前言
因为本科是计科,没有学过软件工程。在连续上了多节孟宁老师的高级软件工程课程后,我逐渐对软件工程这门学科产生了新认识。过去,我一直没有分清软件与程序的区别,当然,我也从未想过他们俩之间有任何的区别。
“算法 + 数据结构 = 程序”
这是图灵奖获得者Pascal之父——Nicklaus Wirth提出的著名公式,那么,软件呢?
最近,我大概明白了软件与程序的区别。当然,是基于我刚上了几节课之后的朴素思想。软件,在形体上大概是一个程序的集合,但是却与程序在目的上有着本质区别,说白了,软件和程序书写完成之后是给谁看的,给谁用的,这是有很大区别的。
当我们在刷LeetCode的时候,我们写的程序就是为了Accepted;当我们在完成形式化方法课程作业时,我们的程序是为了通过老师写的测试用例。但是,如果用软件的概念来要求普通程序,这个目的就变化了,软件是为了用户服务的,用户的体验才是软件应用的核心,再厉害的代码和程序,抛弃了用户的体验,也不能称之为软件。毕竟,没有用户就没有开发的必要,没有可行性。在围绕用户的体验之下诞生了许许多多的新思想,例如怎么保证软件的质量,怎么方便软件的开发,怎么更好的进行团队合作,方便程序员的同时也方便了用户。毕竟,如果开发的效率都不高,那么用户还怎么用呢,等一个改进版本等到猴年马月?
我想,这也是我们这门学科存在的必要,软件工程,应当是一门研究如何让程序升华为软件的学科,当然,我只是一个软件工程初学者,这还只是我目前的朴素思想。本文旨在结合孟宁老师所给的Menu小程序源码作出分析,总结其中的软件工程思想。Menu小程序即本文的菜单小程序,它是一个命令行小程序,大致的意思就是书写一个通用的命令行程序,在这样的一个程序之中,它能够列举出一系列命令,我们可以输入相应的命令,得到一定的反馈,类似linux,OS X下的终端程序.
菜单小程序运行与调试
环境配置
运行环境:
- Visual Studio Code
- Microsoft C/C++ extension
- GCC Apple clang version 12.0.0
VS Code的安装
Microsoft C/C++ extension安装
GCC GDB安装
代码的导入
使用git clone 克隆项目源码,如下图所示
这其中.vscode文件夹内为VS Code当前项目的配置文件,doc内为GitHub主页上的阅读文件,除源码外其他文件作用如下:
| 文件 | 作用 |
|---|---|
| launch.json | 是VS Code用于程序启动的配置文件 |
| tasks.json | 是VS Code用于编译和构建的配置文件 |
| ch01.md | GitHub阅读文件 |
| README.md | GitHub阅读文件 |
| .gitignore | 过滤掉一些不需要加入git版本管理的文件 |
这里主要介绍一下tasks.json,为下面的调试做铺垫,因为launch.json主要是配置一个程序启动的环境,并不重要,这里略过。
{
"tasks": [
{
"type": "cppbuild",
"label": "C/C++: gcc build active file",
"command": "/usr/bin/gcc",
"args": [
"-g",
"${file}",
"-o",
"${fileDirname}/${fileBasenameNoExtension}"
],
"options": {
"cwd": "/usr/bin"
},
"problemMatcher": [
"$gcc"
],
"group": {
"kind": "build",
"isDefault": true
},
"detail": "Generated task by Debugger"
}
],
"version": "2.0.0"
}
| key | 含义 |
|---|---|
| type | 构建的类型,如cpp类型 |
| label | 任务的名称 |
| command | 执行的命令 |
| args | 执行的参数 |
| options | 可执行的命令程序所在的目录 |
| cwd | 指定命令所在路径 |
| problemMatcher | 额外的选项 |
| group | 定义该任务属于哪一种方式,如build方式 |
| detail | 任务的额外细节 |
| version | 该配置的版本号 |
代码的调试与执行
调试环境配置
点击菜单栏中的Starting Debugging,开始调试,发现报错了。
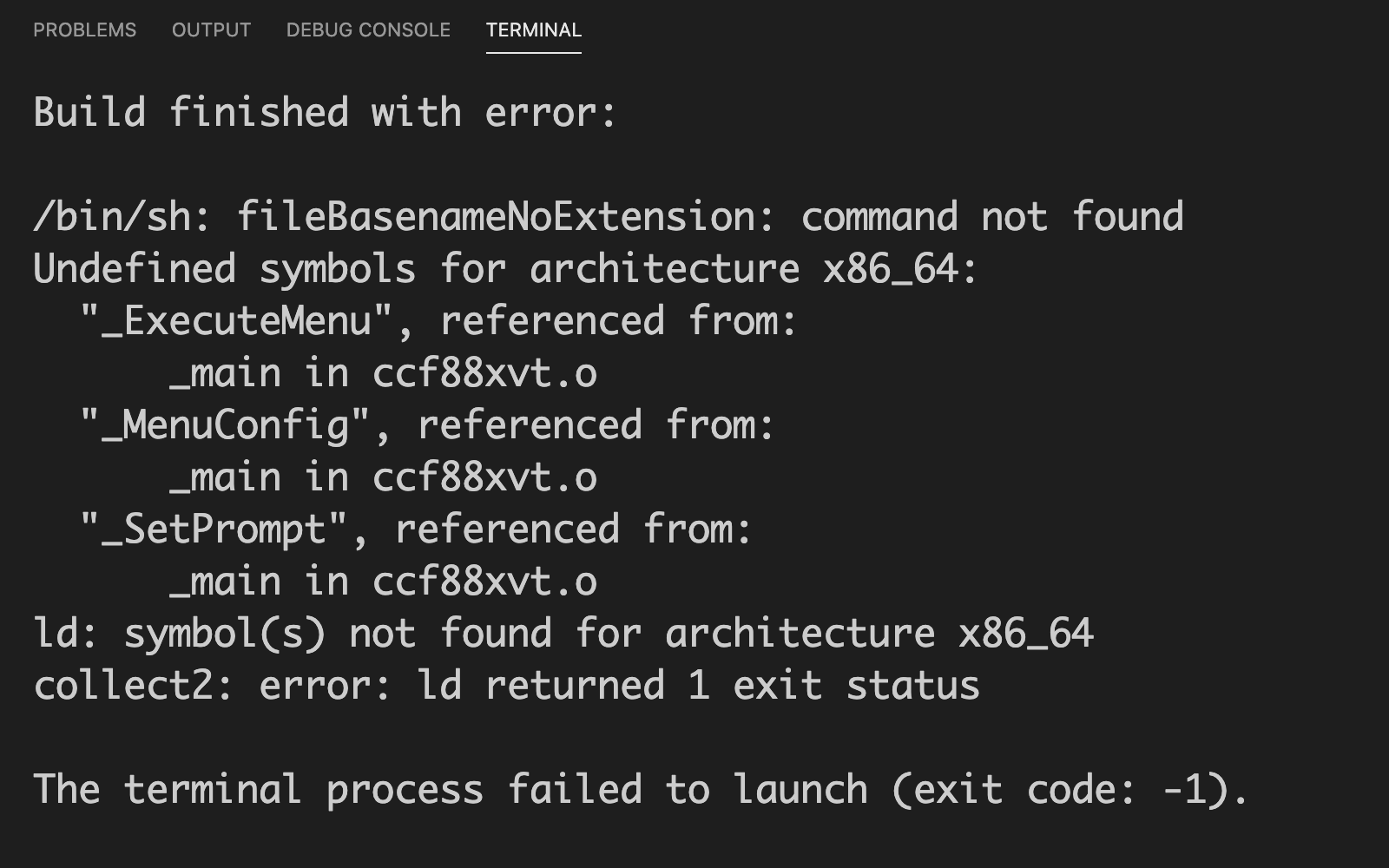
发现是undefined,怀疑是有没文件没有编译,没有连接,回到上面的tasks.json文件中查看编译参数,这些参数变量采用的是shell编程内的一些变量的形式,显然,这里是可以根据我们想编译的文件进行修改的。
"args": [
"-g",
"${file}",
"-o",
"${fileDirname}/$(fileBasenameNoExtension)"
]
毫无疑问,这里是不满足要求的,没有按照我们的意愿将文件构建连接在一起。
因为我们的test程序要求将linktable.c,menu.c,test.c编译后的对象文件连接在一起。
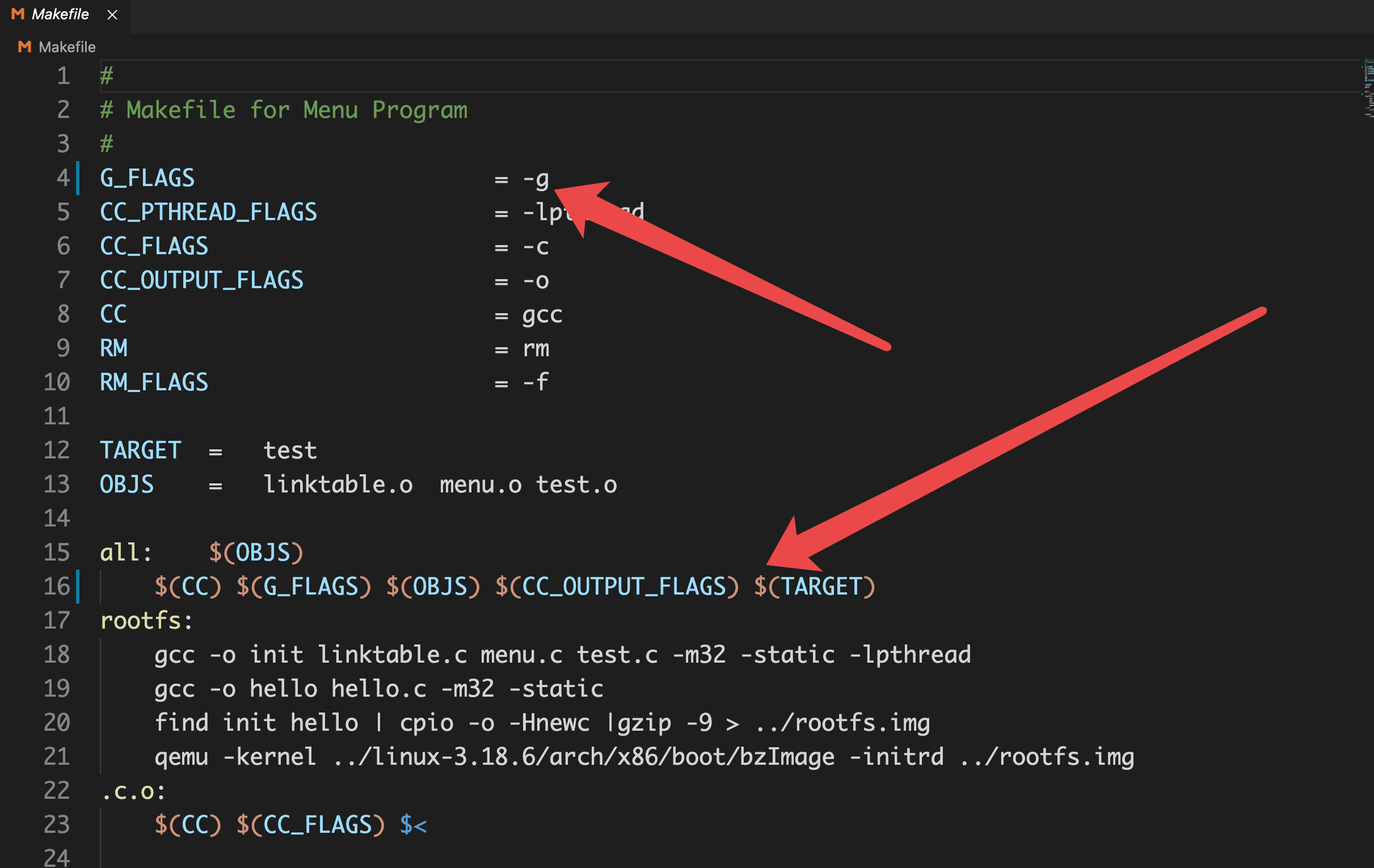
下面有两种思路,第一种,在Makefile文件中加入-g选项,使得Makefile生成的文件可以直接用GDB命令行的方式进行调试:
gcc -g,生成供调试用的可执行文件,使得我们的程序能够在gdb中得到调试。
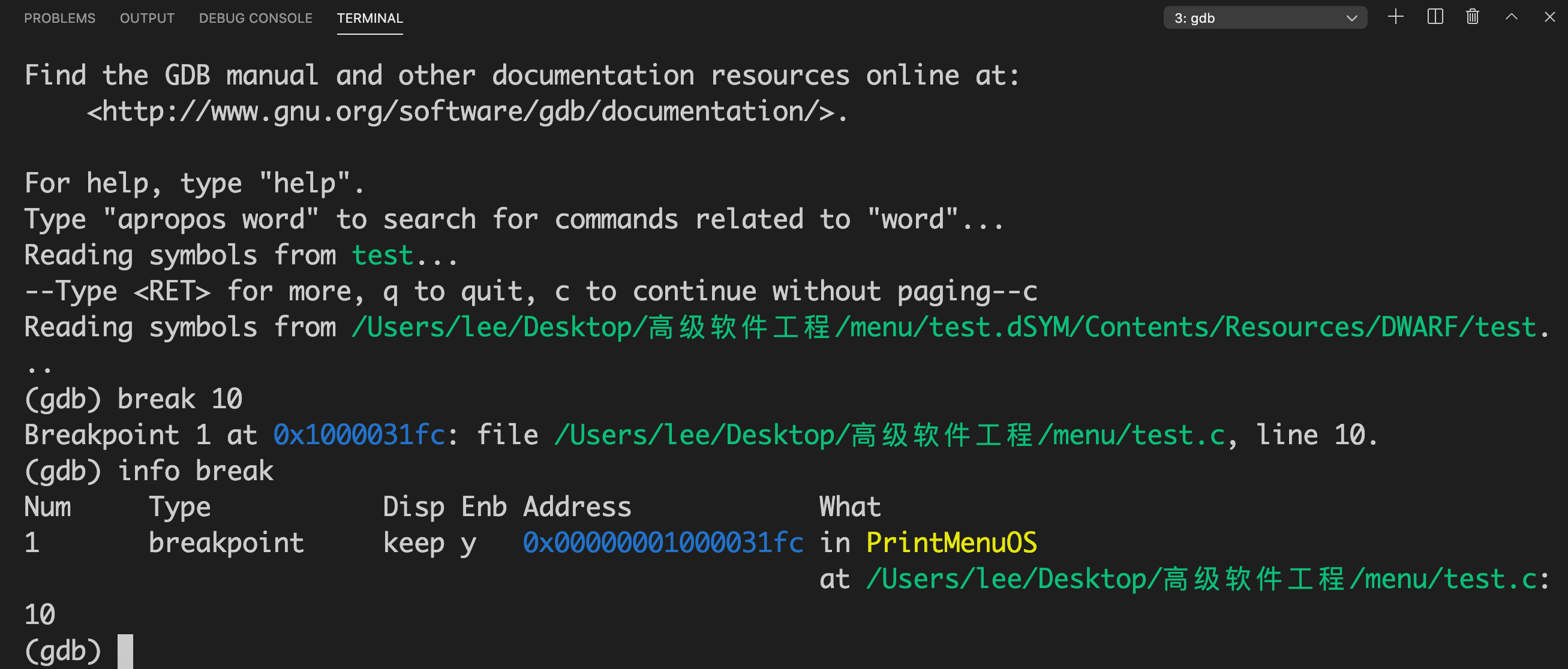
make all之后,我们就可以对其直接用gdb命令进行调试啦:
另一种方法,参考:
https://www.cnblogs.com/--CYH--/p/13943160.html#24-调试项目
右键进行构建,并使用gdb调试
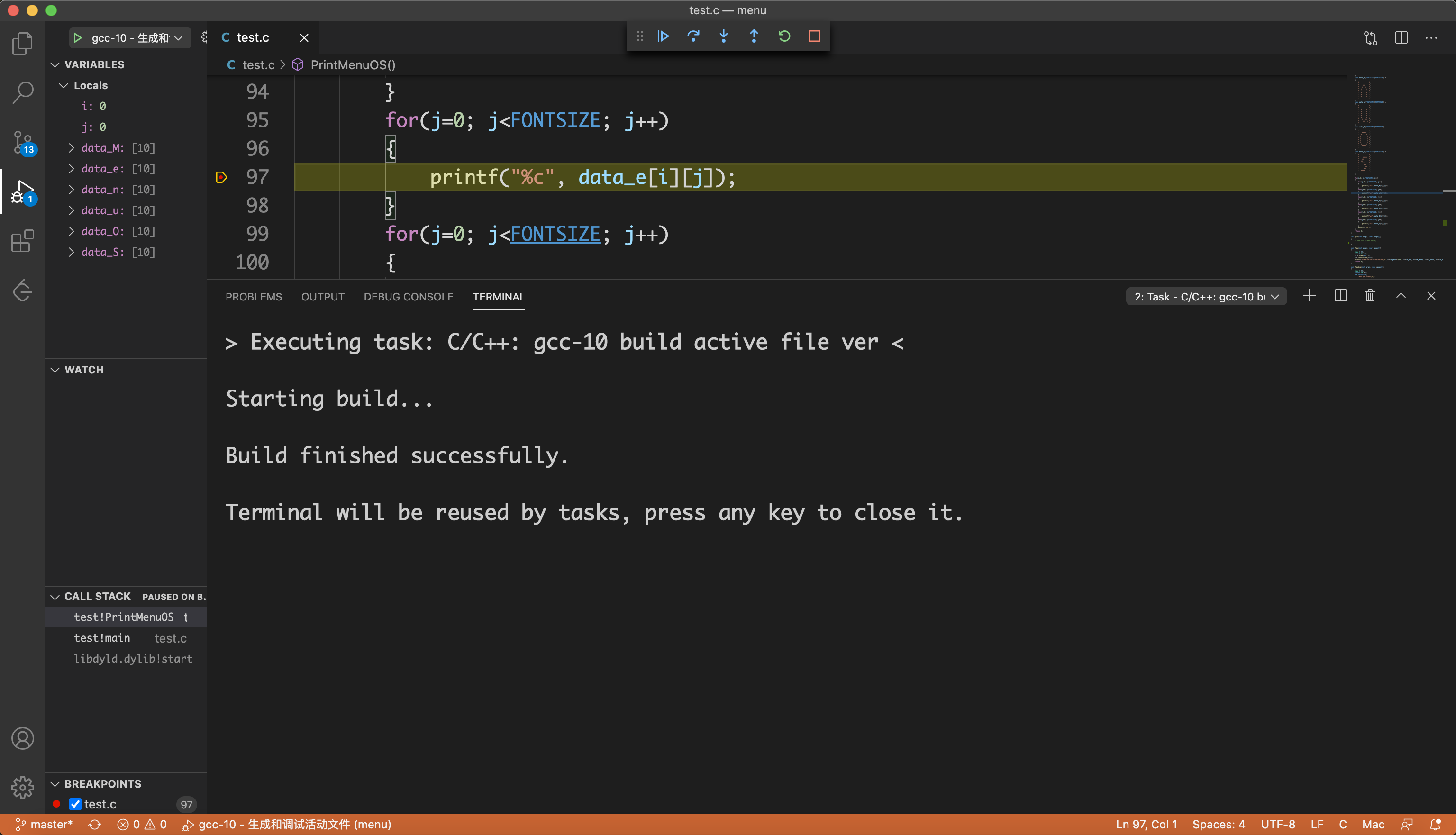
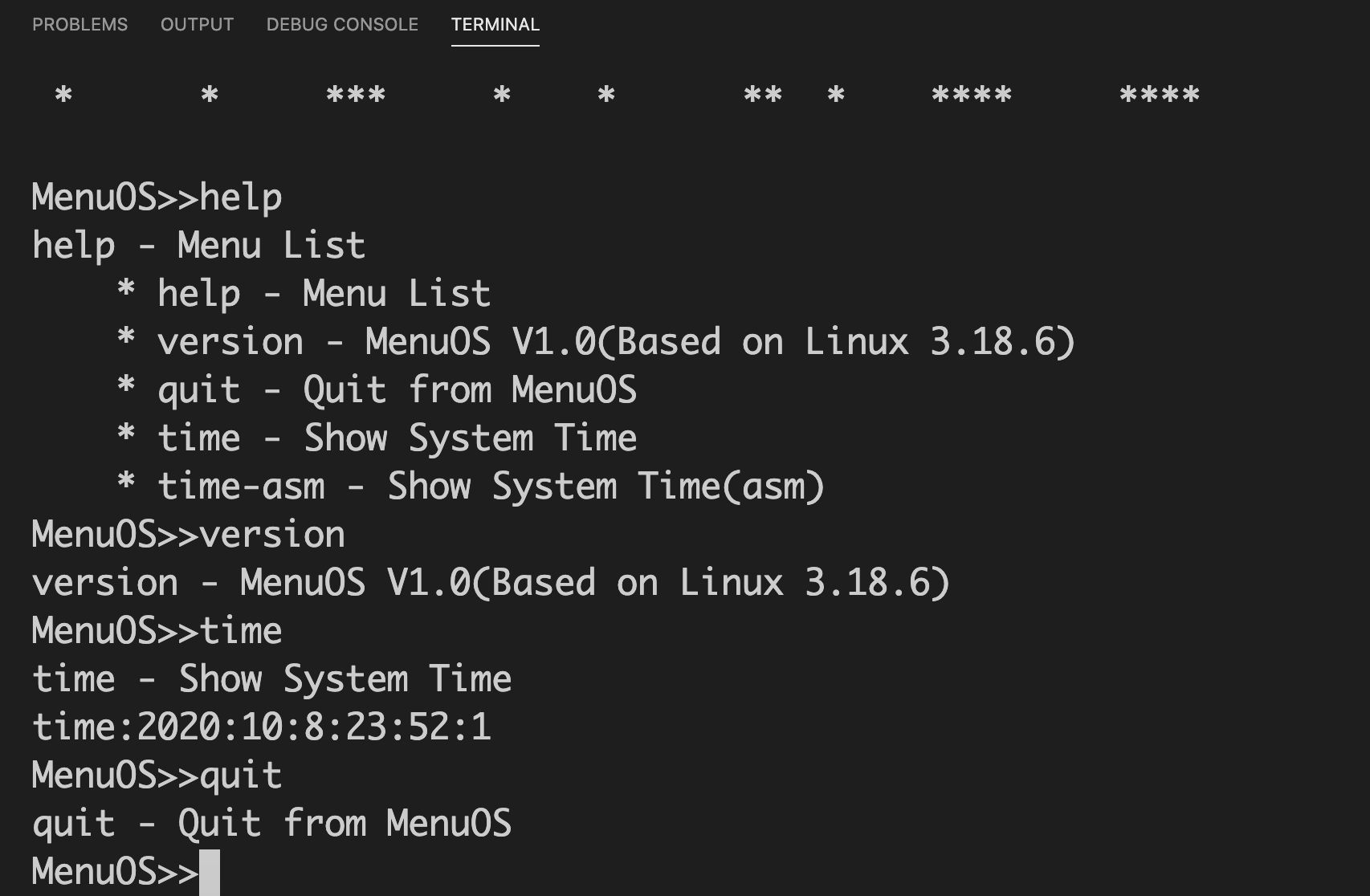
运行结果
根据Makefile文件中的命令,对Menu程序进行构建并执行:

代码中的软件工程
在能够对Menu小程序进行调试和运行后,我们就可以对其中的代码进行分析啦。为了更好地理解软件工程,这里我采用孟宁老师上课所讲的几点并结合自己课外的阅读,对菜单小程序代码内的软件工程思想进行总结和分析。
基于增量模型的迭代式开发
图为孟宁老师在课上展示的一系列的实验:
因为本科时见过隔壁软工同学的毕设是基于敏捷开发的XXXX,一直觉得各种开发设计思路应该在软件工程课程内都有一个对应的抽象模型。毕竟,教学肯定是通用的教学,如果不做抽象,那么一定无法适用大部分的情况。
就着这个思路,我找到了这个模型和开发方式,貌似我们平时的开发也都是这么干的。虽然,这个菜单小程序还太小,不算什么软件,但是从中挖掘一些软工的思想,还是可以的。
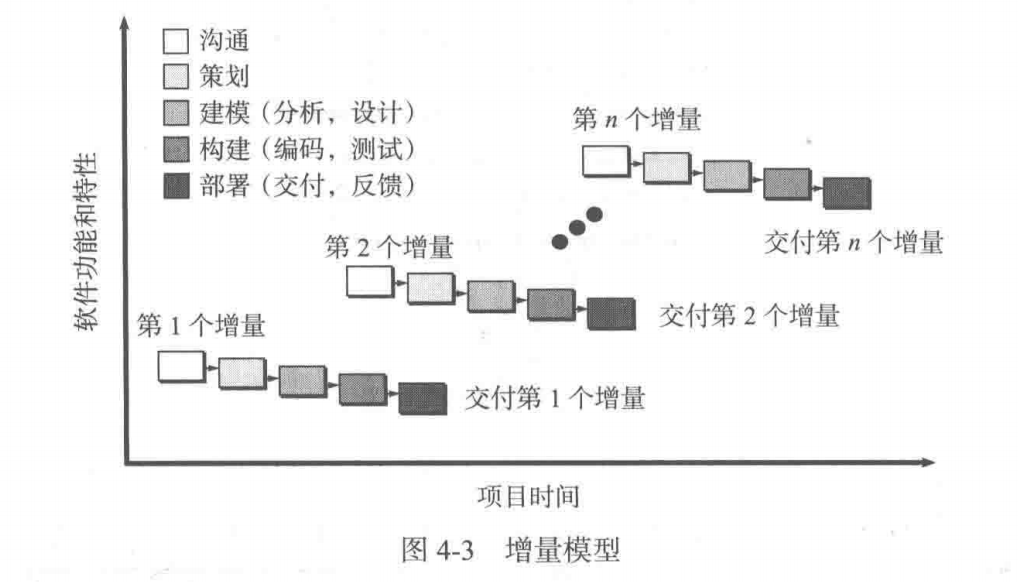
增量模型
增量模型也称渐增模型。使用增量模型开发软件时,把软件产品作为一系列的增量构件来设计、编码、集成和测试。每个构件由多个相互作用的模块构成,并且能够完成特定的功能。
增量模型的特点:将软件看作一系列相互联系的增量,在开发过程的各次迭代中,每次完成其中的一个增量。
每次制定增量计划的时候,客户会使用该核心产品并进行仔细地评估,然后根据评估结果来制定下一个增量计划,并交给技术管理者。
当然,在我们的菜单小程序中并没有这么复杂,其实,所谓的客户就是我们自己,所谓的核心产品就是我们在完成的这个小程序。
迭代式开发
迭代式开发也被称作迭代增量式开发或迭代进化式开发,是一种与传统的瀑布式开发相反的软件开发过程,它弥补了传统开发方式中的一些弱点,具有更高的成功率和生产率。
在迭代式开发方法中,整个开发工作被组织为一系列的短小的小项目,被称为一系列的迭代。每一次迭代都包括了需求分析、设计、实现与测试。采用这种方法,开发工作可以在需求被完整地确定之前启动,并在一次迭代中完成系统的一部分功能或业务逻辑的开发工作。再通过客户的反馈来细化需求,并开始新一轮的迭代。
可以看到,孟宁老师所给的程序源码中大致是属于这样的一个开发方式,我们根据自己想要的需求既担任了客户又担任了技术管理者和开发者。
菜单小程序的增量与迭代
| 版本 | 增量 |
|---|---|
| lab1 | 书写伪代码 |
| lab2 | 简单实现上次的伪代码 |
| lab3.1 | 使用链表遍历代替if-else语句 |
| lab3.2 | 将展示命令,查询命令操作单独模块化 |
| lab3.3 | 将整个链表操作单独模块化 |
| lab4 | 实现动态创建命令,面向接口编程,考虑线程安全问题,创建可重入函数 |
| lab5.1 | 给Linktable增加Callback方式的接口,利用callback函数参数使Linktable的查询接口更加通用 |
| lab5.2 | 将linktable.h中不在接口调用时的必须内容转移到linktable.c中,同时采用Makefile构建程序 |
| lab7.1 | 将Menu程序独立为一个模块 |
| lab7.2 | 增加说明文档 |
| 可以看到,这是一个不断优化,不然完善的过程。 |
规范整洁的编码方式
简明、易读、无二义性的代码风格
一个项目代码的风格就如同一个人给人的印象,代码风格之所以那么重要,是因为它往往决定了代码是否规范、是否易于阅读。代码虽然最终是要给机器看的,但毕竟还是面向程序猿们的编程,程序猿们是要陪伴整个项目开发过程的。在编写代码的过程中,尤其是在协作开发的过程中,如果对方的代码杂乱无章,读起来都费劲,更别说还需要在此基础上进一步开发,这对程序员来说是个巨大的挑战。好的代码风格不仅易于代码的阅读和理解,还能在很大程度上减少一些不必要的语法错误,例如少了 "}" ,如果在编码的时候严格遵循了花括号的对齐规则,那此类错误将容易被避免。
孟宁老师将代码风格分为三重境界:
- 一是规范整洁。遵守常规语言规范,合理使用空格、空行、缩进、注释等;
- 二是逻辑清晰。没有代码冗余、重复,让人清晰明了的命名规则。做到逻辑清晰不仅要求程序员的编程能力,更重要的是提高设计能力,选用合适的设计模式、软件架构风格可以有效改善代码的逻辑结构,会让代码简洁清晰;
- 三是优雅。优雅的代码是设计的艺术,是编码的艺术,是编程的最高追求。
当然,我觉得,即使是老师,应该也不能做到编程的最高追求,一般来说,在我们平时的编码中,无论是刷题,完成作业或者是做项目,我们至少可以做到以下几点:
- 做到代码的语义化,统一采用英文单词书写类名,方法名,变量名,风格上可以采用多种风格,如驼峰命名法或者下划线命名法。
- 书写清晰明了的注释。
- 努力避免程序的二义性,书写测试

在实际的开发中,我们也可以去寻找一些公司的开发规范,如《阿里巴巴Java开发手册》《Google cpp Style Guide》。学习企业开发的规范,能够让我们成为一个与工业界更接轨的码工。
符合程序规范的编码
程序规范就是编程语言自己制定的规范,这类规范如果不满足的话,通常会引起程序报错。例如在Python程序中非常重要的缩进,在C程序中的分号,函数应当返回一个与预设返回值类型同类型的值。当然,随着IDE的快速发展,这类问题通常可以在编写的过程中可以检测出来。
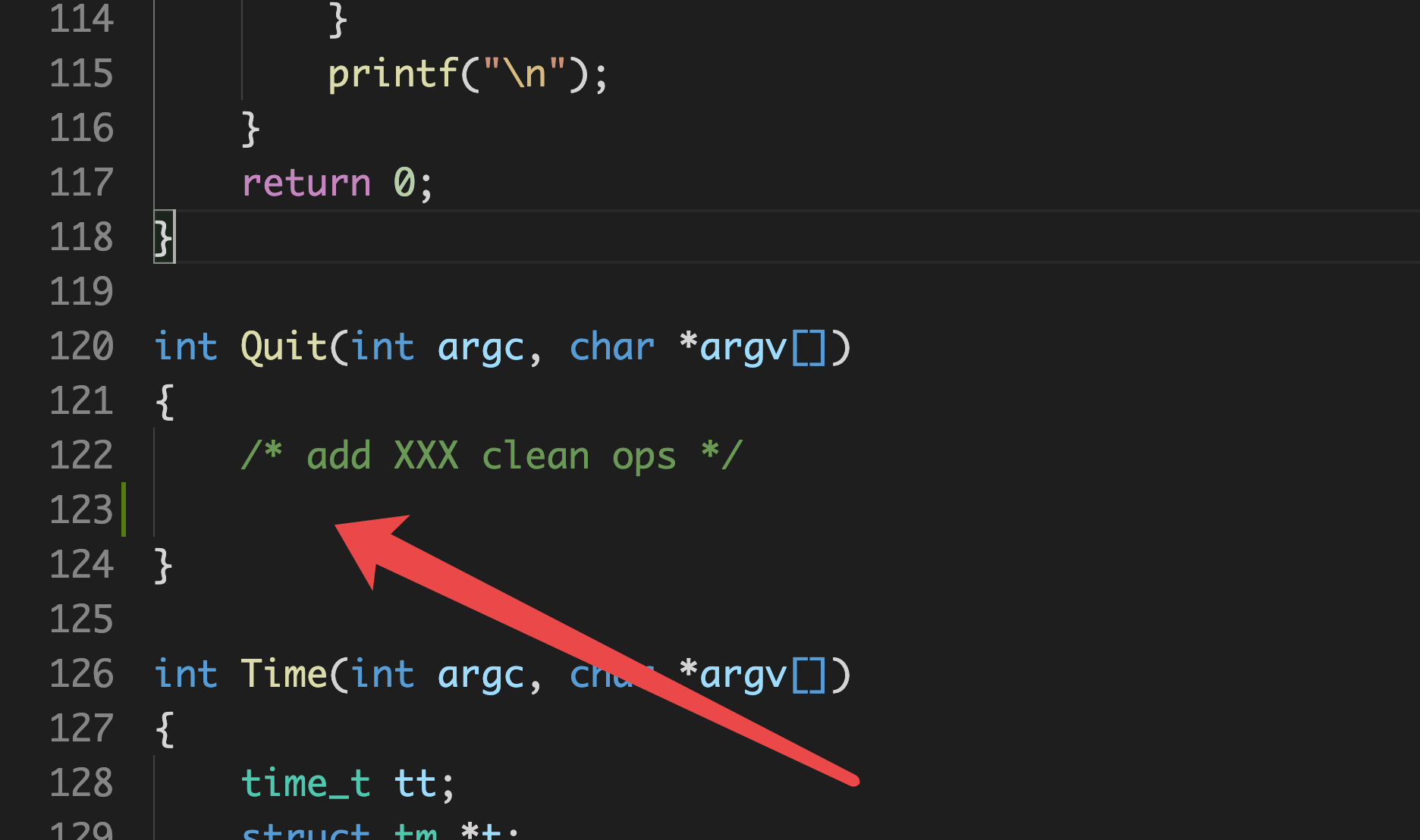
为什么我会写这一条呢?因为我在孟宁老师给的源码中发现了一处函数没有书写返回值的地方,当然,这应该只是孟宁老师还没有实现Quit函数的原因,哈哈哈:
单一职责的模块化编程方法
单一职责
在软件编程中,谁也不希望因为修改了一个功能导致其他的功能发生故障。而避免出现这一问题的方法便是遵循单一职责原则。虽然单一职责原则如此简单,并且被认为是常识,但是即便是经验丰富的程序员写出的程序,也会有违背这一原则的代码存在。
单一职责直白得说,很简单,在面向对象的开发中,就是一个类干一类事,一个方法干一件事。在面向过程的C语言中,就是一个函数干一件事。
单一职责与孟宁老师课件上的KISS原则也相呼应,Keep It Simple & Stupid。当然这里的stupid并非是愚蠢的意思,而是与简单相并列,也是简单的意思,简单到一定地步,自然就是傻瓜式的,也就是“愚蠢的”。
模块化编程
模块化(Modularity)是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立地进行设计和开发。这个做法背后的基本原理是关注点的分离。关注点的分离的思想背后的根源是由于人脑处理复杂问题时容易出错,把复杂问题分解成一个个简单问题,从而减少出错的情形。
模块化的优点:
- 模块化软件设计的方法如果应用的比较好,最终每一个软件模块都将只有一个单一的功能目标,并相对独立于其他软件模块,使得每一个软件模块都容易理解容易开发。
- 整个软件系统也更容易定位软件缺陷bug,因为每一个软件缺陷bug都局限在很少的一两个软件模块内。
- 整个系统的变更和维护也更容易,因为一个软件模块内的变更只影响很少的几个软件模块。
一般我们使用耦合度(Coupling)和内聚度(Cohesion)来衡量软件模块化的程度。
耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合(Tightly Coupled)、松散耦合(Loosely Coupled)和无耦合(Uncoupled)。
一般在软件设计中我们追求松散耦合。
内聚度是指一个软件模块内部各种元素之间互相依赖的紧密程度。
理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性(Feather)。
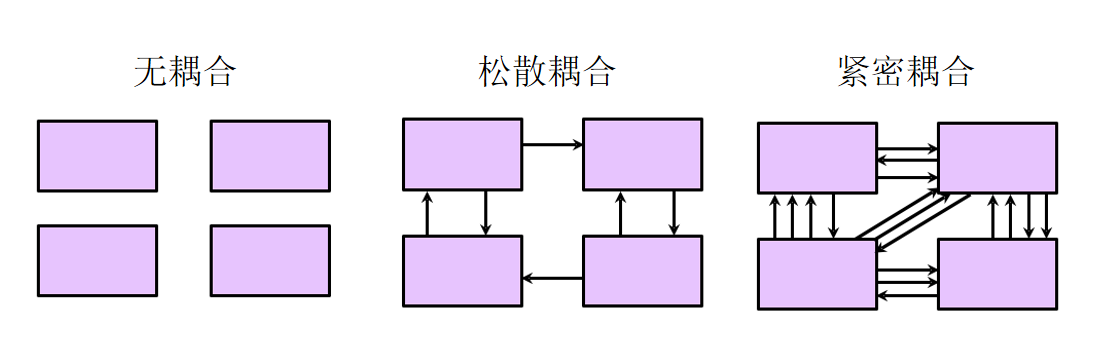
如果能够在软件开发中很好的应用单一职责,KISS原则,那么功能内聚度也就会越来越高。
下面结合菜单小程序进行分析:
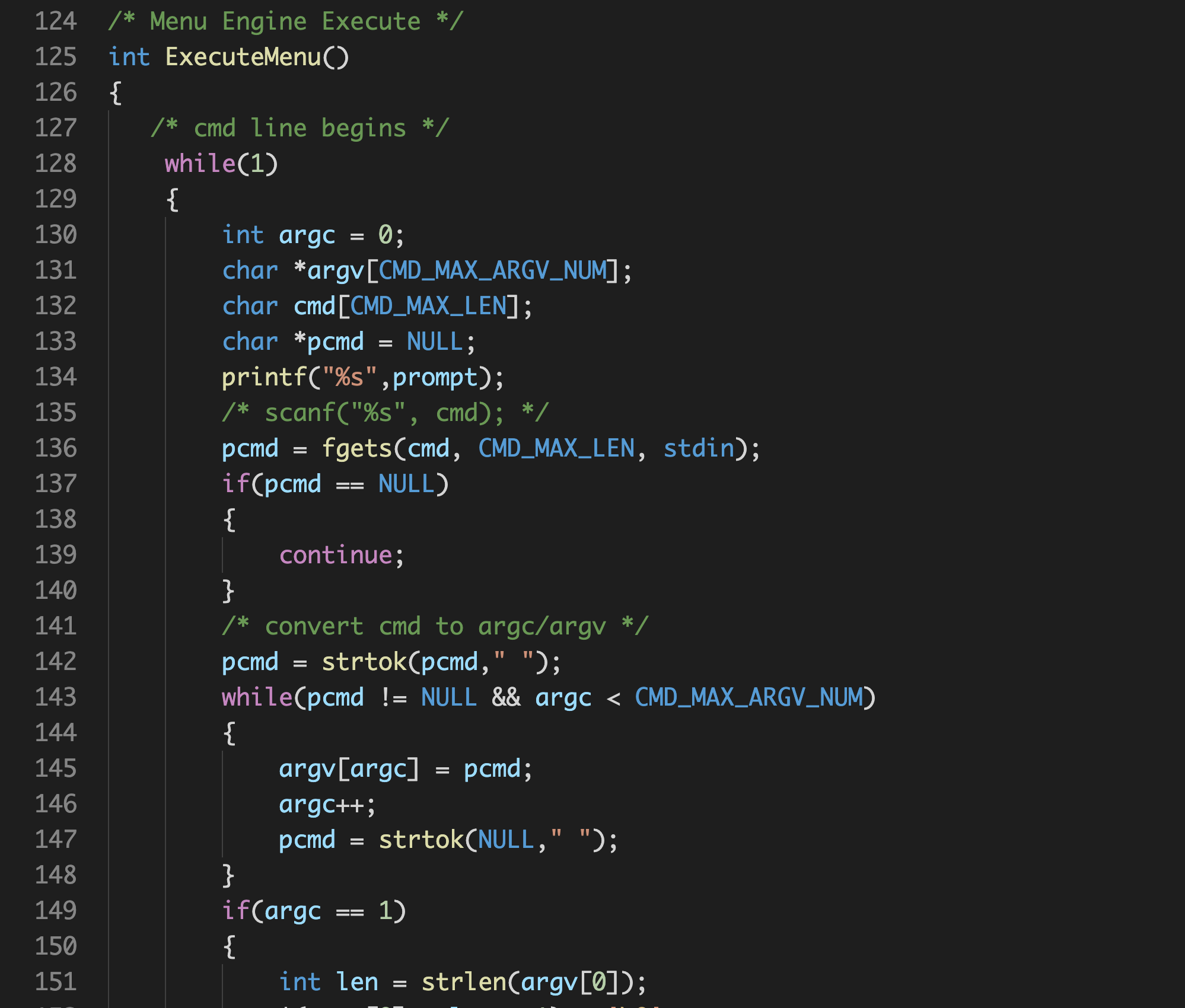
在lab3.1版本到lab4版本的过程中,孟宁老师对以下代码做了优化:
int main()
{
/* cmd line begins */
while(1)
{
char cmd[CMD_MAX_LEN];
printf("Input a cmd number > ");
scanf("%s", cmd);
tDataNode *p = head;
while(p != NULL)
{
if(strcmp(p->cmd, cmd) == 0)
{
printf("%s - %s
", p->cmd, p->desc);
if(p->handler != NULL)
{
p->handler();
}
break;
}
p = p->next;
}
if(p == NULL)
{
printf("This is a wrong cmd!
");
}
}
}
直观上看过去,显然,这里在main函数内写的过多了,那么我们可以采用模块化的思想,将一定的内容抽象出来,形成一个函数进行调用。这里与下面的面向抽象编程有一定的区别,面向抽象编程的思路是为了通用,而这里是为了简化代码,解耦。
于是,简化过后就有了lab3.2,这也是业务层与存储的分离,我们将存储单独划分为一个模块,业务层只需要使用即可,如下,单独的FindCmd函数:
tDataNode* FindCmd(tDataNode * head, char * cmd)
{
if(head == NULL || cmd == NULL)
{
return NULL;
}
tDataNode *p = head;
while(p != NULL)
{
if(!strcmp(p->cmd, cmd))
{
return p;
}
p = p->next;
}
return NULL;
}
但是这里又有了新的问题,FindCmd代码仍然是写在main函数之上,那么如果我们都是这样去书写的话,那么一定会导致我们的代码在一个文件中变得越来越臃肿。
有没有什么办法能够让我们的文件不那么臃肿呢,这就有了孟老师的lab3.3:
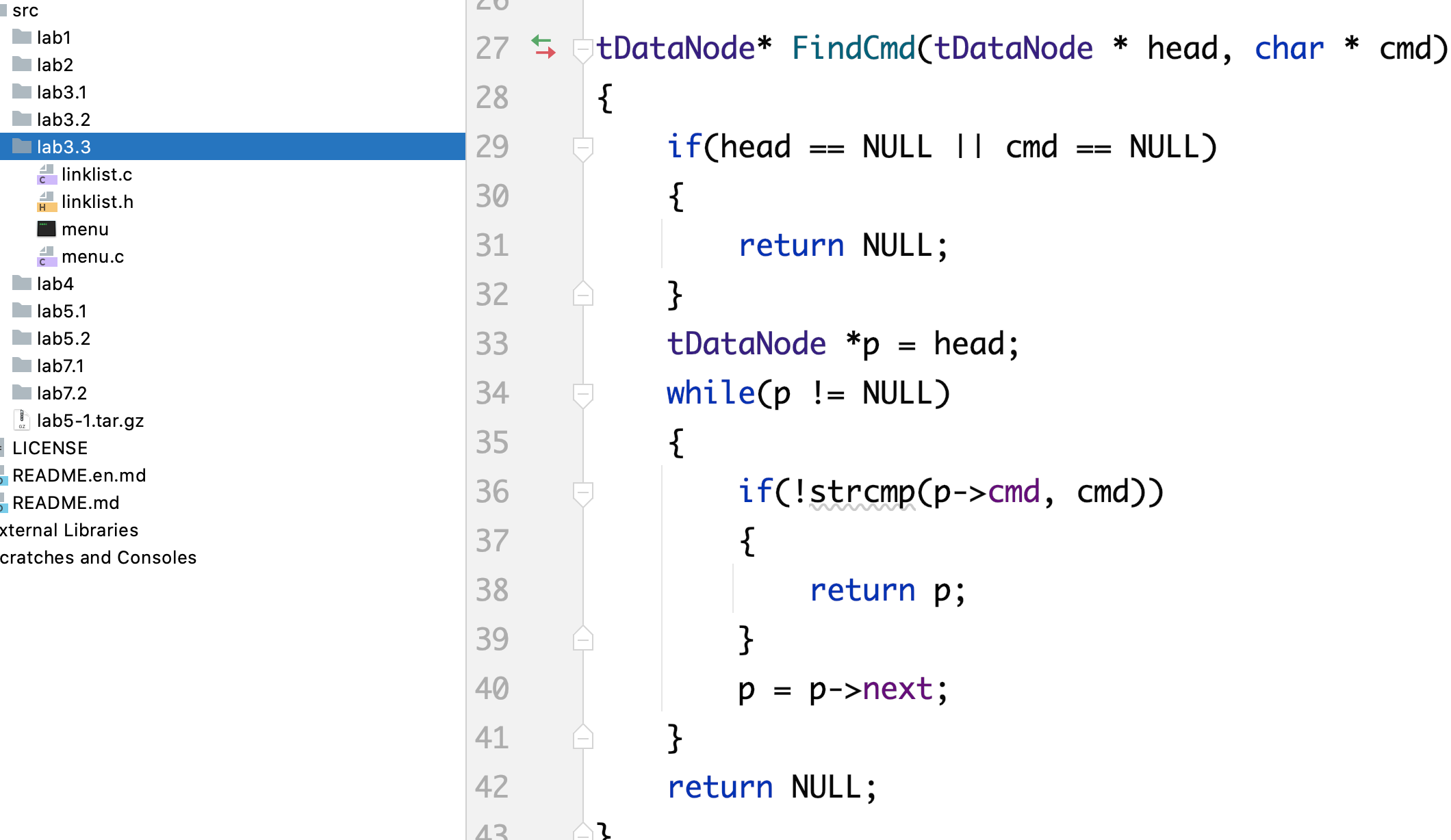
我们可以采用一个文件的方式去存储这个函数,让他形成一个文件式的单模块,同时也使得解耦更加彻底。
但是,即便是如此,我们之前所使用的链表数据结构仍然在原来的文件中,都说程序等于数据结构加算法,那么我们能不能将数据结构也单独形成模块呢,这就是lab4!(这里孟宁老师在除menu以外的文件命名中已经暴露了这一想法,一开始就是想将他们分开的)
我们将所用到的链表的一系列函数和数据结构的定义存储到一个.h和.c文件中,如下:
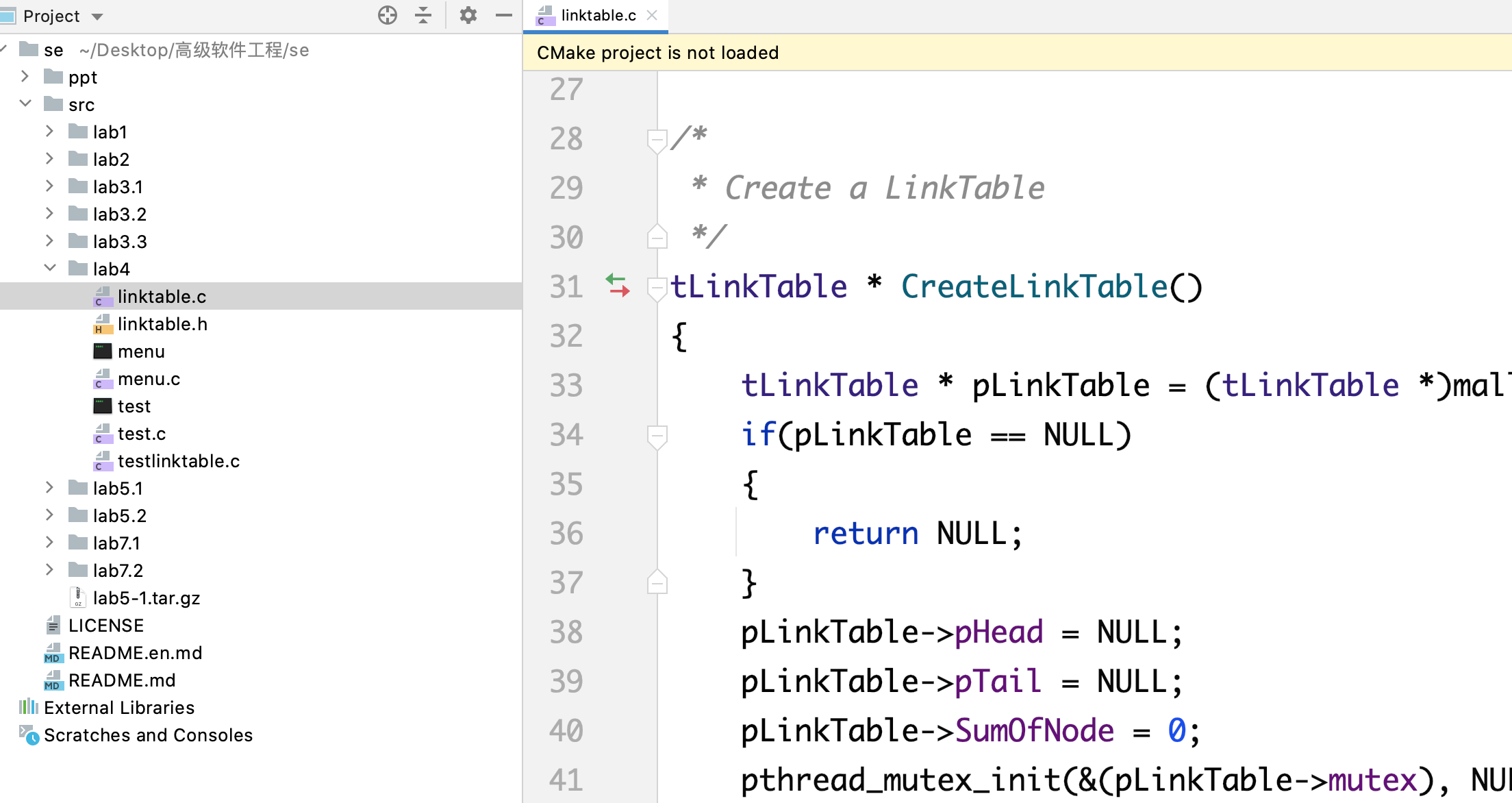
那么到此,我们就实现了链表模块的解耦,我们将链表模块单独的分开,实现了基本的模块化,满足了单一职责的原则,链表文件,自然是处理链表有关的任务,menu文件自然就是完成菜单命令行的任务。
面向抽象编程的设计思路
抽象编程,即通过抽象化的方法让程序解耦,最终达到一个松散耦合的目的,我们可以在程序中将通用的模块抽象出来,形成一个单独的,可供所有程序利用的文件。事实上,面向抽象编程或者说面向接口编程,在面向对象的语言中是有着广泛的应用的,因为我们这里的菜单小程序采用的是纯C语言,因此其语言本身并不具备面向对象的特性,但是我们却可以将一些面向对象的特性应用在我们的C语言菜单小程序中。
加上前面的模块化编程,本文的抽象思路大致为:
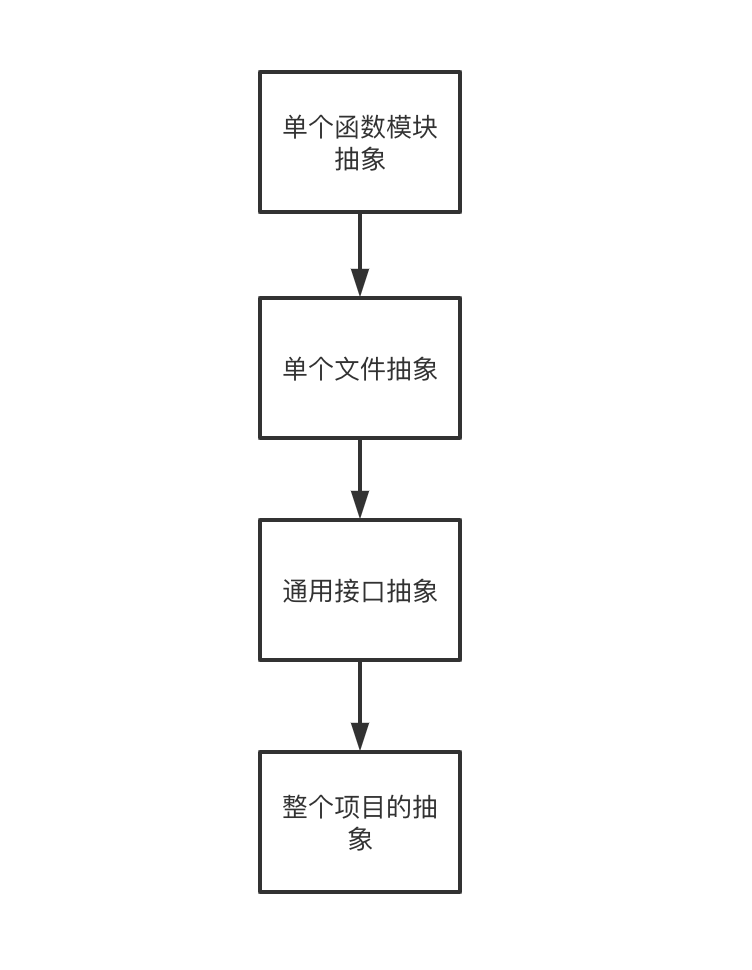
可重用接口的设计
接口的基本概念:
接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务。
在面向过程的编程中,接口一般定义了数据结构及操作这些数据结构的函数;而在面向对象的编程中,接口是对象对外开放(public)的一组属性和方法的集合。函数或方法具体包括名称、参数和返回值等。
接口规格是软件系统的开发者正确使用一个软件模块需要知道的所有信息,那么这个软件模块的接口规格定义就必须清晰明确地说明正确使用本软件模块的信息。一般来说,接口规格包含五个基本要素:
接口的目的;
接口使用前所需要满足的条件,一般称为前置条件或假定条件;
使用接口的双方遵守的协议规范;
接口使用之后的效果,一般称为后置条件;
接口所隐含的质量属性。
通用接口的定义的基本方法:
- 参数化上下文
通过参数来传递上下文的信息,而不是隐含依赖上下文环境。
- 移除前置条件
参数化上下文之后,我们发现这个接口还是有很大的局限性,就是在调用这个接口时有个前提,就是你有三个数,不是两个数,也不是5个数。必须有三个数就是前置条件。将这个前置条件移除掉,那就是我们可以求任意个数的和。
如 int sum(int numbers[], int len);
- 简化后置条件
如果编程语言支持直接获得数组的个数,或者通过分析数组数据智能得出数组的个数,我们可以进一步移除前置条件len与numbers数组长度之间的约束关系,这样后置条件变为numbers数组所有元素的和,更加简单清晰。
如 int sum(int numbers[]);
通用的链表接口,linktable.h:
/*
* LinkTable Node Type
*/
typedef struct LinkTableNode
{
struct LinkTableNode * pNext;
}tLinkTableNode;
/*
* LinkTable Type
*/
typedef struct LinkTable tLinkTable;
/*
* Create a LinkTable
*/
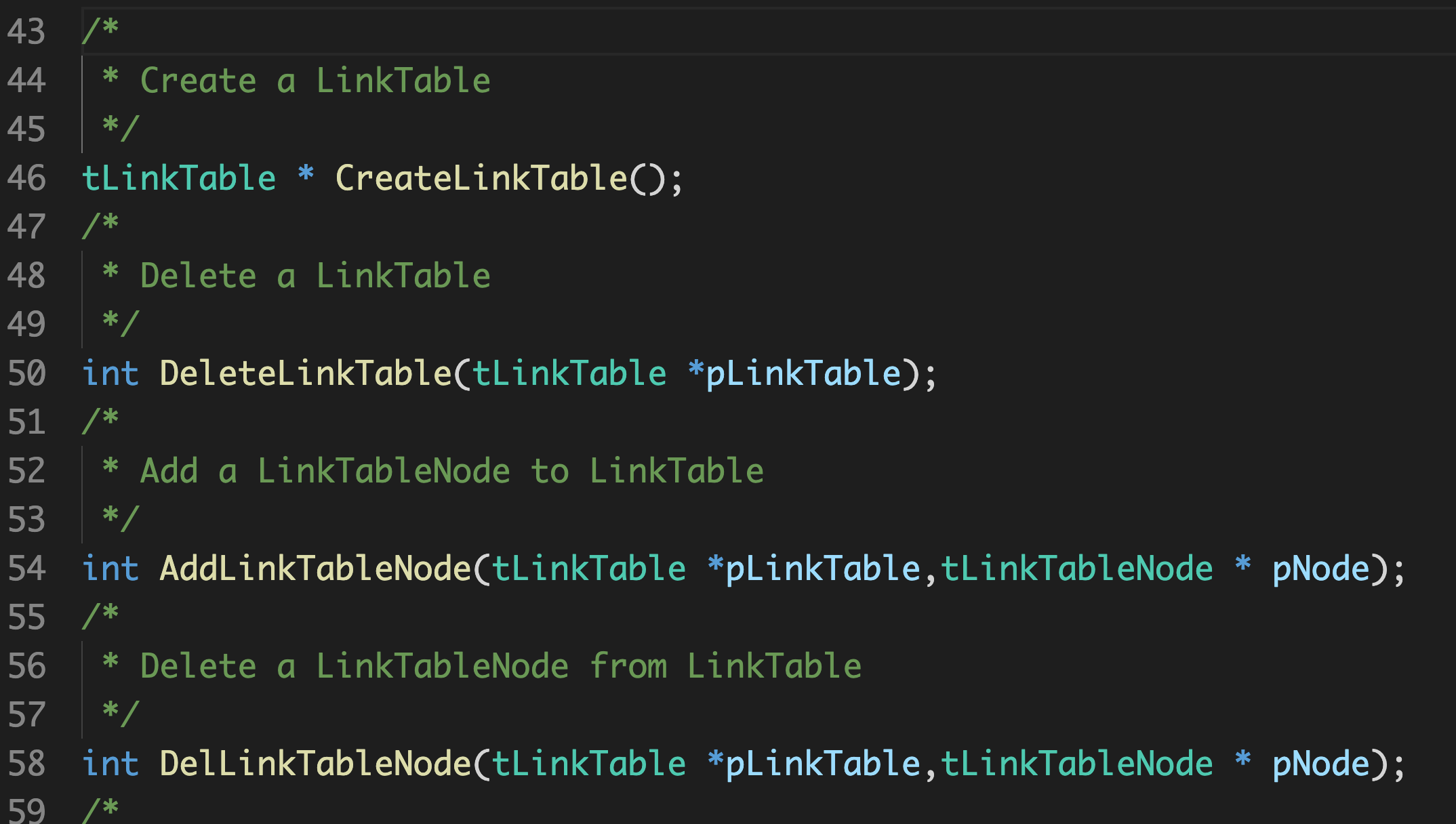
tLinkTable * CreateLinkTable();
/*
* Delete a LinkTable
*/
int DeleteLinkTable(tLinkTable *pLinkTable);
/*
* Add a LinkTableNode to LinkTable
*/
int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
/*
* Delete a LinkTableNode from LinkTable
*/
int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
/*
* Search a LinkTableNode from LinkTable
* int Conditon(tLinkTableNode * pNode,void * args);
*/
tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args);
/*
* get LinkTableHead
*/
tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable);
/*
* get next LinkTableNode
*/
tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
这是一个通用的链表接口,满足上面接口规格的5要素,拿其中的删除节点来举例吧:
int DeleteLinkTable(tLinkTable *pLinkTable);
其中包括的接口规格值如下:
| 规格 | 值 |
|---|---|
| 目标 | 删除通用链表中的结点 |
| 前置条件 | 链表必须存在 |
| 协议规范 | tLinkTable的结构体定义 |
| 后置条件 | 返回删除是否成功,结果为数字 |
| 质量属性 | 无要求 |
| 另外,该接口也是清楚地按照通用接口的定义方法来做的。如下: |
参数化上下文: 接口后的pLinkTable是一个通用的参数,这就是用参数传递上下文信息,而不是隐含依赖上下文环境。
移除前置条件: 移除了调用接口的前提,这是完全通用的。
简化后置条件: 这里并没有附加的后置条件,已经做到了简化。
这里定义的接口可以在linktable.c中逐一地实现,同时,我们可以将实现的信息主要放在.c文件中,这样就可以有效地屏蔽接口的内部信息,其他开发者可以获得简洁明了的接口方案,从而实现调用,且难以破坏其实现。
Callback函数的使用
一个代码块的用户是开发者,而非软件的最终用户。
作为一名前端程序猿,Callback函数已经写过很多很多了,但是在C程序中使用这种回调函数,还是头一次。
tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode))
{
if(pLinkTable == NULL || Conditon == NULL)
{
return NULL;
}
tLinkTableNode * pNode = pLinkTable->pHead;
while(pNode != pLinkTable->pTail)
{
if(Conditon(pNode) == SUCCESS)
{
return pNode;
}
pNode = pNode->pNext;
}
return NULL;
}
代码非常简洁明了,大致思路就是一种加权查找方式,根据我们自己设置的条件对链表内的结点进行查找。比如说,一名开发者想查找链表内值大于等于5的结点,那么他就是可以在调用时设置这样的一个条件,然后函数执行时,每走到链表的一个结点就会开启这样条件的判断,判断结点是否满足用户需求。
为什么需要Callback函数?
很简单,因为抽象,因为通用,我们需要抽象和通用的函数,设想一下,如果这里没有用Callback函数,而是直接按照某种条件来判断结点,那么这个函数就失去了通用性,只有通过这种回调的方式,才能够实现通用。
当然,在js中的Callback函数往往是用在函数的同步运行上,与这里其实并没有什么太大的关系,刚开始听孟老师的课时还想比较一下这两者之间的差异,现在我明白了,事实上,这两者最大的相似性大概就是都是进入函数之后再执行的函数,仅此而已吧。
一点改进
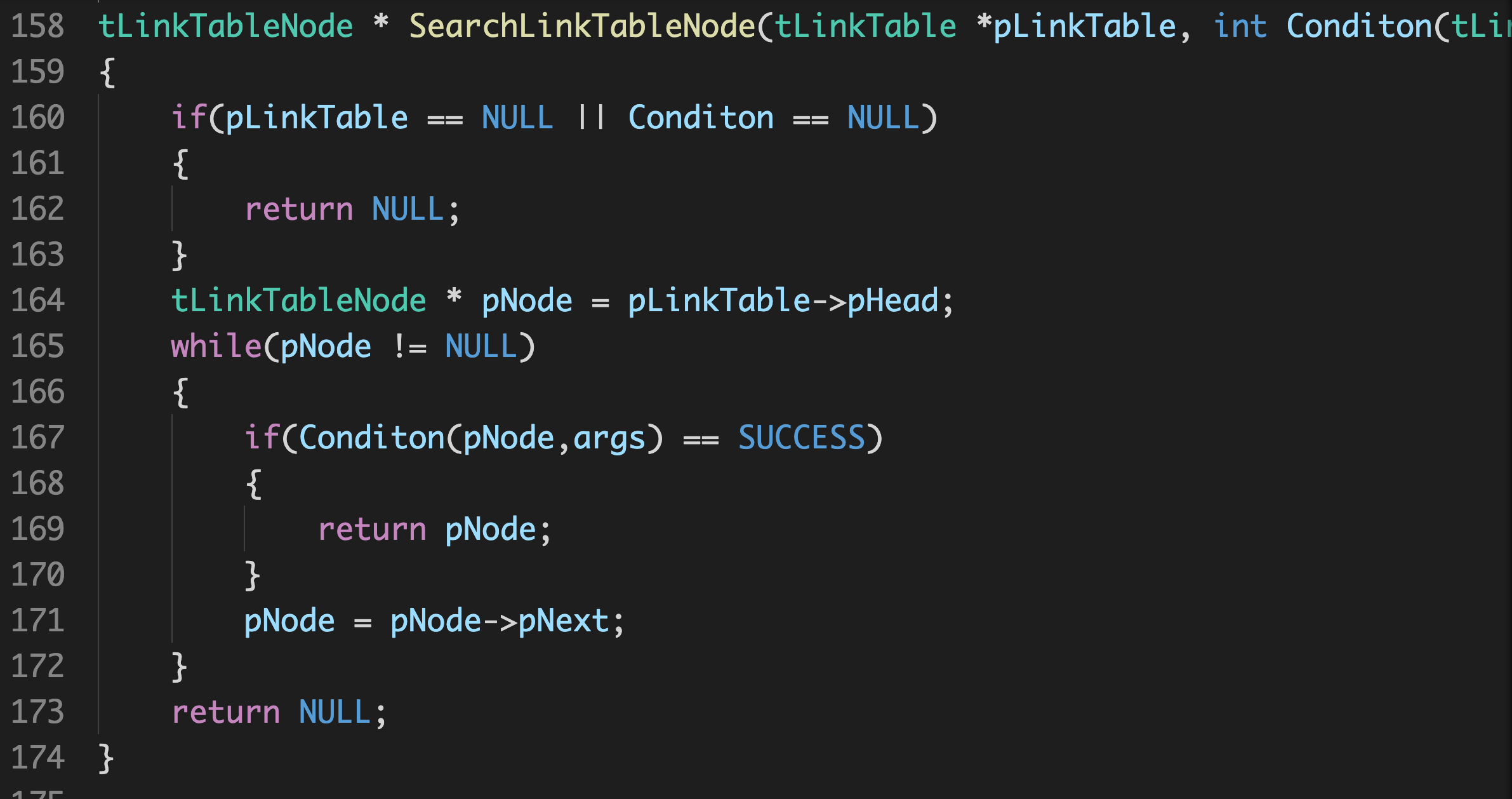
因为这里的按条件搜索默认依赖了上下文cmd命令参数,这就造成了公共耦合,那么我们也需要对这部分进行解耦。改进如下,将cmd命令采用args参数传入进去。
tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args)
{
if(pLinkTable == NULL || Conditon == NULL)
{
return NULL;
}
tLinkTableNode * pNode = pLinkTable->pHead;
while(pNode != NULL)
{
if(Conditon(pNode,args) == SUCCESS)
{
return pNode;
}
pNode = pNode->pNext;
}
return NULL;
}
这样就实现了真正的通用,解除了公共耦合,仅保留着与主函数的调用这一松散耦合,这是一个真正意义上的可重用接口。
一个小小的多态性
其实这并不是一个大的问题,仅仅是孟宁老师上课重点讲了,于是这里做一点小的总结,我认为这也是面向抽象编程的一个小的方面,但是对我们以后的编码兴许有帮助。
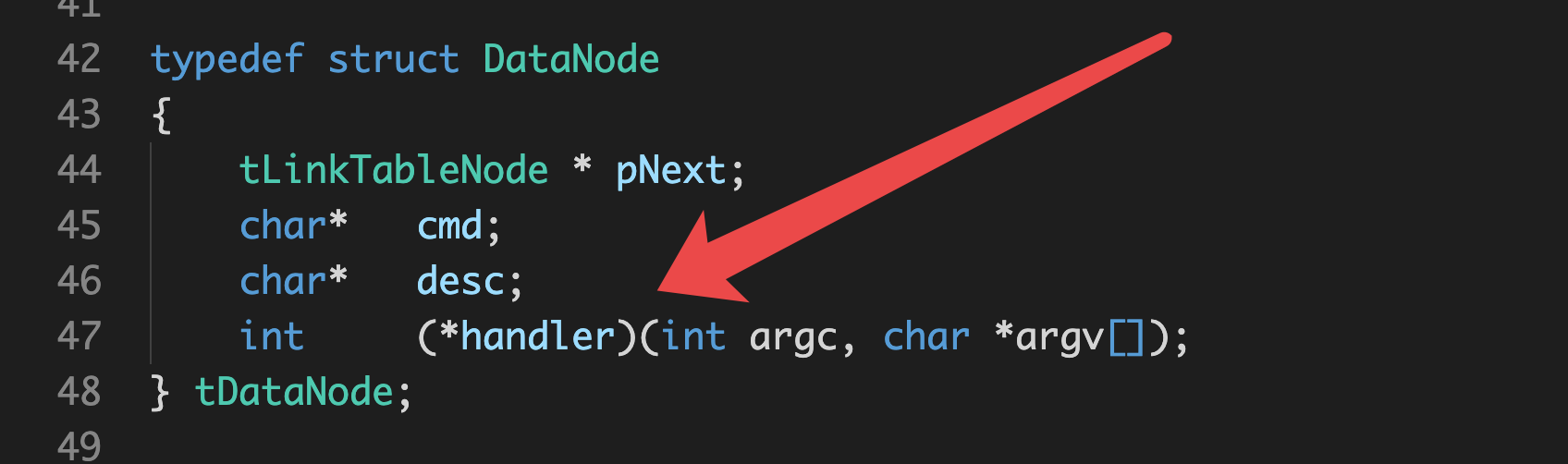
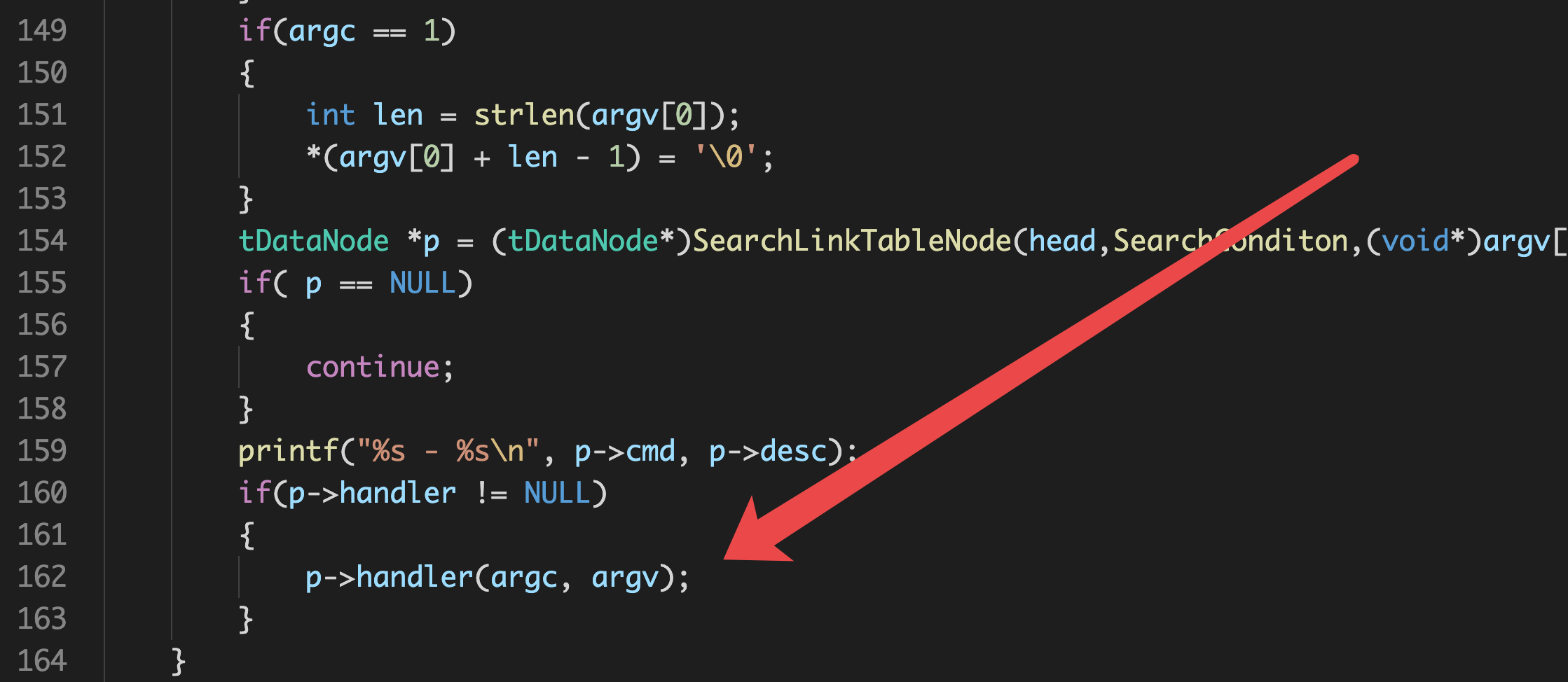
如图所示,采用了handler这样的一个抽象,handler的含义即处理的人,顾名思义,这里就是所调用的函数的一个总的抽象,使用handler,我们就可以实现根据参数的不同调用不同的函数,这是菜单小程序中一个小小的多态性。
工程化的构建系统与子系统的抽象
继续我们的面向抽象编程,当我们在做完方法、文件、接口的抽象之后,我们可以继续上升到最高的层次,将我们的菜单小程序抽象,也就是说,当我们的菜单小程序作为一个子系统运行在不同的项目中时,我们怎么去管理和应用这样的一个小程序呢?
- 使用Makefile管理Menu小程序的工程化,作为一个可重用的子系统,其他程序员在重用这个软件子系统时应该不需要了解这个子系统内部代码的组织方式,只需要了解调用接口和生成的目标文件,就可以方便的将子系统集成到自己的软件中。因此,menu子系统还需要有自带的构建系统。构建系统如下所示:

这里我自己添加了-g选项,因为gdb调试是需要用到这一选项的,如果我们上升到工程化的高度,一定也是需要对Makefile编译之后的可执行文件进行调试的。 - 使用函数对Menu小程序的重要操作进行抽象,menu子系统不像Linktable链表,Linktable链表是一个非常基础的软件模块,重用的机会非常多,应用的场景也非常多,而menu子系统的重用机会和应用场景都比较有限,我们没有必要花非常多的心思把接口定义的太通用,通用往往意味着接口的使用不够直接明了。所以在menu子系统的接口设计我们的原则是“够用就好——不要太具体,也不要太通用”。
具体的两个操作如下,一个是往Menu内添加代码,一个是执行Menu,这就够了:

安全可靠的程序环境
边界条件的处理
在平时的刷题中也经常会碰到这类问题,大多数时候,一个程序的主要代码并不是很难的,只要有思路的话。但是边界条件确实是一个很大的问题,在算法题中,测试用例常常会在边界条件处卡我们,让我们的程序做不到AC,在平时的编码设计中,也是一样的,在这个菜单小程序中,也有许多需要我们考虑的边界条件,例如:
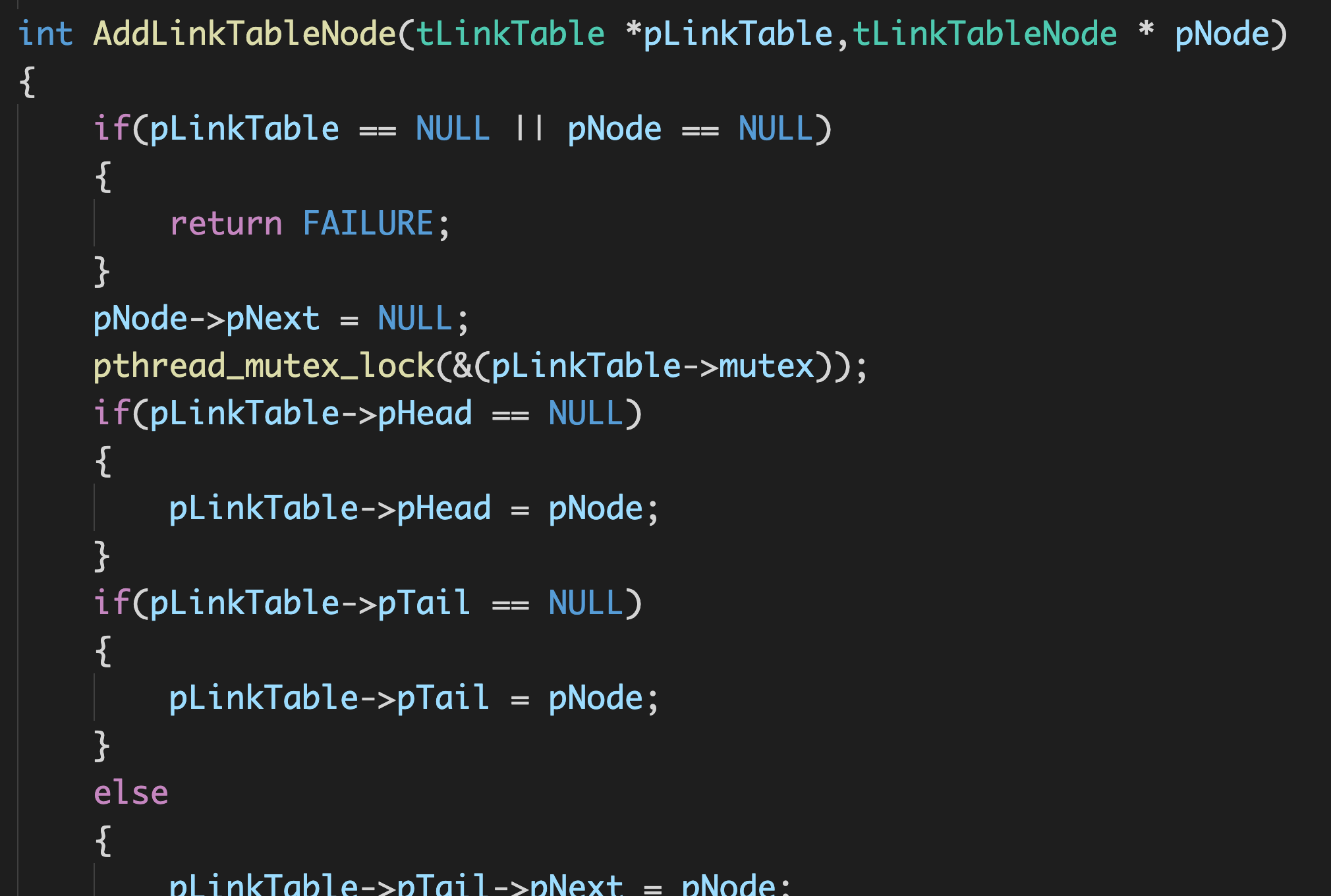
在往链表中添加结点时,如果结点为NULL或者链表为NULL,那么就是失败的,应当返回错误。如果这里不做处理,那么程序在运行到这一步时,参数出问题的话,整个程序就很容易崩溃,代码的鲁棒性就不够强。
通常,我们在考虑程序运行边界条件的时候,会往以下四个方向考虑:
- 数据类型的边界,如int类型的边界。
- 参数的边界,如我们这里的链表结点是否存在。
- 内存空间的边界,就是内存是否还够用,如果内存不够用怎么办。
- 时间的边界,例如一些前端渲染页面,图片渲染不出,那么采用alt内的内容去代替图片。
可重入函数与线程安全
可重入函数的概念:
可重入(reentrant)函数可以由多于一个任务并发使用,而不必担心数据错误。相反,不可重入(non-reentrant)函数不能由超过一个任务所共享,除非能确保函数的互斥(或者使用信号量,或者在代码的关键部分禁用中断)。可重入函数可以在任意时刻被中断,稍后再继续运行,不会丢失数据。可重入函数要么使用局部变量,要么在使用全局变量时保护自己的数据。
线程安全的概念:
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
线程安全问题都是由全局变量及静态变量引起的。若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行读写操作,一般都需要考虑线程同步,否则就可能影响线程安全。
简单而言,可重入函数就是可以在任意时刻被中断而且不丢失数据,线程安全就是多个线程对同一个变量或者文件进行写操作,有可能导致变量或者文件产生因多线程访问而出现问题。
注意:可重入的函数不一定是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题;不可重入的函数一定不是线程安全的。
为了方便介绍,我们先引入信号量机制:
/*
* LinkTable Type
*/
typedef struct LinkTable
{
tLinkTableNode *pHead;
tLinkTableNode *pTail;
int SumOfNode;
pthread_mutex_t mutex;
}tLinkTable;
其中给的mutex就是信号量。在C程序中有两种创建互斥锁的机制,动态或静态创建,可以用宏PTHREAD_MUTEX_INITIALIZER来静态地初始化锁,采用这种方式比较容易理解,互斥锁是pthread_mutex_t的结构体,而这个宏是一个结构常量,如下可以完成静态的初始化锁:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
另外锁可以用pthread_mutex_init函数动态的创建,函数原型如下:
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t * attr)
在菜单小程序中,孟宁老师采用了动态创建锁的方式:
/*
* Create a LinkTable
*/
tLinkTable * CreateLinkTable()
{
tLinkTable * pLinkTable = (tLinkTable *)malloc(sizeof(tLinkTable));
if(pLinkTable == NULL)
{
return NULL;
}
pLinkTable->pHead = NULL;
pLinkTable->pTail = NULL;
pLinkTable->SumOfNode = 0;
pthread_mutex_init(&(pLinkTable->mutex), NULL); //在创建链表结构时使用pthread_mutex_init函数对互斥锁进行初始化
return pLinkTable;
}
拿这里的增加链结点举例:
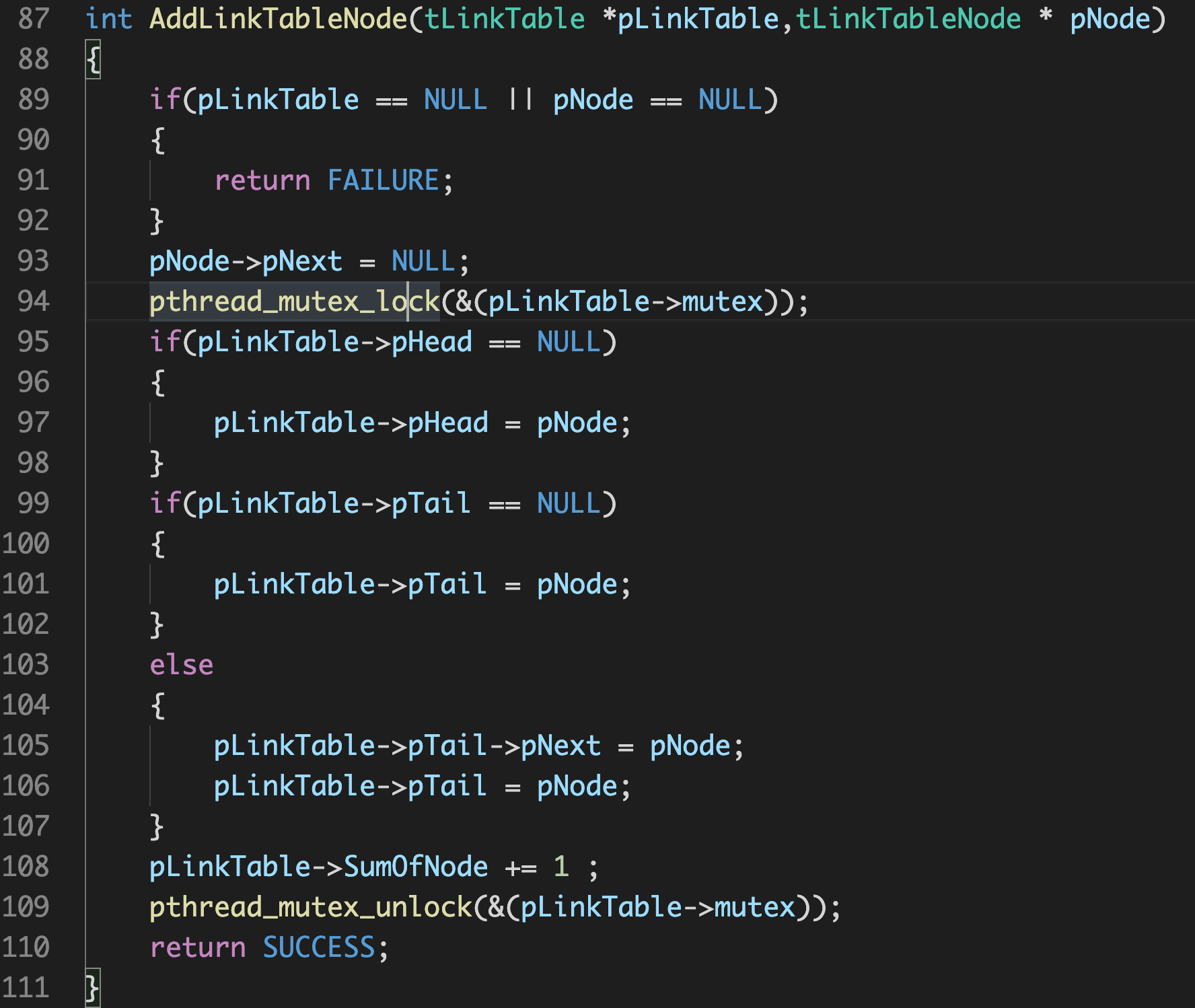
这里采用了一个简单的互斥锁,当程序运行进去对链表进行操作时加锁,使得其他程序无法进入其中对其进行操作,操作完成之后,释放锁。这就是一个线程安全的可重入程序。
再如这里的删除结点:

同样在操作前采用了一个互斥锁的方式,使得程序是一个线程安全的可重入程序。
主要模板如下:
mutex_lock() //上锁
... //进行操作
mutex_unlock() //解锁
当然,如果只是读操作,就完全没有必要考虑这些了,即使是多线程的读也不存在线程安全的问题。
所以,今后我们在设计多线程写操作时一定要注意可重入函数与线程安全的问题,提升我们代码的鲁棒性。
最后的总结
在这样一个命令行式的菜单小程序的环境配置与运行中,我学到了很多。虽然这只是一个很小的程序,严格来说,这甚至连软件这个概念都谈不上,但是这其中所蕴含的软件工程的思想却是值得我深思的。既然想做一个搬砖的码农,就应当好好地把这门高级软件工程课程上好,将软件工程作为平时学习和工作中的一个指导思想,运用实际。期待对软件工程这门学科的理解能够在日后更上一个台阶,成为一个真正的Software Engineer,而不仅仅是一个Coder。
参考资料
- https://gitee.com/mengning997/se/blob/master/README.md
- 《构建之法-现代软件工程》
- 《软件工程-实践者的研究方法》