0. 补充(查询源代码的操作)
(1)ctrl+shift+t 查找某个类
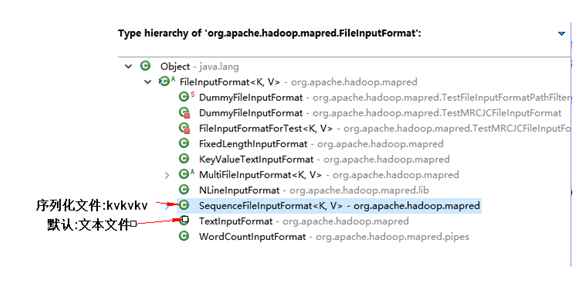
(2)crtl+t查看类的继承结构
(3)ctrl+o 查看类中的方法
1. MR程序数据处理全流程
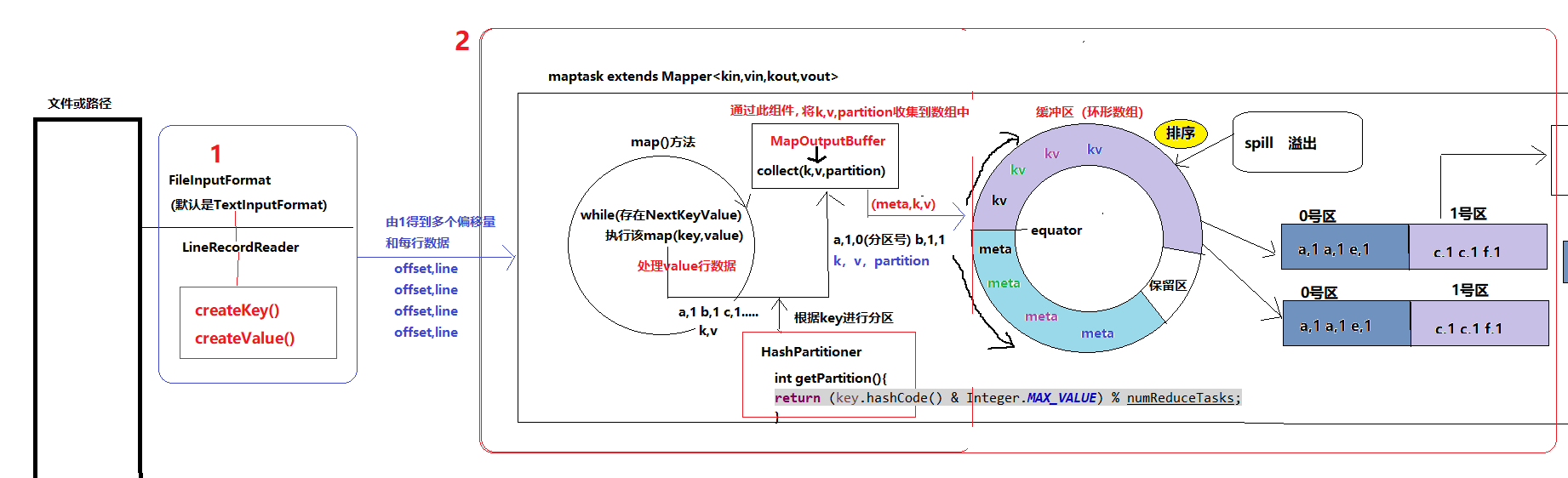
第一步:FileInputFormat找到指定路径或文件夹(若是文件夹且有多个文件,会开启多个map任务,默认是一个文件用一个map去处理),通过调用LineRecordReader类中的createKey(),createValue()方法,得到多个偏移量和每行数据(offset,line)
第二步:这个偏移量以及line会作为MapTask的参数,调用map方法,对所有line数据进行处理,从而得到k,v(如a,1 a,1 b,1等),之后是调用HashPartitioner组件对map得到的key进行分区处理(key%n),得到分区号(partition),然后MapOutputBuffer组件调用collect方法将k,v,partition收集到数组中去,即将meta以及kv写入环形缓冲区,默认大小100mb,并且在配置文件里为这个缓冲区设定了一个阀值,默认是0.80,同时map还会为输出操作启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把缓冲区中的内容写到磁盘上,这个过程叫spill(溢出),可以多次溢出(产生多个溢出文件),若写入内存的数据小于默认的100mb,则会溢出一次(产生一个溢出文件)。另外的20%内存可以继续写入数据,写入磁盘和写入内存操作是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作,如此循环使用

每一对kv都会有一个meta来描述,一个meta占固定4个字节
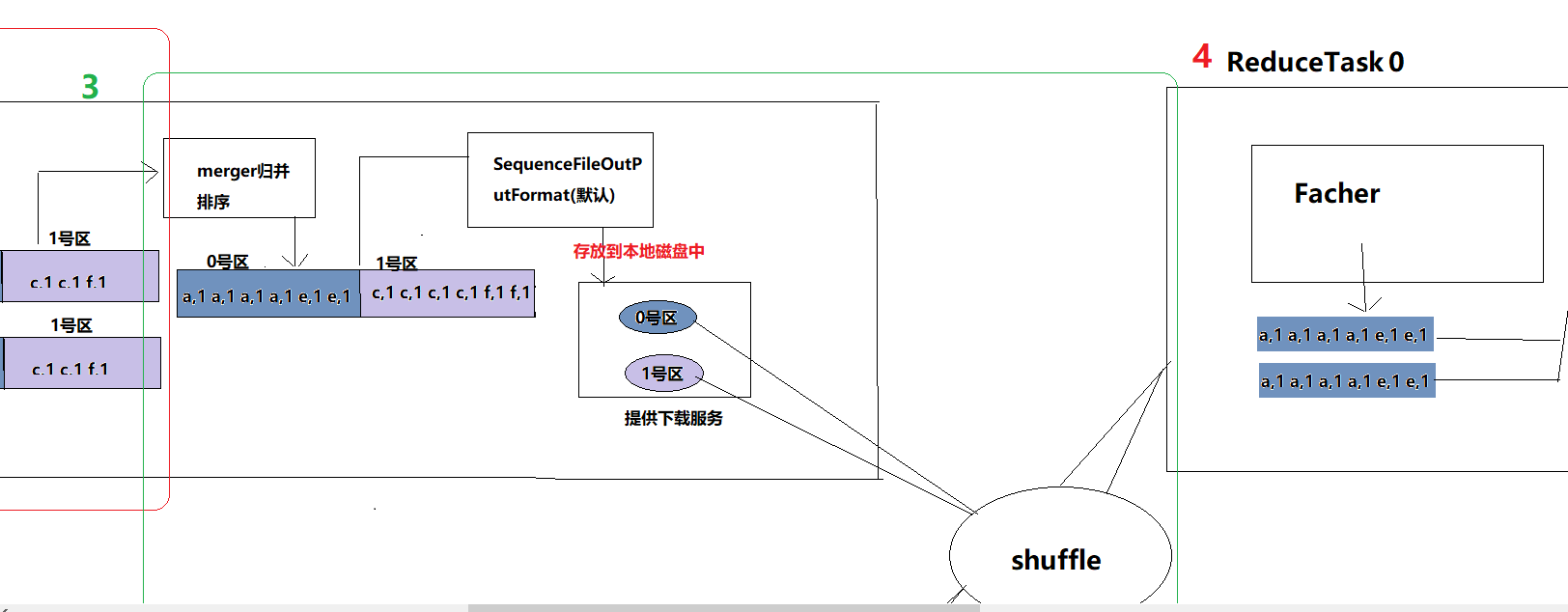
第三步:溢出的数据写入磁盘中(通过SequenceFileOutPutFormat进行),可以进行多次溢出(当写入内存的数据小于默认的100mb时,溢出一次),每一次溢出时都会产生一个溢出文件来记录这些数据。注意:内存中的数据写入磁盘时会进行归并并且排序 即得到上图所示的数据。磁盘中的数据能提供下载服务。shuffle会将各个分区的数据分发到指定的ReduceTask,接下来就是Reduce阶段了
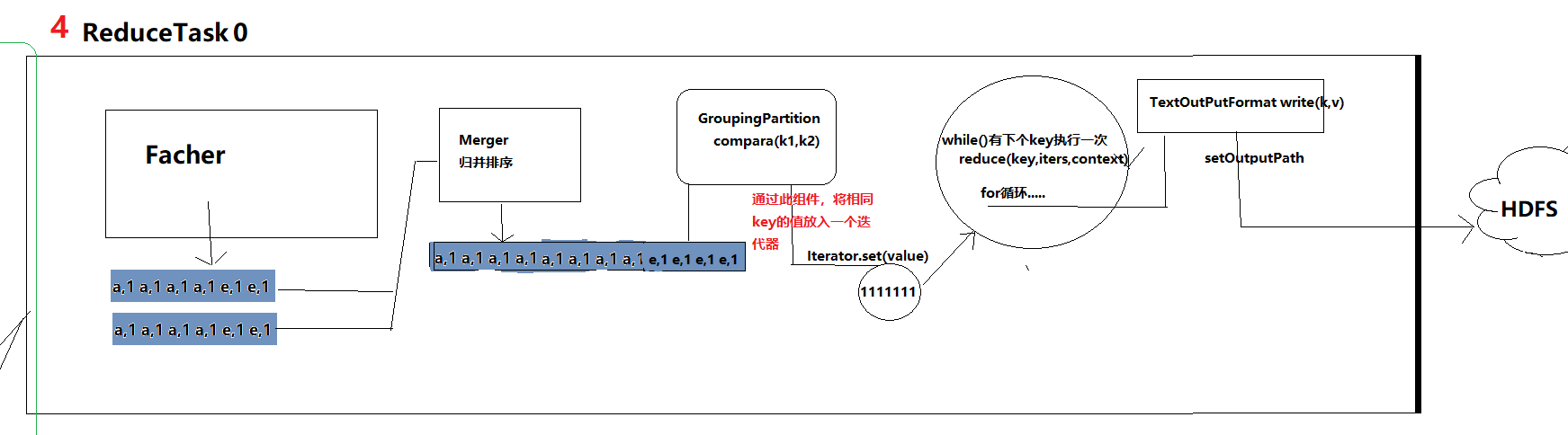
第四步:通过Facher下载到map阶段的数据,并进行归并排序得到一个完整的数据,然后通过GroupingPartition组件中的compare方法判断key是否相同,进而将相同key的值放入同一个迭代器。最后就是从迭代器中获取这些数据,进行一定的操作得到自己想要的数据格式,然后存入指定地方,上图是存入HDFS中,至此整个MR程序数据流程就算走完了
2. yarn
2.1 概述:
yarn是一个资源管理系统。主要负责集群资源的管理和调度,如果要将程序运行在yarn上需要两个组件 , 客户端和ApplicationMaster , 这个组件在编程的过程中非常复杂 , 例如mapreduce运算框架有现成的实现类供程序员使用(JobClient , MRAppMaster)
- 资源管理平台 管理集群的运算资源 和 资源分配
-
程序运行的监控平台 监控各个程序的运行状况 (程序任务的再处理分配)
MRAppMaster 是applicationMaster的一种实现 , 可以将MapReduce程序运行在yarn上 .
MRAppMaster主要负责MapReduce程序的生命周期,作业管理 , 资源申请和再分配,Container的启动和释放
2.2 ResourceManager和NodeManager
(1) ResourceManager(RM)
RM是一个全局资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager, ASM)。
- 调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
需要注意的是:该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
- 应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等
(2)NodeManager
a. 汇报自己的节点的资源情况
b. 领取属于自己的任务,运行任务
c 汇报自己处理的任务的执行情况
2.3 多角度理解yarn
2.3.1 并行编程
在单机程序设计中,为了快速处理一个大的数据集,通常采用多线程并行编程,其大致流程如下:先由操作系统启动一个主线程,由他负责数据切分、任务分配、子线程启动和销毁等工作,而各个子线程只负责计算自己的数据,当所有子线程处理完数据后,主线程再退出。类比理解,YARN上的应用程序运行过程与之非常相近,只不过它是集群上的分布式并行编程。可将YARN看做一个云操作系统,它负责为应用程序启动ApplicationMaster(相当于主线程),然后再由ApplicationMaster负责数据切分、任务分配、启动监控等工作,而由ApplicationMaster启动的各个Task(相当于子线程)仅负责自己的计算任务。当所有任务计算完成后,ApplicationMaster认为应用程序运行完成,然后退出
2.3.2 资源管理系统

2.4 yarn的安装
(1)因为安装了hadoop,所以直接配置yarn-site.xml文件,配置文件如下:
<configuration> <!-- 配置resourcemanager的机器的位置,这样所有的nodemanager就能找到其位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>feng01</value> </property> <!-- 为mr程序提供shuffle服务,提高数据传输效率,rpc传输效率低 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 一台NodeManager的总可用内存资源 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value> </property> <!-- 一台NodeManager的总可用(逻辑)cpu核数 --> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value> </property> <!-- 是否检查容器的虚拟内存使用超标情况 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 容器的虚拟内存使用上限:与物理内存的比率 --> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property> </configuration>
(2)然后将yarn-site.xml远程复制到feng02,feng03,feng04
(3)开启:start-yarn.sh,其会读取slaves文件,启动nodemanager
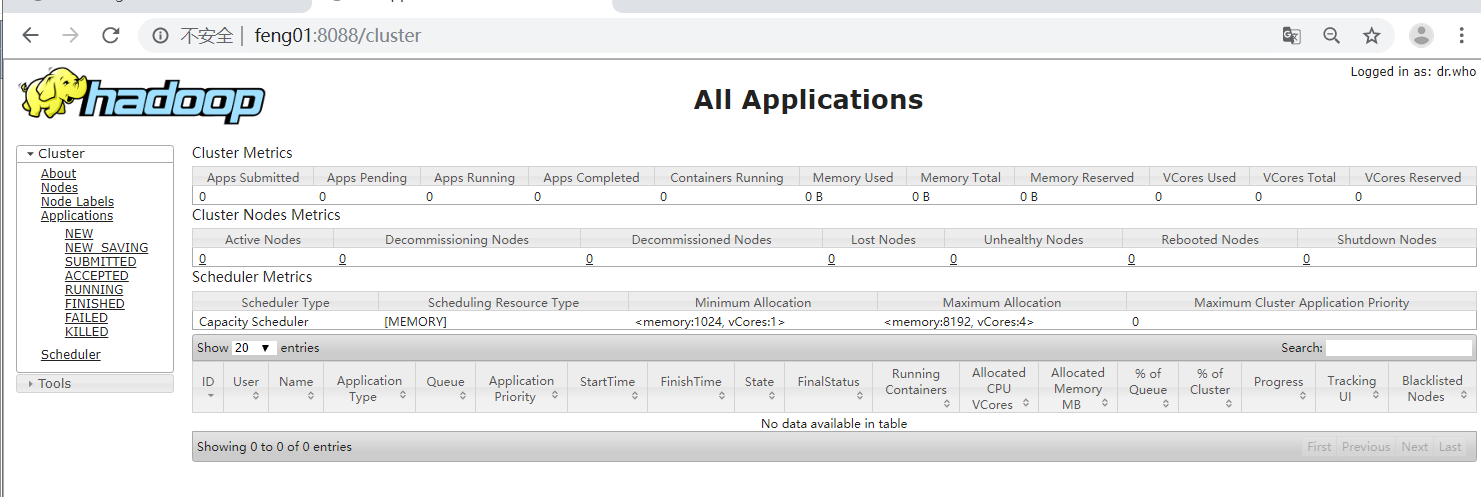
(4) 访问feng01:8088,即可得到如下界面
2.5 程序提交到yarn
2.5.1 window提交
删除HDFS根目录上的所有文件命令hdfs dfs -rm -r hdfs://feng01:9000/*(要写上绝对路径)
以以前的单词统计为案例
JobDriver


public class JobDriver { public static void main(String[] args) throws Exception { // 当前操作的用户名 System.setProperty("HADOOP_USER_NAME", "root") ; // 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); // 默认 的情况程序以本地模式local运行 // 修改运行模式 conf.set("mapreduce.framework.name", "yarn"); // 设置resource manage机器的位置 conf.set("yarn.resourcemanager.hostname", "feng01"); //设置操作的文件系统 HDFS conf.set("fs.defaultFS", "hdfs://feng01:9000/"); // windows运行程序在yarn上的夸平台参数 conf.set("mapreduce.app-submission.cross-platform", "true"); Job job = Job.getInstance(conf); // 设置程序的jar包的路径 job.setJar("d://wc.jar"); // job.setJarByClass(JobDriver.class); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 设置map端输出的key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置reduce的key-value的类型 结果的最终输出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置reducetask的个数 默认1个 //job.setNumReduceTasks(3); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("/data/wc/input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("/data/wc/output2")); // 提交任务 参数等待执行 job.waitForCompletion(true) ; } }
WordCountMapper
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ /** * 当nextKeyValue() map * map方法是自己的自定义的map阶段的业务逻 * map方法何时执行??? * 一行数据执行一次 * 参数一 当前一行数据的偏移量 * 参数二 当前这行数据 * 参数三 context 上下文件 结果的输出 输出给reduce */ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //获取一行数据 String line = value.toString(); String[] words = line.split(" "); for (String word : words) { // context.write(new Text(word), new IntWritable(1));//a 1 a 1 a 1 } } }
WordCountReducer
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ /** * context.nextKey() 相同的key会被聚合到一个reduce方法中 * 执行时机 一个单词执行一次 * key 单词 * values 将当前的单词出现的所有的1 存储在迭代器中 * */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : values) { count++ ; } // key是单词 count是单词对应的个数 context.write(key, new IntWritable(count)); } }
2.5.2 linux提交
public class JobDriver { public static void main(String[] args) throws Exception {// 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); // 默认 的情况程序以本地模式local运行 // 修改运行模式 conf.set("mapreduce.framework.name", "yarn"); // 设置resource manage机器的位置 conf.set("yarn.resourcemanager.hostname", "feng01"); //设置操作的文件系统 HDFS conf.set("fs.defaultFS", "hdfs://feng01:9000/"); // 获取Job对象 Job job = Job.getInstance(conf); // 设置程序的jar包的路径 job.setJar("d://wc.jar"); job.setJarByClass(JobDriver.class); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 设置map端输出的key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置reduce的key-value的类型 结果的最终输出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置reducetask的个数 默认1个 //job.setNumReduceTasks(3); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("/data/wc/input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("/data/wc/output2")); // 提交任务 参数等待执行 job.waitForCompletion(true) ; } }
3. merger案例(小文件合并)
由于mr程序中map任务的个数是按照文件的个数来决定的,默认是一个map任务处理一个文件,若是很多小文件的话,就需要很多mapTask去处理,这样就会很浪费资源
HDFS不适合存储小文件,MR程序不适合处理小文件
若实在是有太多的小文件,解决方法:
- 将小文件合并之后再 存储
- 如果小文件被存储在HDFS中,不要使用默认的启动maptask个数的算法,minSize(100)
在HDFS中有个文件夹中存在大量的小文件待处理
1) 默认的情况下一个文件产生一个maptask任务去处理 产生大量的maptask 慢
2) 小文件存储在HDFS中 每个文件都有元数据的记录 ,在namenode中的元数据是记录在内存中一份
在存储的数据一定大小的情况下增加了namenode的工作压力
记录大量的元数据信息 ,整个集群的存储能力降低
4 数据倾斜
在数据按照key进行分区的时候 会产生一个区分的数据特别多 一个特别少 出现了数据倾斜问题。只有数据多的任务结束 任务才算结束 整体的任务时间很长。
解决方法:
(1)避免分区
(2)key中拼接随机数
5. join案例
有两个文件user.txt, order.txt,如下
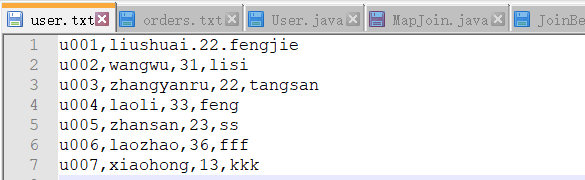
需求:获取oid+user的拼接信息
代码如下
JoinBean
public class JoinBean implements Writable { private String oid; private String uid; private String name; private int age; private String fd; /** * 标识类中存储的是哪个文件的数据 */ private String table; public String getOid() { return oid; } public void setOid(String oid) { this.oid = oid; } public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public String getFd() { return fd; } public void setFd(String fd) { this.fd = fd; } public String getTable() { return table; } public void setTable(String table) { this.table = table; } @Override public String toString() { return uid + "," + name + "," + age + "," + fd; } /** * 在序列化的时候有读写的字段 读写的字段不能为null */ @Override public void readFields(DataInput din) throws IOException { this.oid = din.readUTF(); this.uid = din.readUTF(); this.name = din.readUTF(); this.age = din.readInt(); this.fd = din.readUTF(); this.table = din.readUTF(); } /* @Override public String toString() { return "JoinBean [oid=" + oid + ", uid=" + uid + ", name=" + name + ", age=" + age + ", fd=" + fd + ", table=" + table + "]"; }*/ @Override public void write(DataOutput dout) throws IOException { dout.writeUTF(this.oid);// dout.writeUTF(this.uid); dout.writeUTF(this.name); dout.writeInt(this.age); dout.writeUTF(this.fd); dout.writeUTF(this.table); } }
此处的注意点:在序列化的时候有读写的字段,读写的字段不能为null
Join
public class Join { static class JoinMapper extends Mapper<LongWritable, Text, Text, JoinBean> { // 读取数据 根据文件名 将数据封装在不同的table标识的类 String name = null ; @Override protected void setup(Mapper<LongWritable, Text, Text, JoinBean>.Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit)context.getInputSplit(); name = fs.getPath().getName(); } Text k = new Text() ; JoinBean joinBean = new JoinBean() ; @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, JoinBean>.Context context) throws IOException, InterruptedException { try { String line = value.toString(); if(name.startsWith("orders")) {// 订单数据 //处理数据 String[] split = line.split(","); joinBean.setOid(split[0]); joinBean.setUid(split[1]); joinBean.setName(""); joinBean.setAge(-1); joinBean.setFd(""); joinBean.setTable("orders"); }else {// 用户数据 String[] split = line.split(","); joinBean.setOid(""); joinBean.setUid(split[0]); joinBean.setName(split[1]); joinBean.setAge(Integer.parseInt(split[2])); joinBean.setFd(split[3]); joinBean.setTable("user"); } k.set(joinBean.getUid()) ; context.write(k, joinBean); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } } } static class JoinReducer extends Reducer<Text, JoinBean, Text, NullWritable> { // 聚合同一个人的所有的数据 //iters 里面既有用户的订单数据(多个) 也有用户数据(1) @Override protected void reduce(Text uid, Iterable<JoinBean> iters, Reducer<Text, JoinBean, Text, NullWritable>.Context context) throws IOException, InterruptedException { JoinBean user = new JoinBean(); List<JoinBean> ordersList = new ArrayList<>() ; // 获取当前用户所有的数据 for (JoinBean joinBean : iters) { // 根据这个字段来判断当前迭代的数据是订单数据还是用户信息数据 String table = joinBean.getTable(); if("orders".equals(table)) { // 订单数据 JoinBean order = new JoinBean(); order.setOid(joinBean.getOid()); order.setUid(joinBean.getUid()); //list ordersList.add(order) ; }else {// 用户数据 user.setUid(joinBean.getUid()); user.setName(joinBean.getName()); user.setAge(joinBean.getAge()); user.setFd(joinBean.getFd()); } } for (JoinBean joinBean : ordersList) { // o0001,uid,name,age,fd String key = joinBean.getOid()+","+user.toString() ; context.write(new Text(key), NullWritable.get()); } } } public static void main(String[] args) throws Exception { // 获取mr程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类 调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(JoinMapper.class); job.setReducerClass(JoinReducer.class); // 设置map端输出的key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(JoinBean.class); // 设置reduce的key-value的类型 结果的最终输出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //设置reducetask的个数 默认1个 //job.setNumReduceTasks(3); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("D:\data\join\input")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("D:\data\join\res")); // 提交任务 参数等待执行 job.waitForCompletion(true) ; } }