- 1. HDFS的checkpoint机制
namenode的主要职责是记录用户存储数据的数据元信息(元数据),元数据即为存储在HDFS分布式存储系统上的数据的详细记录信息,其包括数据块,文件存储位置,块的大小,副本的个数文件的权限等等
- 记录元数据的形式有两种
(1)元数据存储在内存中:内存对象(机器宕机后,数据会丢失)
(2)元数据存储在磁盘上:内存对象的序列化文件(机器宕机后,数据不会丢失)
数据记录在内存对象中,这个对象叫FsImage(记录了用户的每一次操作,hadoop中namenode初始化时就会产生这个对象),当操作越来越多时,FsImage对象记录的数据就会越来越多,这个对象就会越来越大,但是内存中的数据存储量有限,这个时候就需要将内存中的数据序列化至磁盘。这个时候又会引发一个问题,定期序列化会有数据丢失的可能(如1天序列化一次时,当机器出现宕机时,当天在内存中的数据就会丢失),但若内存中的每条数据都进行序列化,这就需要频繁的序列化,即内存对象频繁的和磁盘进行IO交换,这样特别耗费系统的资源。那么如何既保证数据尽可能少的丢失(机器出现单点故障时),又能保证尽可能少的耗费系统资源呢。下面看下hadoop是怎么解决这个问题的:
第一步

这样确实能解决数据的丢失,同时也不需要与磁盘进行频繁的IO交互,但每次namenode宕机后,重启该机器时,需要花费大量时间加载日志数据,启动时间过长 ,用户无法操作,这个时候引入secondrayname 用来对存储数据的元数据处理 (checkpoint机制)
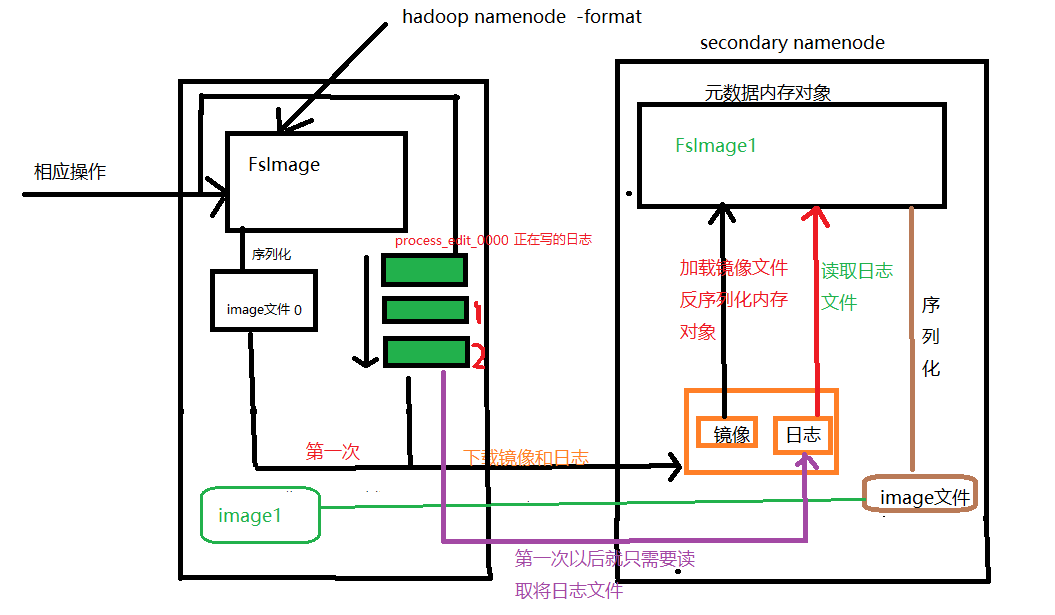
当namenode宕机重启后,其读取的镜像文件就变成image文件,这样就能减少开机的时长。checkpoint的时长可以自己设置,加入是1个小时,那么每个一个小时就会更新出一个image文件,同时也会删除前面的镜像文件以及日志文件
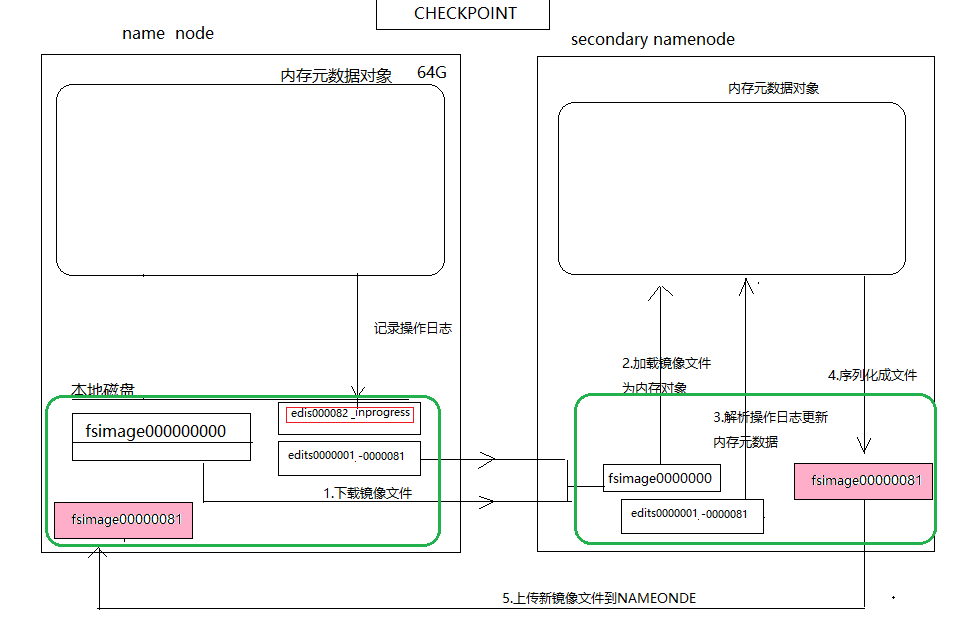
- 大致流程:
下载namenode 的 image文件(初始化文件 ,只下载一次),
下载生成好的日志文件 ,没有正在写的日志文件
加载镜像文件生成内存对象
加载日志文件 , 修改镜像对象
序列化镜像对象 ,
将镜像对象上传到namenode中
清理nameNode 上没用的日志数据和序列化的镜像文件
定期下载日志文件 , 合并镜像对象 , 上传到namenode上
0. 补充更正hadoop1.x的checkpoint
0.1 FsImage和Editslog
- Editslog: 保存了所有对hdfs中文件的操作信息,即记录的是操作的日志
- 是内存元数据在本地磁盘的映射,用于维护文件系统树
FsImage文件和EditsLog文件可以通过ID来互相关联。如果是非HA集群的话,这两个数据文件保存在dfs.namenode.name.dir设置的路径下(即namenode中),会保存FsImage文件和EditsLog文件,如果是HA集群的话,EditsLog文件保存在参数dfs.journalnode.edits.dir设置的路径下,即edits文件由qjournal集群管理。
fsimage和editlog文件
在上图中edit log文件以edits_开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的edit log名字edits_inprogress_txid。该路径下还会保存两个fsimage文件({dfs.namenode.num.checkpoints.retained}在namenode上保存的fsimage的数目,超出的会被删除。默认保存2个),文件格式为fsimage_txid。上图中可以看出fsimage文件已经加载到了最新的一个edit log文件,仅仅只有inprogress状态的edit log未被加载。
在启动HDFS时,只需要读入fsimage_0000000000000008927以及edits_inprogress_0000000000000008928就可以还原出当前hdfs的最新状况。
(FsImageid总是比editslogid小)
那么这两个文件是如何合并的呢?这就引入了checkpoint机制
元数据在内存中:树结构的对象,元数据在磁盘中:内存对象的序列化文件
0.2 checkpoint机制(此处是假设hdfs刚开始使用,即fsimage文件还是空的)
(1)初步解决元数据丢失问题:
hadoop在一开始格式化时,会在磁盘中产生fsimage文件(内存序列化文件),当用户往hdfs读写日志时,其会往editslog写日志,并且是以滚动的方式来写日志的。到这一步时是可以防止元数据丢失问题的,即当机器宕机重启后,通过反序列化fsimage文件内容可以得到元数据存储的树对象,这时该对象会去解析日志文件(按照某种规则去解析,从头开始回放这些日志),然后像java中对象中存储数据的set一样,进行元数据的恢复。元数据丢失的问题是解决了,但若是这个日志文件是记了好几个月的话,namenode宕机的话,这是再去重启这台机器,元数据的恢复就需要大把的时间,即hdfs要很久才能启动,这样在实际业务中就不适合了,那么该怎么办呢?

(2)进一步解决元数据丢失的问题(hadoop1.x的checkpoint机制):
这时就需要引入一个秘书(secondrayname ),定期解析日志文件,得到包含元数据信息的fsImage文件,这样当namenode宕机时,fsimage对象就不需要去解析大量的日志文件,其只需要恢复部分秘书(secondrayname)还没来得及解析的少量日志文件,这样就能符合生产要求了。
(3)hadoop2.0后,使用standbynamenode代替secondrayname
因为文件合并过程需要消耗io和cpu所以需要将这个过程独立出来,在Hadoop1.x中是由Secondnamenode来完成,且Secondnamenode必须启动在单独的一个节点最好不要和namenode在同一个节点,这样会增加namenode节点的负担,而且维护时也比较方便。同样在HA集群中这个合并的过程是由Standbynamenode完成的。
合并的过程:过程类似于TCP协议的关闭过程(四次挥手)
- 首先Standbynamenode进行判断是否达到checkpoint的条件(是否距离上次合并过了1小时或者事务条数是否达到100万条)
- 当达到checkpoint条件后,Standbynamenode会将qjournal集群中的edits和本地fsImage文件合并生成一个文件fsimage_ckpt_txid(此时的txid是与合并的editslog_txid的txid值相同),同时Standbynamenode还会生成一个MD5文件,并将fsimage_ckpt_txid文件重命名为fsimage_txid
- 向Activenamenode发送http请求(请求中包含了Standbynamenode的域名,端口以及新fsimage_txid的txid),询问是否进行获取
- Activenamenode获取到请求后,会返回一个http请求来向Standbynamenode获取新的fsimage_txid,并保存为fsimage.ckpt_txid,生成一个MD5,最后再改名为fsimage_txid。合并成功。
合并的时机:
什么时候进行checkpoint呢?这由两个参数dfs.namenode.checkpoint.preiod(默认值是3600,即1小时)和dfs.namenode.checkpoint.txns(默认值是1000000)来决定
(1) 距离上次checkpoint的时间间隔 {dfs.namenode.checkpoint.period}
(2) Edits中的事务条数达到{dfs.namenode.checkpoint.txns}限制,
事物条数又由{dfs.namenode.checkpoint.check.period(默认值是60)}决
定,checkpoint节点隔60秒就会去统计一次hdfs的操作次数。
2. MapReduce
2.1 概述
mapreduce是hdp提供的一个分布式运算框架,其将两个业务逻辑划分成Map阶段,reduce阶段
MapReduce程序的实现思路
以统计某个大文件的单词个数为例
- 以前的处理方法是直接读取数据,并且一行一行的进行处理,然后存进map中,如下图所示
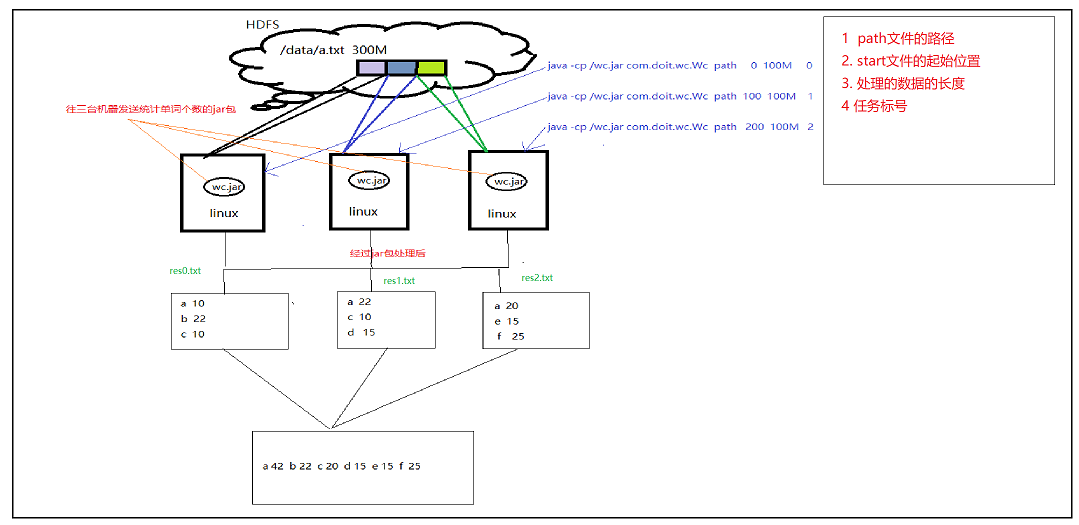
这种处理方式的问题在于,当待处理的文档特别大时,产生的res.txt特别大,这时候下面一台机器统计数据就会很吃力,解决办法如下(mapreduce的实现思路)
- 使用mapreduce的思路去读取并统计单词个数

由上图可知,我们需要做的功做就是map阶段和reduce阶段,若想处理的机器增加,可以将key%n中的n加大,这样处理的机器就变成n台了,效率会更高
2.2 Map阶段(3台机器)
读取数据自己节点的任务数据,处理数据,根据key的hashcode%n的值决定输出结果的位置
MapTask代码


public class MapTask { public static void main(String[] args) throws Exception { // 1 接收命令中的四个参数 String path = args[0]; long start = Long.parseLong(args[1]); long length = Long.parseLong(args[2]); String taskId = args[3]; // 2 根据自己的任务编号和任务的范围读取数据 // 2.1 获取java操作hdfs的客户端对象 URI uri = new URI("hdfs://feng01:9000/"); Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(uri, conf, "root"); // 创建2个输出对象 0, 1,用于将后续的key写入hdfs中 FSDataOutputStream out0 = fs.create(new Path("/data/wc/map_output/res_m_" + taskId + "_0"));// res_m_0_0 FSDataOutputStream out1 = fs.create(new Path("/data/wc/map_output/res_m_" + taskId + "_1"));// res_m_0_1 // 3 读取数据,获取任务的输入流,进行数据处理 FSDataInputStream fis = fs.open(new Path(path)); // 3.1 跳转至读取数据的初始位置 fis.seek(start); // 3.2 将数据包装成缓冲字符流,便于处理 BufferedReader br = new BufferedReader(new InputStreamReader(fis)); // 3.3 数据处理 // 3.3.1 丢弃第一行 if(start!=0) { br.readLine(); } String line = null; int len = 0; while((line = br.readLine())!=null) { len += line.length() + 2; String[] words = line.split(" "); for (String word : words) { // 将数据写入相应的文件夹 if(word.hashCode()%2==0) { out0.writeUTF(word + " " + 1 + " "); }else { out1.writeUTF(word + " " + 1 + " "); } } if(len>length) { break; } } // 4 释放资源 out0.close(); out1.close(); br.close(); fis.close(); fs.close(); } }
2.2 Reduce阶段(2台机器)
根据自己的任务编号处理对应的map产生的中间结果we年,最终统计处全局的数据结果
ReduceTask代码
public class ReduceTask { public static void main(String[] args) throws Exception{ Map<String, Integer> map = new HashMap<String, Integer>(); String taskId = args[0] ;// 0 1 // 获取操作hdfs 的客户端对象 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://feng01:9000"), conf, "root"); // 遍历文件夹下的所有的文件 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/data/wc/map_output"), false); while(listFiles.hasNext()) { LocatedFileStatus file = listFiles.next(); Path path = file.getPath(); // 获取文件名 String name = path.getName(); // 根据文件名的后一个字母来判断要处理的文件 if(name.endsWith(taskId)) { // 处理 // 读取文件 FSDataInputStream fis = fs.open(path); BufferedReader br = new BufferedReader(new InputStreamReader(fis)); String line = null ; while((line = br.readLine())!=null) { String[] split = line.split(" ") ; String word = split[0] ;// map.put(word, map.getOrDefault(word, 0)+1) ; } br.close(); fis.close(); } } // 所有的结果数据在map中 FSDataOutputStream out = fs.create(new Path("/data/wc/reduce_out/res_r_"+taskId)); Set<Entry<String,Integer>> entrySet = map.entrySet(); for (Entry<String, Integer> entry : entrySet) { out.writeUTF(entry.getKey()+" "+entry.getValue()+" ");//换行 } out.flush(); out.close(); fs.close(); } }
2.3 MR执行过程
待操作的文件路径为/data/wc/word.txt,大小接近900M,将上述代码导出成jar包为wc.jar
map阶段:
(1)分别在三台机器执行下列命令
hadoop jar /wc.jar com._51doit.day03.MapTask /data/wc/word.txt 0 3000 0
hadoop jar /wc.jar com._51doit.day03.MapTask /data/wc/word.txt 3000 3000 1
hadoop jar /wc.jar com._51doit.day03.MapTask /data/wc/word.txt 6000 3000 2
Reduce阶段
(2)分别在两台机器上执行下列命令
hadoop jar /wc.jar com._51doit.day03.ReduceTask 0
hadoop jar /wc.jar com._51doit.day03.ReduceTask 1
上面命令执行完可得到如下结果(在HDFS上的显示如下)
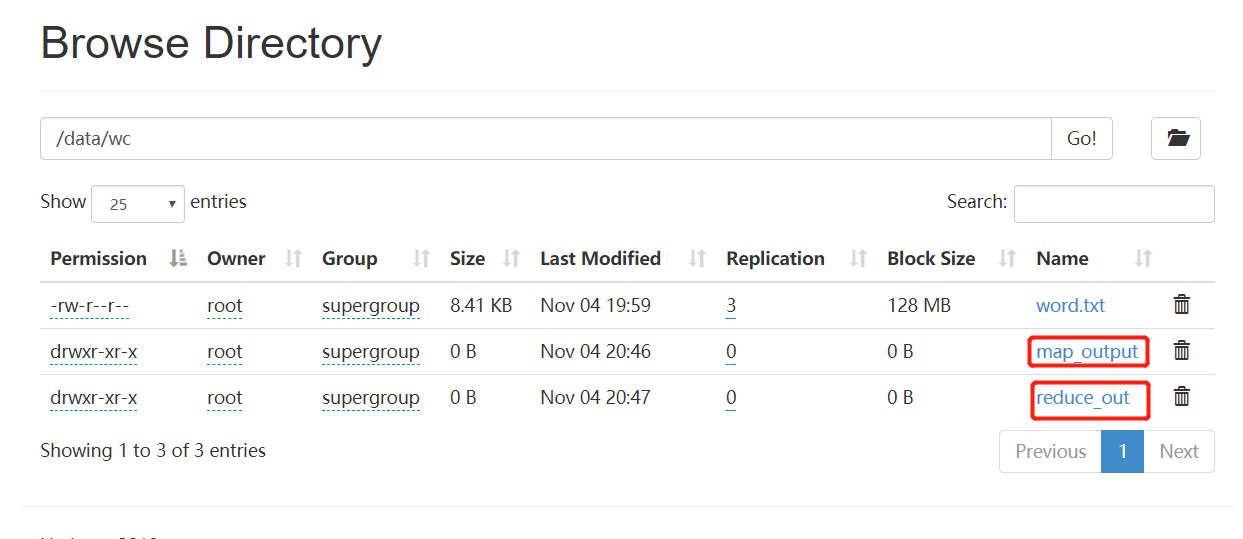
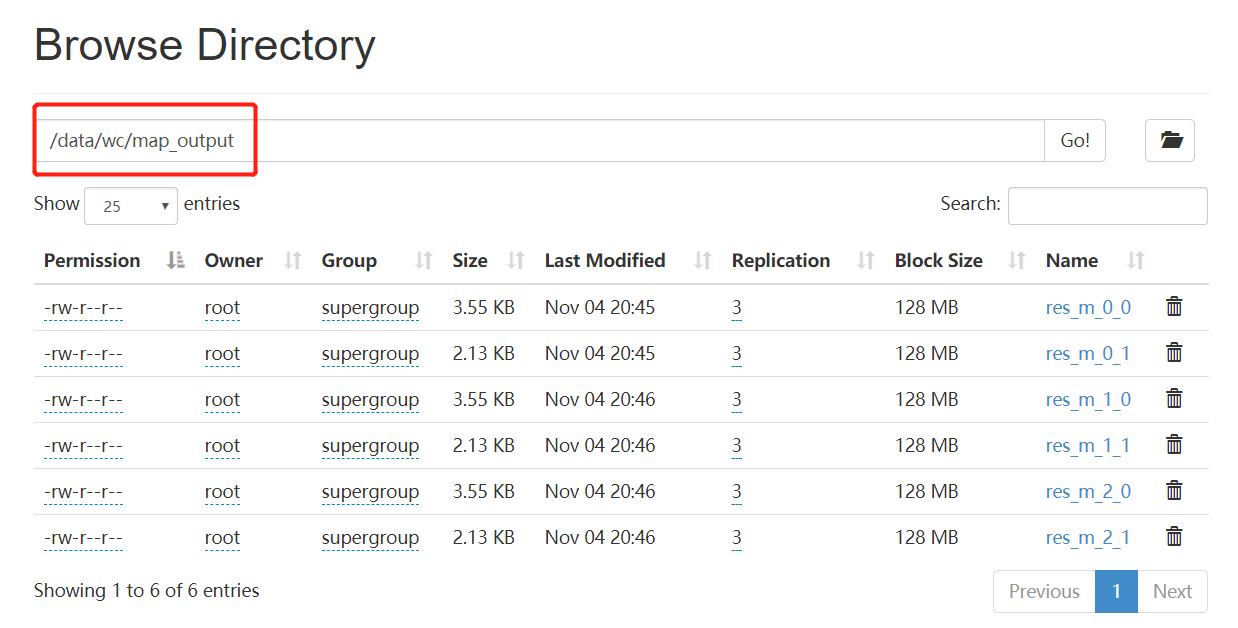

2.4 HADOOP中的MapReduce
MR程序的运行模式:
2.4.1 本地测试模式(local测试模式)
2.4.1.1 Mapper任务阶段
(1) mapper任务可以直接继承MR程序提供的Mapper类,其形式如下:
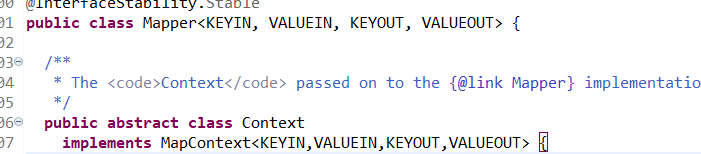
- 输入参数:
参数一:KEYIN就是当前行数据的偏移量(即当前行相对整个文档的起始位置,并不是指某一行,比如第一行偏移量为0,第二行则为 0+第一行内容的长度) 长度===>Long
参数二:VALUEIN就是当前这行数据 line====>String
- 输出参数
参数三:KEYOUT就是表示key(此处是单词) a----->String
参数四:VALUEOUT是key的值(此处是单词的个数) 1---->int
- MR程序默认处理的数据就是文本文件
- 默认的数据是一行一行获取的
(2) maptask阶段
使用内部的默认框架编程(即继承Mapper类)。MR程序中所有数据在处理的时候都是以keyvalue的形式处理的。在hdp内部有自己的一套序列化机制,我们的key和value应该有自己的数据组织类型
Long -------> LongWritable
String-------> Text
Integer-------> IntWritable
代码部分
/** * 参数一:当前行数据的偏移量 * 参数二:当前这行数据 * 参数三:context上下文,结果的输出(输出给reduce) * @author ASUS * */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } }
注意:上述map方法是自己自定义的业务逻辑,其执行的条件为存在nextKeyValue(即存在下一行的数据),源码如下(Mapper自己开启了个线程)

2.4.1.2 Reduce任务阶段
(1)同Mapper一样,MR程序内部同样提供了一个Reducer类供reduce任务继承,如下

参数一:KEYIN 对应map的keyout类型 Text
参数二: VALUEIN对应map的valueout类型 IntWritable
参数三:Text
参数四:IntWritable
相同key的值会被聚合到一个迭代器中,即下面的values中,然后就可以遍历统计数值了
代码部分:
public class WorkCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable intWritable : values) { count++; } context.write(key, new IntWritable(count)); } }
Reducer类的部分源代码
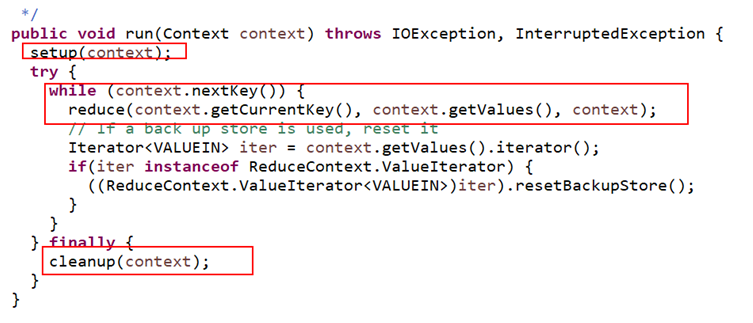
注意:
map方法什么时候执行???
读取数据时,每读取一行数据就执行一次map
reduce方法什么时候执行???
处理由map阶段得到的key value的数据,每处理这些数据中的一个key时,就会执行一次reduce(key所有的值都在迭代器中)
2.4.1.3 测试
JobDriver代码
/** * 用来描述一个作业job(使用哪个mapper类,哪个reducer类,输入文件在哪,输出结果放哪。。。。) * 然后提交这个job给hadoop集群 * @author ASUS * */ public class JobDriver { public static void main(String[] args) throws Exception { // 获取MR程序运行时的初始化配置 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 设置map和reduce类,调用类中自定义的map reduce方法的业务逻辑 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WorkCountReduce.class); // 设置map端输出key-value的类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 设置reduce端输出key-value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 处理的文件的路径 FileInputFormat.setInputPaths(job, new Path("E:/javafile/word.txt")); // 结果输出路径 FileOutputFormat.setOutputPath(job, new Path("E:/wc/")); // 提交任务,参数 等待执行 job.waitForCompletion(true); } }
运行完后,在目录 E/wc/下会产生如下文件

part-r-00000记录的便是统计的信息
2.4.2 运行在分布式机器上(yarn)