。。
spark:读---处理---处理---处理---结果(需要的时候)写磁盘 基于内存计算
Spark在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷(频繁的与磁盘进行IO交互)
0.3 spark可以怎么运行
- 本地单机测试模拟分布式运行
- yarn等分布式资源调度平台上运行
- 自带的分布式资源调度平台(standalone)
启动standalone集群需要做两件事:(1)在master机器上./sbin/start-master.sh (2)启动一个或多个worker节点并把它注册到master节点上:./sbin/start-slave.sh
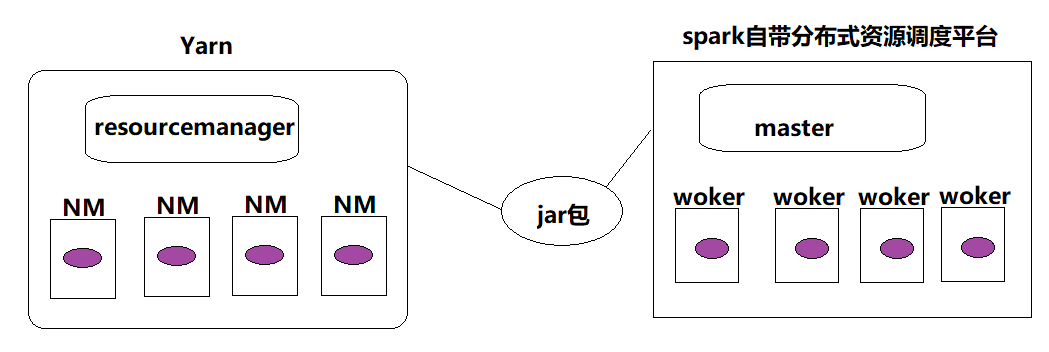
其中,Standalone用的比较少,其一般适合几十台节点的集群,若是上千台机器的话就用yarn。
0.4 spark程序提交到spark集群的方式
- 交互式连接窗口(spark shell)
spark-shell和spark-shell --master spark://feng05:7070区别:前者是本地单节点运行,后者是在集群上多节点运行
比如3.3中就是多借点的wc运算,若是在spark-shell,则为本地测试(单节点,其也有个监控web,端口为4040)
- spark-submit(写好程序,打包)
spark-submit --master spark://feng05:7077 --class com.doit.spark01.SparkSubmitWC /root/wc.jar
- 本地测试使用,idea软件写程序的main方法
1. spark(standalone模式)的安装
(1)下载spark安装包(spark官网)
(2)上传spark安装包到Linux服务器上
(3)解压spark安装包
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /usr/apps/
(4)将conf目录下的spark-env.sh.template重命名为spark-env.sh,并修改内容如下(配置master节点)
export JAVA_HOME=/usr/apps/jdk1.8.0_192 export SPARK_MASTER_HOST=feng05
export SPARK_MASTER_PORT=7077
在编辑内容的过程中,想查看某个路径命令(此处在编辑时想知道JAVA_HOM对应的路径):
: r! echo $JAVA_HOME // 在命令行模式按出“:”
(5)将conf目录下的slaves.template重命名为slaves并修改,指定Worker的所在节点
feng02
feng03
(6)分发(将配置好的spark拷贝到其他节点)
for i in {2..3}; do scp -r spark-2.3.3 node-$i.51doit.cn:$PWD; done // 第一种方式 scp -r spark-2.3.3-bin-hadoop2.7 feng02:$PWD // 以前一直用的方式
(7)启动(注意,此处就别配置环境变量了,否则当使用start-all.sh时,就会与hadoop中的该命令起冲突)
- 在spark的安装目录执行启动脚本
sbin/start-all.sh
- 执行jps命令查看Java进程
在feng05上用可看见Master进程,在其他节点上用可看见Worker
- 访问Master的web管理界面,端口8080
2. Spark各个角色的功能
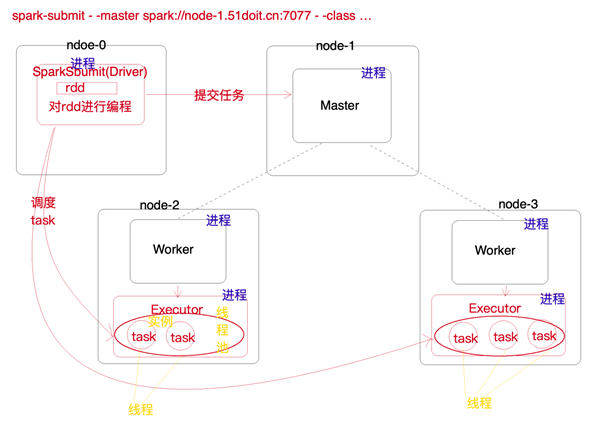
- Master:是一个Java进程,接收Worder的注册信息和心跳、移除异常超时的Worker、接收客户端提交的任务、负责资源调度、命令Worker启动Executor。
- Worker:是一个java进程,负责管理当前节点的资源关联,向Master注册并定期发送心跳,负责启动Executor、并监控Executor的状态
- SparkSubmit:是一个java进程,负责向Master提交任务
- Driver:是很多类的统称,可以认为SparkContext就是Driver,client模式Driver运行在SparkSubmit进程中,cluster模式单独运行在一个进程中,负责将用户编写的代码转成Tasks,然后调度到Executor中执行,并监控Task的状态和执行进度
- Exeutor: 是一个java进程,负责执行Driver端生成的Task,将Task放入线程中运行
3.SparkShell的使用
3.1 什么是Spark Shell
spark shell是spark中的交互式命令行客户端,可以在spark shell中使用scala编写spark程序,启动后默认已经创建了SparkContext,别名为sc
3.2 启动Spark Shell
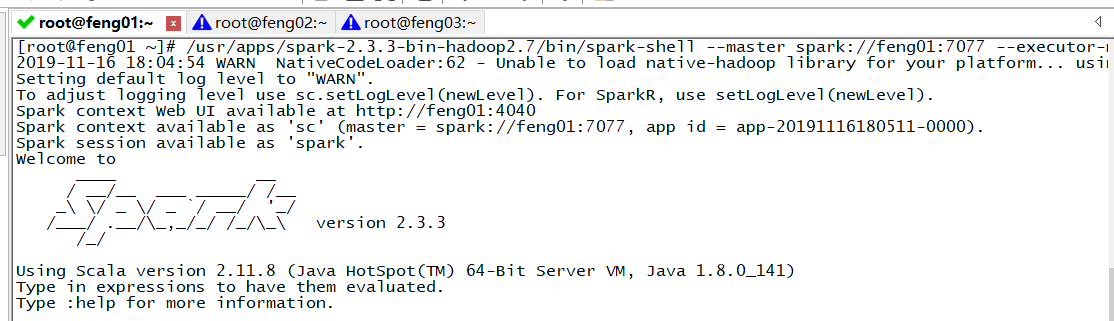
/usr/apps/spark-2.3.3-bin-hadoop2.7/bin/spark-shell --master spark://feng01:7077 --executor-memory 800m --total-executor-cores 3
此处自己犯的小错误:将"--" 少写了一个"-"
参数说明:
--master:指定master的地址和端口,协议为spark://,端口是RPC的通信端口
--executor-memory: 指定每一个executor的使用的内存大小
--total-executor-cores:指定整个application总共使用了多少cores
注意:
(1)在spark中,提交一个job之后会造每一个worker上生成一个executor(若不配置核数,默认是占用该节点所有的core以及1G的内存)
(2)standalone模式只能指明整个集群executor的core数(on yarn模式可以指定单个executor的core数),若指定的core数超过机器的core数,集群中的executor会以最大的core来运行,若是内存指定的超过节点本身的内存大小,则任务会被阻塞,知道节点有足够大的内存才会被执行。
3.3 在shell中编写第一个spark程序(WordCount,单词统计)
sc.textFile("hdfs://feng05:9000/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("hdfs://feng05:9000/out1")
4. Spark编程入门
4.1 在IDEA中使用scala编写wordcount案例(本地运行模式)
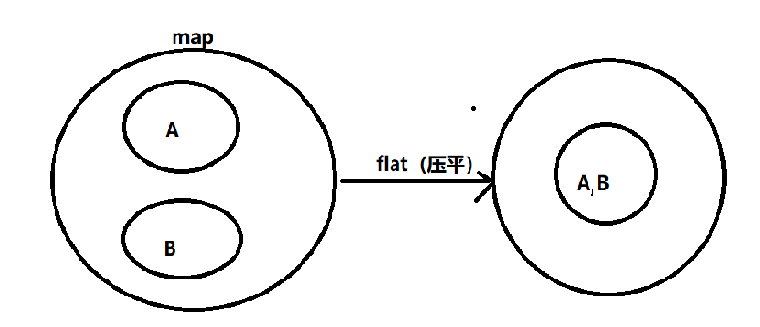
map和flatmap(切分压平)的区别:

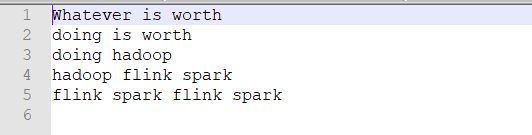
words.txt内容如下:
统计代码如下
object WordCount { def main(args: Array[String]): Unit = { // val conf: SparkConf = new SparkConf().setAppName("WordCount") //Spark程序local模型运行,local[*]是本地运行,并开启多个线程 val conf: SparkConf = new SparkConf() .setAppName("WordCount") .setMaster("local[*]") //设置为local模式执行 // 1 创建SparkContext,使用SparkContext来创建RDD val sc: SparkContext = new SparkContext(conf) // spark写Spark程序,就是对神奇的大集合【RDD】编程,调用它高度封装的API // 2 使用SparkContext创建RDD val lines: RDD[String] = sc.textFile("E:/javafile/words.txt") // 3 切分压平 val words: RDD[String] = lines.flatMap(line => line.split(" ")) // 4 将单词和1组合放在元组中 val wordAndOne: RDD[(String, Int)] = words.map((_, 1)) // 5 分组聚合,reduceByKey可以先局部聚合再全局聚合 val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _) // 6 排序 val sorted: RDD[(String, Int)] = reduced.sortBy(_._2, false) // 调用Action将计算结果保存 sorted.saveAsTextFile("E:/javafile/wc/out1") // 释放资源 sc.stop() } }
4.2 在IDEA中使用JAVA编写wordcount案例
(1)不使用lambda
将该程序打包上传集群中测试
代码
public class WordCount1 { public static void main(String[] args) { // 创建JavaSparkContext SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); // 使用javaSparkContent创建RDD JavaRDD<String> lines = jsc.textFile(args[0]); //调用Tranformation(s) // 切分压平(这块不太懂) JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterator<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")).iterator(); } }); // 将单词与1组合放到元组中去 JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String word) throws Exception { return Tuple2.apply(word, 1); } }); // 分组聚合 JavaPairRDD<String, Integer> reduced = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } }); // 排序,按key的值倒叙排列 // 由于java中的JavaPairRDD无按值排序的方法,所以先调换kv的顺序 JavaPairRDD<Integer, String> swapped = reduced.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() { @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception { return tp.swap(); } }); // 排序 JavaPairRDD<Integer, String> sorted = swapped.sortByKey(false); // 将kv的顺序调换回来 JavaPairRDD<String, Integer> res = sorted.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> tp) throws Exception { return tp.swap(); } }); // 触发Action,将数据保存到HDFS res.saveAsTextFile(args[1]); } }
运行命令

(2)使用lambda
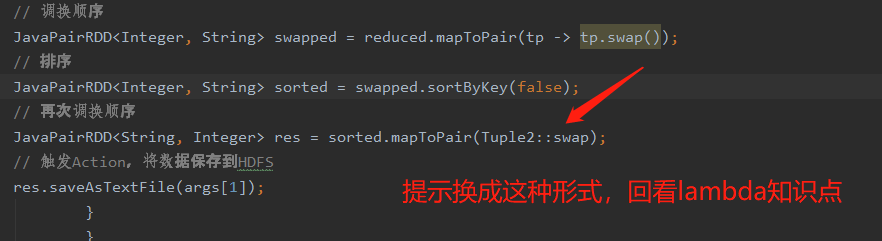
代码
public class WordCount2 { public static void main(String[] args) { // 创建SparkContext SparkConf conf = new SparkConf().setAppName("LambdaWordCount"); JavaSparkContext jsc = new JavaSparkContext(conf); // 创建RDD JavaRDD<String> lines = jsc.textFile(args[0]); // 切分压平 JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); // 将得到的单词与1组合 JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(word -> Tuple2.apply(word, 1)); // 分组聚合 JavaPairRDD<String, Integer> reduced = wordAndOne.reduceByKey((a, b) -> a + b); // 按key的值进行排序 // 调换顺序 JavaPairRDD<Integer, String> swapped = reduced.mapToPair(tp -> tp.swap()); // 排序 JavaPairRDD<Integer, String> sorted = swapped.sortByKey(false); // 再次调换顺序 JavaPairRDD<String, Integer> res = sorted.mapToPair(Tuple2::swap); // 触发Action,将数据保存到HDFS res.saveAsTextFile(args[1]); } }
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /bigdata/