pip install openpyxl
几个常用的对象
- Workbook:工作簿,一个包含多个Sheet的Excel文件
- Worksheet:工作表,一个Workbook有多个Worksheet,如“Sheet1”,“Sheet2”等
- Cell:单元格,存储具体的数据对象
导入包
# 导入的包在这里的用处
# 写入时间
from datetime import datetime
# 创建workbook对象
from openpyxl import Workbook
# 加载指定的Excel文件
from openpyxl import load_workbook
# 设置单元格对齐样式
from openpyxl.styles import Alignment
# 将数字转换为列字母
from openpyxl.utils import get_column_letter
创建Workbook、Worksheet
# 创建Workbook对象
wb = Workbook()
# 获取活动工作表
ws = wb.active
# 设置sheet的标题(默认为Sheet)
ws.title = 'my_sheet'
# 新建一个Sheet(后面没有对这个sheet进行操作)
new_sheet = wb.create_sheet(title='new_sheet')
写入数据
# 将数字转换为列字母 27列为AA
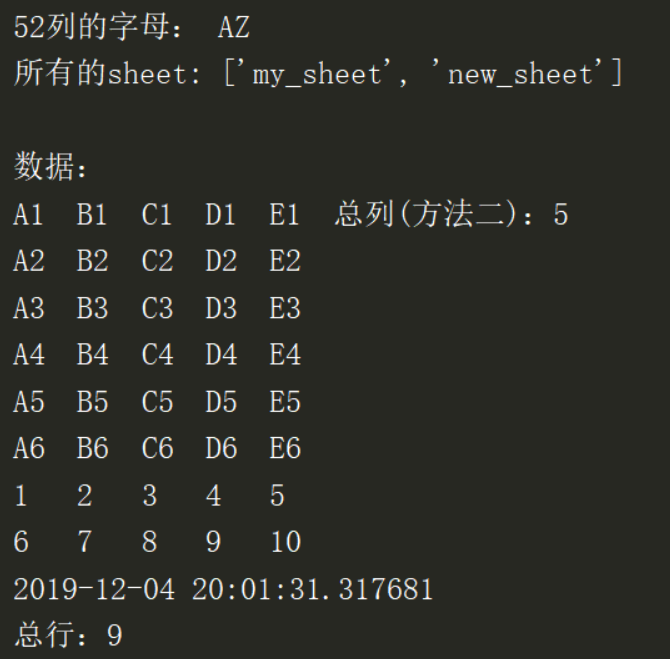
print('52列的字母:', get_column_letter(52))
# 添加数据:一个单元格一个单元格的添加
# 六行五列
for row in range(1, 7):
for col in range(1, 6):
# 将当前单元格的列和行作为数据添加进去
cell_temp = ws.cell(row=row, column=col, value='{}{}'.format(get_column_letter(col), row))
# 设置单元格对齐方式:垂直居中
cell_temp.alignment = Alignment(horizontal='center', vertical='center')
# 添加数据:一行一行的添加
ws.append([1, 2, 3, 4, 5])
ws.append((6, 7, 8, 9, 10))
# python类型将自动转换
ws['A9'] = datetime.now()
# 最大行:max_row 最大列:max_column
# 统计总行:在数据A列最后一行的下面显示总行
count_row_index = str(ws.max_row + 1)
ws['A' + count_row_index] = '总行:%d' % ws.max_row
# print('A' + count_row_index) 单元格:A10
# 统计总列:在数据第一行的最后一列后面显示总列
# 方法一:利用cell,得到具体第几行第几列的单元格
# count_col_index = ws.max_column + 1
# ws.cell(1, count_col_index, value='总列(方法一):%d' % ws.max_column)
# print(count_col_index) 单元格:第1行第6列
# 方法二:将数字转换为列字母
count_col_index = str(get_column_letter(ws.max_column + 1))
ws[count_col_index + '1'] = '总列(方法二):%d' % ws.max_column
# print(count_col_index + '1') 单元格:F1
保存
# 路径
path = r'C:UsersHlzyDesktop est.xlsx'
# 保存
wb.save(path)
读取execl
# 指定workbook
wb_read = load_workbook(path)
# 查看所有的sheet sheetnames
print('所有的sheet:', wb_read.sheetnames)
# 只有一个sheet可以直接获取活动工作表
operate_sheet = wb_read.active
# 有多个sheet,需要使用其它时,需要指定sheet
# operate_sheet = wb_read['my_sheet']
print('
数据:')
# 从每行每列的单元格挨个读取值
for row in range(1, operate_sheet.max_row + 1):
for col in range(1, operate_sheet.max_column + 1):
# 根据将当前行数和列数取出cell的值
cell_value = operate_sheet.cell(row, col).value
# 单元格的值不为空时,打印出来
print(cell_value, end=' ') if cell_value else print(end=' ')
# 换行
print()
# 可以在操作完数据后保存为新文件、或者覆盖旧文件
# operate_sheet['A1']='123'
# wb_read.save(path)
# wb_read.save(r'C:UsersHlzyDesktop est_new.xlsx')
效果
- Excel中的数据

- 打印的内容