一、限流
限流是我们在做服务端接口时,面对高并发的场景必须要考虑的问题。限流即限制流量进入
类似医院体检排号,每天放出来的号是有限的,因为只有这么多医生,多了处理
停车场满了的时候会在门口的大屏打上车位已满,车位就这么多
奶茶店的排队,系统的排号也是有限的,店铺到点了要关门
如上都是限流场景的体现,参考前面总结的高并发的系统架构,可以在几个地方去做限流:流量网关限流(如下图的流量入口网关Kong),业务网关限流(如下图对后端发起请求的API网关),接口限流,爬虫限流

二、限流方案
通用的限流算法主要有三种:计数器算法、漏桶算法、令牌桶算法。
计数器算法
简单粗暴的算法,来一个流量计数器加一,时间范围内加到限流范围了则拒绝其他请求。
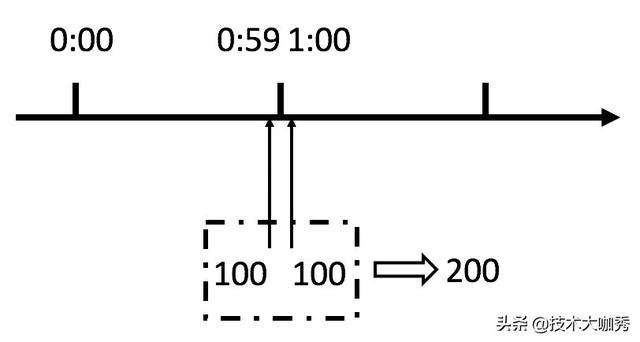
局限:并发一下子打上来容易造成原子计数锁争抢,并且会有如下图的临界问题,假设一分钟只允许100个请求,在临界点59秒和1分钟时各打入100个请求,则变成了一秒钟允许了200个请求,这是计数法的另一漏洞
漏桶算法
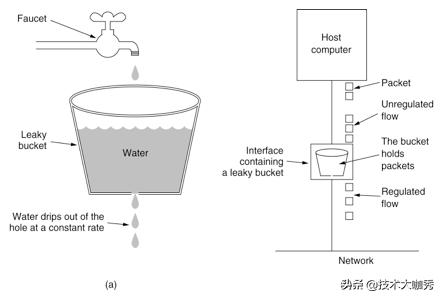
并发请求打过来时,都先进入到漏桶里,漏桶以一定的速度出水,出水速度即是请求处理的速率,比如一分钟内能处理多少请求。当水流入超过桶,即请求达到了最高请求数会溢出,可以看出漏桶算法能强行限制数据的传输速率。
漏桶算法的瓶颈:可能导致系统高峰期CPU一直处于100%状态
令牌桶算法
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,然后去执行当桶里没有令牌可取时,则拒绝服务。

无论是对于令牌桶拿不到令牌被拒绝,还是漏桶的水满了溢出,都是为了保证大部分流量的正常使用,而牺牲掉了少部分流量,这是合理的,如果因为极少部分流量需要保证的话,那么就可能导致系统达到极限而挂掉,得不偿失
三、流量网关限流
上文中的入口流量网关可以借助Kong或OpenResty实现,都是基于Nginx的高性能Web服务器,支持可编程,Lua脚本,此处示例借助OpenResty的lua-resty-lock模块和lua_shared_dict共享缓存实现一个限流器,更详细的流量网关限流可参考Kong或OpenResty官方网站
其中,lua-resty-lock是一个基于Nginx共享内存(ngx.shared.DICT)的非阻塞锁(基于Nginx的时间事件实现),说它是非阻塞的是因为它不会阻塞Nginx的worker进程,当某个key(请求)获取到该锁后,后续试图对该key再一次获取锁时都会『阻塞』在这里,但不会阻塞其它的key。当第一个获取锁的key将获取到的数据更新到缓存后,后续的key就不会再回源后端应用了,从而可以起到保护后端应用的作用。
local locks = require "resty.lock" local function acquire() local lock =locks:new("locks") local elapsed, err =lock:lock("limit_key") --互斥锁 保证原子特性 local limit_counter =ngx.shared.limit_counter --计数器 local key = "ip:" ..os.time() local limit = 5 --限流大小 local current =limit_counter:get(key) if current ~= nil and current + 1> limit then --如果超出限流大小 lock:unlock() return 0 end if current == nil then limit_counter:set(key, 1, 1) --第一次需要设置过期时间,设置key的值为1, 过期时间为1秒 else limit_counter:incr(key, 1) --第二次开始加1即可 end lock:unlock() return 1 end ngx.print(acquire())
四、业务网关和服务接口限流(Guava Limiter)
业务网关和微服务的接口,都是可编程的微服务实现,因此我们可以借助于原生Java或者一些框架组件的封装,在代码层面做限流,下面是Java代码对计数器,令牌桶的实现,令牌桶使用到了Guava的限流组件Limiter。
计数器实现:
import java.util.concurrent.atomic.AtomicInteger; /** * 原生Java实现计数器 * 场景:一分钟内只允许通过100个请求 * @author test11 */ public class Counter { //统计开始时间 private long start = System.currentTimeMillis(); //一分钟内 private long inteval = 60 * 1000; //计数器初始化,考虑到多线程场景,用原子类进行计算 private AtomicInteger calCounter = new AtomicInteger(0); //一分钟内允许的最大流量数 private int limit = 100; private boolean isLimit(){ //获取当前时间 long now = System.currentTimeMillis(); //当前时间在一分钟间隔内并且计数器小于最大的限制流量数 if(now > start + inteval && calCounter.intValue()<limit){ calCounter.getAndAdd(1); return calCounter.intValue()<=limit; }else{ //不满足要求的则重置计数器 start = now; calCounter = new AtomicInteger(1); return true; } } }
令牌桶实现:RateLimiter更多API接口详见Guava官方文档
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>19.0</version> </dependency>
/** * 稳定模式(SmoothBursty:令牌生成速度恒定) * @param args */ public static void main(String[] args) { // RateLimiter.create(2)每秒产生的令牌数 RateLimiter limiter = RateLimiter.create(2); // limiter.acquire() 阻塞的方式获取令牌 System.out.println(limiter.acquire());; System.out.println(limiter.acquire());; }
/** * 渐进模式(SmoothWarmingUp:令牌生成速度缓慢提升直到维持在一个稳定值) * @param args */ public static void main(String[] args) { // 平滑限流,从冷启动速率(满的)到平均消费速率的时间间隔 RateLimiter limiter = RateLimiter.create(2,1000l, TimeUnit.MILLISECONDS); System.out.println(limiter.acquire());; System.out.println(limiter.acquire());; }
五、爬虫限流
大型网站如天猫,淘宝,京东,亚马逊等,每天都要面对很多爬虫的信息爬取,爬虫与正常业务访问的请求比例,可以达到1:5,也就是说网站服务器承受了许多非业务的请求,对于企业来说没有用的请求。并且网络爬虫对目标页面会设置权重,实时性较高的网站比如新闻网站,设置的权重会很高,导致的结果就是短时间间隔内爬虫就会去扒,这样会导致系统的压力增加,因此需要对爬虫请求进行限流。
怎么判断你的请求是爬虫并且引流?
正规爬虫:对于正规的爬虫来说,都需要遵循Robots爬虫协议,Robots协议就是每个网站对于来到的爬虫所提出的要求,哪些路径的网页可以爬,哪些不行,什么时间点可以爬,什么时间点不行,这个协议一般放在网站的根目录下,例如百度的Robots协议的位置就是https://www.baidu.com/robots.txt 或者京东的Robots协议就在https://www.jd.com/robots.txt,遵循网络爬虫协议,会避免法律风险,也避免在被爬网站的高并发期间添堵。
不正规爬虫:对于不正规的不遵循Robots协议的爬虫来说,机器人会不分时段,部分内容的疯狂抓取网站的信息,对于这部分请求,需要作出一些反爬措施,如下:
反爬措施一:用户行为轨迹分析,浏览器拿到的js,编写用于录屏和分析鼠标轨迹的代码并将数据上传服务端做用户行为分析,分析你的移动轨迹是否符合机器人行为,对于短时间内连续操作,同个账号连续操作,一成不变拖拽等的行为轨迹做出封IP和封账号的措施
反爬措施二:分析客户端IP,短时间内频繁请求的,添加图片,滑块确认
反爬措施三:对于判定爬虫的请求,可以引流到预置的静态页或缓存页
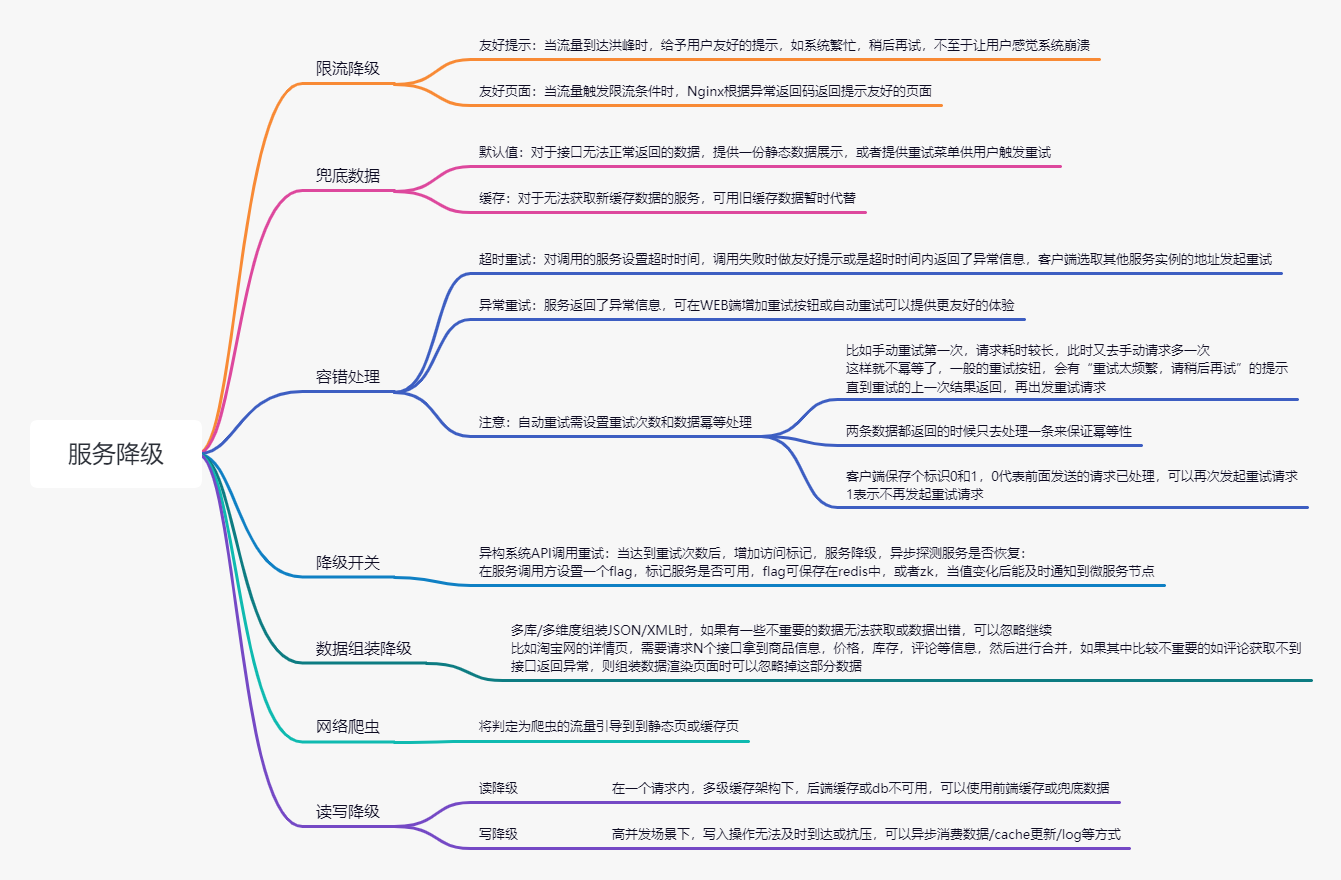
六、降级
在高并发场景下,当系统中的一些功能组件出现异常,无法继续提供服务的时候,为了保证整体系统可用性,可以牺牲一部分功能依旧提供的有损服务叫降级
类似医院排号,排不上号了,医院处理不来了的时候会给你个友好的提示,请选择其他时间就诊
停车排号,号满了的时候会在停车场门口的大屏打上车位已满
奶茶店的排队,排不上号了给你点友好的安慰,发点优惠券啥的
降级规则:距离用户越近,造成的损失越小,避免滚雪球效应,尽量在入口处或者链路的前面发现问题,降级处理
SLA:服务等级定义 SLA(Service Level Agreement)是判定压测是否异常的重要依据。压测过程中,通过监控核心服务状态的 SLA 指标数据,您可以更直观地了解压测业务的状态。SLA则是服务商与您达成的正常运行时间保证。
SLA一般以一年中能达到几个9来判定系统的高可用程度,在流量聚集的高并发系统中,一两秒可能就是百万级别的损失,因此,无论系统达到几个9的保证,都会有不可用的时间段,因此需要提供降级服务来保证系统的整体可用性,不至于让用户觉得系统崩溃
2个9 = (1-99%)X24 X 365 = 87.6 小时 = 3.65天
3个9 = (1-99.9%)X24 X 365 = 8.76 小时
4个9 = (1-99.99%)X24 X 365 = 0.876 小时 = 52.56分钟
5个9 = (1-99.999%)X24 X 365 = 0.0876 小时 = 5.256分钟
6个9 = (1-99.9999%)X24 X 365 = 0.00876 小时 = 0.5256分钟 = 31秒
降级措施: