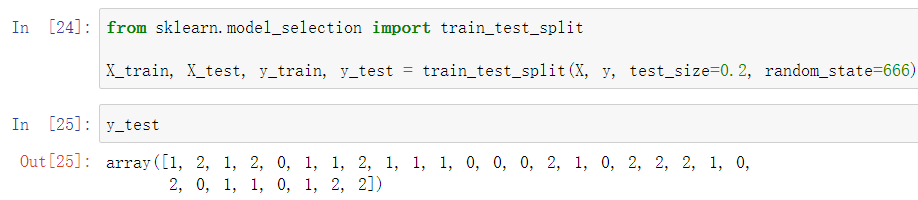
一、使用scikit-learn中的kNN
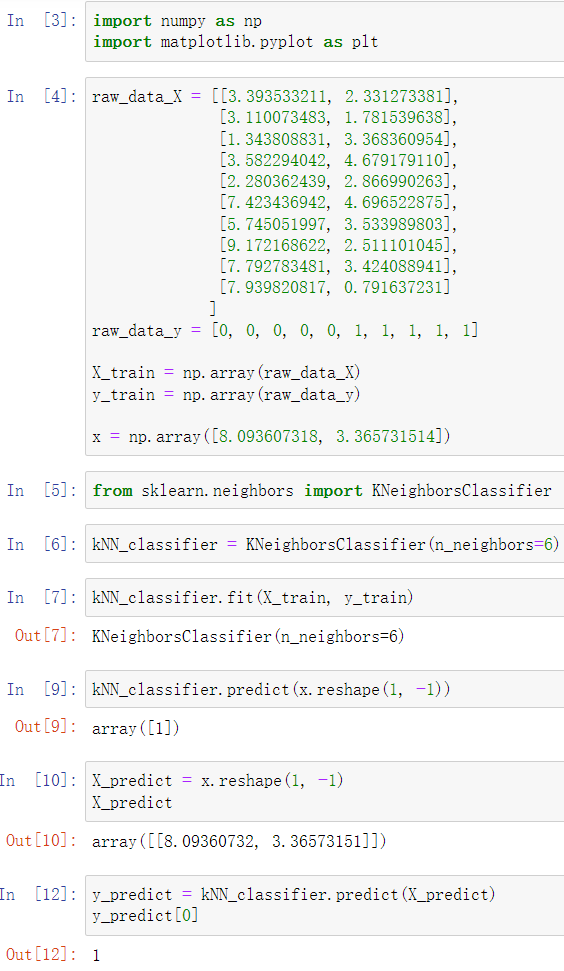
注意:predict传入的参数需为矩阵
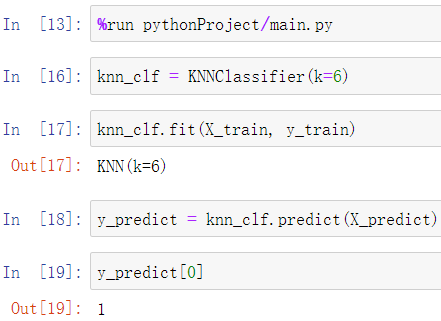
二、自建py文件实现
import numpy as np from math import sqrt from collections import Counter class KNNClassifier: def __init__(self, k): """初始化kNN分类器""" assert k >= 1, "k must be valid" self.k = k self._X_train = None self._y_train = None def fit(self, X_train, y_train): """根据训练数据集X_train和y_train训练kNN分类器""" assert X_train.shape[0] == y_train.shape[0], \ "the size of X_train must be equal to the size of y_train" assert self.k <= X_train.shape[0], \ "the size of X_train must be at least k." self._X_train = X_train self._y_train = y_train return self def predict(self, X_predict): """给定待预测数据集X_predict,返回表示X_predict的结果向量""" assert self._X_train is not None and self._y_train is not None, \ "must fit before predict!" assert X_predict.shape[1] == self._X_train.shape[1], \ "the feature number of X_predict must be equal to X_train" y_predict = [self._predict(x) for x in X_predict] return np.array(y_predict) def _predict(self, x): """给定单个待预测数据x,返回x的预测结果值""" assert x.shape[0] == self._X_train.shape[1], \ "the feature number of x must be equal to X_train" distances = [sqrt(np.sum((x_train - x) ** 2)) for x_train in self._X_train] nearest = np.argsort(distances) topK_y = [self._y_train[i] for i in nearest[:self.k]] votes = Counter(topK_y) return votes.most_common(1)[0][0] def __repr__(self): return "KNN(k=%d)" % self.k
三、判断机器学习算法的性能
在实际使用中,我们无法在生产环境测试算法的好坏,例如股票预测系统要求实时性,或无法获得相应的标记进行检验。
此时,我们可以将已有数据集分为两部分:训练数据集(绝大部分),测试数据集(较小部分),
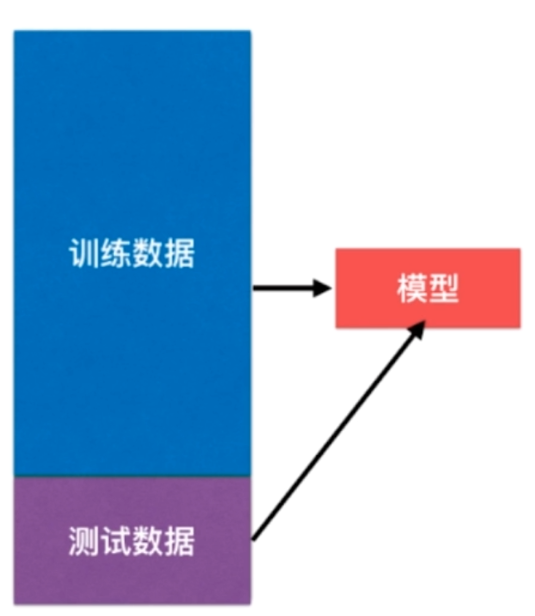
根据训练数据集训练出模型,并使用测试数据集进行检验,从而判断模型的好坏并改进。
设定测试样本的比例(20%)
代码实现如下:
def train_test_split(X, y, test_ratio=0.2, seed=None): """将数据 X 和 y 按照test_ratio分割成X_train, X_test, y_train, y_test""" assert X.shape[0] == y.shape[0], \ "the size of X must be equal to the size of y" assert 0.0 <= test_ratio <= 1.0, \ "test_ration must be valid" if seed: np.random.seed(seed) shuffled_indexes = np.random.permutation(len(X)) test_size = int(len(X) * test_ratio) test_indexes = shuffled_indexes[:test_size] train_indexes = shuffled_indexes[test_size:] X_train = X[train_indexes] y_train = y[train_indexes] X_test = X[test_indexes] y_test = y[test_indexes] return X_train, X_test, y_train, y_test
调用该模块并获取训练、测试数据集,注意:kNN算法不需要生成模型,所以直接使用测试数据集进行测试
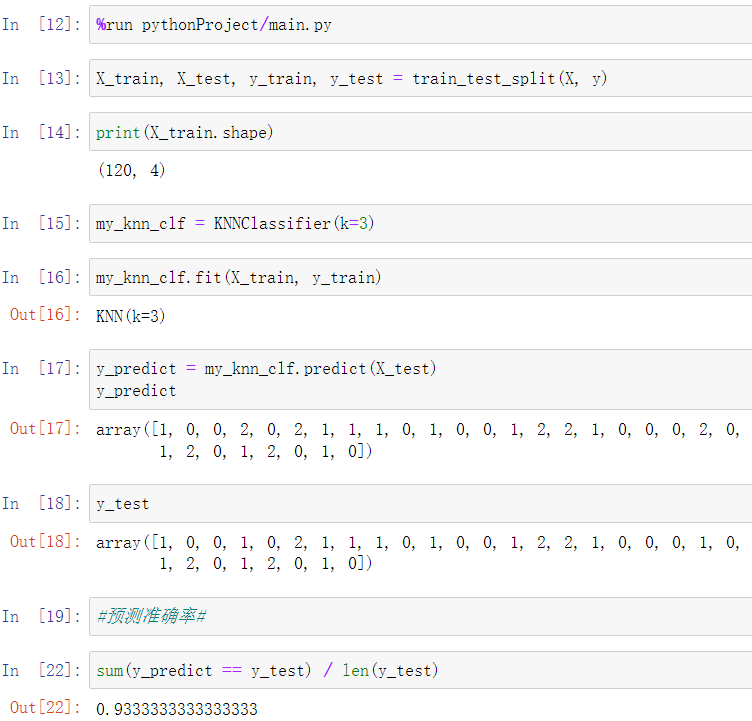
同样地,scikit-learn也封装有实现该功能的方法: