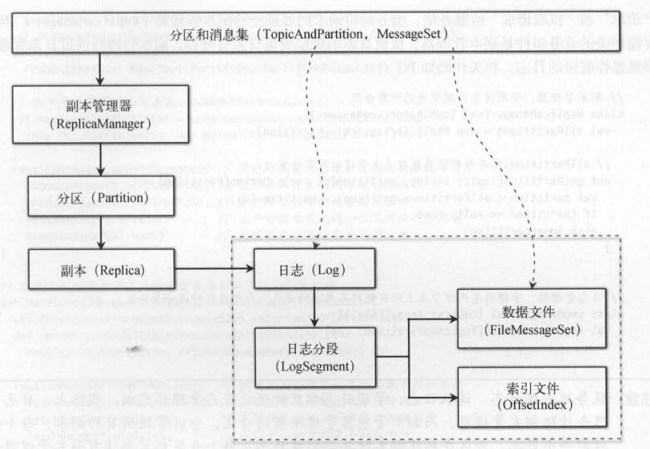
如下图中分区到 日 志的虚线表示 : 业务逻辑层的一个分区对应物理存储层的一个日志 。 消息集到数据文件的虚线表示 : 客户端发送的消息集最终会写入
日志分段对应的数据文件,存储到Kafka的消息代理节点 。
Kafka服务在启动时会先创建各种相关的组件,最后才会创建 KafkaApis 。 业务组件一般都有后台的线程,除了创建组件后,也要启动这些后台线程。
消费者客户端发送“加入组请求”和“同步组请求”给服务端,服务端通过KafkaApis将每请求的处理交给消费组的协调者( GroupCoordinator )。 与之类似,
客户端发送“生产请求”和“拉取请求”给服务端,服务端将请求的处理交给副本管理器( ReplicaManager)。 与日志存储相关的业务组件是副本管理器 ,
负责日志的底层类是日志管理器,副本管理器通过日志管理器间接地操作底层的日志 。
KafkaApis是服务端处理所有请求的入口,它只负责将请求的具体处理将发给其他组件去处理 。 服务端处理客户端发送的生产请求和拉取请求,
会先解析请求中的数据,不同的请求有不同的数据 。 生产请求包含 : 分区消息集、应答超时时间 、是否需要应答。 拉取请求包含 : 最长等待时间、
最小拉取字节数、备份副本的编号 。 由于服务端处理请求最后都要返回响应结果给客户端,它们都要事先定义一个“发送响应结果的回调方法” ,
并作为参数传给副本管理器 。
副本管理器
追加消息时,生产者客户端会发送每个分区以及对应的消息集( messagesPerPartition ) ; 拉取消息时,客户端会发送每个分区以及对应的拉取信息( fetchlnfo )。
服务端返回给客户端的响应结果也会按照分区分别返回,生产请求的响应结果( PartitionResponse )包含追加消息集到分区后返回的起始偏移量。
拉取请求的响应结果( FetchResponsePartitionData )包含每个分区的最高水位 、 每个分区的消息集。
1. 追加和读取本地日志
服务端接收客户端发送的生产请求和拉取请求都会包括多个分区 。 追加消息集和读取消息集,首先都需要获取到分区对象 , 然后再获取到分区的主副本 。
针对本地 日志文件的读写,追加和拉取在实现上稍微有些不同 。
- 追加消息集时 ,在分区( Partition )中获取主副本,并写入本地的日志文件 。
- 读取消息集时, 在副本管理器中获取分区的主副本,并读取本地的日志文件 。
2. 生产者客户端设置的应答值
生产者可以用同步和异步模式发送生产请求给服务端:同步模式下,生产者发送一条消息后,必须等待收到响应结果,才会接着发送下一条消息;
异步模式下,生产者发送一条消息后,不用等待收到上一条消息的响应结果,就可以接着发送下一条消息 。 生产者发送的生产请求还有一个
设置项(request. required. acks )一一是否需要等待服务端的应答,应答的值表示: 生产者要求主副本收到指定数量的应答,才会认为生产请求完成了 。
“应答值等于0”, 表示生产者不会等待服务端的任何应答 。 客户端将消息添加到网络缓冲区( socketbuffer )后,就认为生产请求已经完成了 。
这种情况下,主副本收到的应答数量为 0 , 意味着主副本可能都没有收到客户端发送的消息,消息有可能会丢失 。 客户端发送生产请求后,对应的响应
结果需要返回每条消息在服务端的偏移量应答值等于0时,每条消息的偏移量都是-1。
“应答值等于 1”, 表示生产者会等待主副本收到一个应答后,认为生产请求完成了 。 这一个应答,实际上就是主副本自己的应答 。主副本收到客户端发
送的消息,并存储到本地日志后,生产请求就算完成,服务端就可以返回响应结果给客户端。 这种情况下,由于主副本只收到积极发送的应答(实际
上主副本自己不会发送应答,只不过主副本写入成功,就算作一个应答),没有收到备份副本发送的应答,仍然有可能丢失消息 。 比如主副本写入本地日志后,
发送了它向己的应答,生产者认为请求完成了,但这时主副本挂掉了,备份副本都还没有及时地同步主副本写入本地日志的那些消息 。
“应答值等于- 1 (或者all )”,表示生产者发送生产请求后,“所有处于同步的备份副本 (ISR)"都向主副本发送了应答之后,生产请求才算完成。
在这之前,如果这些备份副本只要有一个没有向主副本发送应答,主副本就会阻塞并等待,生产请求就不能完成。 这种情况保证了 : JSR中的副本只要
有一个是存活的,消息就不会丢失 。 ISR一定会包括主副本,即使主副本挂掉了,只要还有一个备份副本存活,仍然可以保证消息不会丢失 。
3 . 创建延迟的生产和延迟的拉取
必须同时满足下面3个条件,服务端才需要“延迟返回生产结果”给客户端。
- 生产者等待所有ISR备份副本都向主副发送应答 :requiredAcks == - 1 。
- 生产者发送的消息有数据: MessagesPerPartition.size > 0 。
- 至少要有一个分区写入到主副本的本地日志文件是成功的 。
如果不满足上面任意一个条件,服务端就会立即返回响应结果给客户端。 服务端创建“延迟的生产”,意味着备份副本会向主副本拉取数据 。
如果没有创建“延迟的生产”,并不意味着备份副本不会向主副本拉取数据,只是生产者客户端不关心而已 。
对于拉取请求,必须同时满足下面4个条件,服务端才需要“延迟返回拉取结果”给客户端。
- 拉取请求设置等待时间 : timeout > 0 。
- 拉取请求要有拉取分区 : fetchinfo.size > 0 。
- 本次拉取还没有收集足够的数据: bytesReadable < fetchMinBytes 。
- 拉取分区时不能发生错误 :! errorReadingData 。
追加消息集到主副本的本地日志文件后,如果满足“延迟生产”的限制条件,就会创建一个“延读取主副本的本地日志文件后,如果满足“延迟拉取”的限制条
件,就会创建一个“延迟的拉取”对象( DelayedFetch )。
服务端创建延迟操作对象后,会立即尝试是否能够完成这个延迟的操作,如果不能完成会加入“延迟缓存” 。 如入延迟缓存中的延迟操作对象,
有两种完成方式:超时或者外部事件 。 超时后,服务端必须返回响应结果给客户端。 外部事件导致“限制条件”不再满足,服务端可以立即返回响应结果给
客户端。
下表列举了服务端创建的4种延迟操作对象,以及它们分别在对应的外部事件触发下,返回响应结果给客户端需要满足的条件 。
“延迟加入”的外部事件是:消费组中的所有旧消费者全部重新发送了“加入组请求” 。 这时“延迟的加入”操作才认为不再被延迟了,服务端会返回“加入组
响应结果”给每个消费者。 “延迟生产”的外部事件是:ISR的所有备份副本都向主副本发送了应答。这时“延迟的生产”操作才认为不再被延迟,服务端会
返回“生产响应结果”给生产者 。
4 延迟的操作与外部事件的关系
服务端处理生产请求,追加消息集到主副本的本地日志后,会尝试完成延迟的拉取;服务端处理备份副本的拉取请求,向主副本的本地日志
读取消息集后,会尝试完成延迟的生产。

(1)当不能返回响应结果时,什么限制条件需要让服务端创建一个延迟操作对象 。
(2)当发生限制条件对应的外部事件时,就可以尝试完成第一步创建的延迟操作 。
生产者追加消息创建延迟的生产(问题 1 ),它的限制条件是:所有备份副本发送应答给主副本。 当备份副本投取消息,
表示备价副本发送应答给主副本,就会尝试完成延迟的生产请求(问题2 )。 同样地,备份副本拉取消息创建延迟的拉取(问题 1),
它的限制条件是:拉取到足够的消息 。 当生产者追加消息到主副本后,表示有新的消息,就会尝试完成延迟的拉取请求(问题2 )。

分区与副本
副本管理器并不负责创建日志,它只是管理消息代理节点上的分区 。本管理器将日志管理器这个全局的成员变量,传给了它所管理的
每个分区 。 副本管理器的每个分区会通过日志管理器,为每个副本创建对应的日志。
“日志管理器”对“日志”进行管理,“副本管理器”对“副本”进行管理。 日志管理器( LogManager )通过每个日志对象( Log )管理日志的所有分段( LogSegment ),
副本管理器( ReplicaManager)也通过每个分区( Partition )管理分区的所有副本( Replica )。
副本机制的本质是 :将同一个分区的数据分别存储在多个消息代理节点上。
副本分主副本( LeaderReplica )和备份副本( Follower Replica ),每个分区管理多个副本 。 在实现方式上,我们可以在主副本所在的消息代理节
点上,管理其余消息代理节点上的备份副本,但是这种做法的缺点是:在需要查询分区的所有副本信息时,主副本所在的节点都需要和备份副本的节点进行通信。
另外,如果主副本所在的节点挂掉了,即使其他副本所在的节点正常。 但分区对象就不存在了,分区和副本之间的关联关系也都不复存在了 。
Kafka副本机制的做法是 :同一个分区会存在于多个消息代理节点上,并被对应节点的副本管理器所管理。 虽然每个节点上的分区在逻辑意义上都有多个副本,
但只有本地副本才有对应的日志文件(一个节点上只需要存储一个副本对应的日志文件)。 如下图所示,分区P1存在 1个节点上,每个分区都有3个副本,
深色方框表示本地副本,以及对应的日志文件。 比如,节点 1的本地副本是副本 1,它同时也是分区的主副本。 节点2的本地副本是副本2 ,
节点3的本地副本是副本3 ,它们都是分区的备份副本。
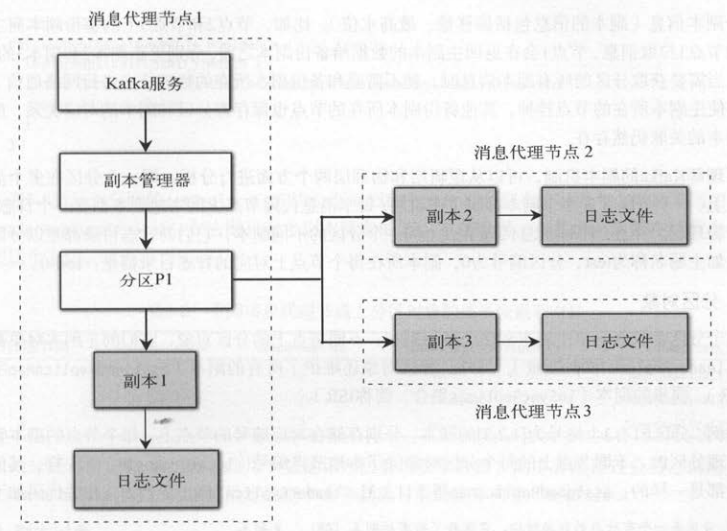
备份副本会向主副本拉取消息保持数据的同步,服务端处理备份副本的拉取请求,也会更新对应的备份副本信息(副本的信息包括偏移量、最高水位)。
比如,节点2和节点3上的备份副本向主副本所在的节点 l拉取消息,节点 l会在返回主副本的数据给备份副本之前,分别更新副本2和副本3的信息 。
这样,当需要获取分区的所有副本信息时 ,就不需要和备份副本所在的物理节点进行网络通信了 。 另外 ,即使主副本所在的节点挂掉 ,
其他备份副本所在的节点也保存着分区和副本的对应关系,所以分区和副本的关联仍然存在 。
要理解Kafka的副本机制,可以从逻辑层和物理层两个方面进行分析:同一个分区在多个消息代理节点上、 一个分区管理多个副本都属于逻辑层 ;
每个消息代理节点上的本地副本都有一个日志文件,则属于物理层 。 并且,不同消息代理节点上同一个分区的不同副本,它们的日志目 录都是以分区命名
的 。 比如主题名称为test 、 分区编号为0 ,副本所在每个节点上对应的日志目 录都是 : test-0。
1. 分区对象
每个分区都只有一个主副本和多个备份副本,不同节点上的分区对象,它们的主副本对象都是同一个( leaderRepHcaldOpt变量)。
另外,分区对象还维护了所有的副本( assignedReplicaMap字典,简称AR )、 同步的副本( inSyncReplicas集合,简称ISR )。
举例,分区P1有3个编号为 [1,2,3 ]的副本,分别存储在对应编号的节点上, 每个节点的副本管理器都会管理分区P1。 不同节点上的每个分区对象
除了本地节点编号( localBrokerId )不一样,其他的成员变量都是一样的 : assignedReplicaMap等于[ 1 ,2,3], leaderReplicaldOpt等于[2] 。
2 . 副本对象
分区创建副本分成本地副本( localReplica )和远程副本( remoteReplica )。 节点编号和副本编号相同的副本叫作本地副本,编号不同的叫作
远程副本 。本地副本和远程副本的区别如下 。
- 本地副本有日志( Log ),远程副本没有日志 。 有日志就表示有日志文件 。
- 创建本地副本时,会读取“检查点文件”中这个分区的初始最高水位 。 远程副本没有初始最高水位。
每个副本对象都定义了两个元数据 : 最高水位元数据( highwatetmarkMetadata ,简称HW 表示备份副本的数据同步位)和偏移量元数据
( logEndOffsetMetadata ,简称 LEO )。 创建副本对象时,从检查点文件读取( replication-offset-checkpoint )分区的 HW作为初始的最高水位 。
主副本所在的服务端处理备份副本的拉取请求,也会更新备份副本的偏移量元数据(步骤(4) ) , 具体步骤如下 。
(1)生产者客户端将消息集追加到分区的主副本 ,这里假设副本 1是主副本 。
(2)消息集追加到主副本的本地日志,会更新日志的偏移量元数据 。
(3)其他消息代理节点上的备份副本向主副本所在的消息代理节点同步数据 。
(4)主副本所在的副本管理器读取本地日志,井更新对应拉取的备份副本信息 。
(5)主副本所在的服务端将拉取结果返回给发起拉取请求的备份副本 。
(6)备份副本接收到服务端返回的拉取结果,将消息集追加到本地日志,更新日志的偏移量元数据 。

从图 可以看出,主副本所在节点更新备份副本的偏移量元数据,它更新的是远程副本(步骤(4))。 而如果备份副本更新本地日志的偏移量元数据,
它更新的是本地副本(步骤(6))。 这两种更新动作发生的前提都必须是:备份副本向主副本发起了拉取请求(步骤(3))。
3. “备份副本”同步数据
备份副本向主副本所在的消息代理节点发送拉取请求 , 会指定备份副本编号( replicald )。 服务端处理备份副本的拉取请求,会先读取主副本
的本地日志文件,然后用日志的读取结果( logReadResults )更新备份副本的相关信息 。
服务端处理备份副本的拉取请求,除了更新备份副本的偏移量元数据,调用maybeExpandIsr()方法可能还会扩展分区的ISR集合 。
扩展ISR集合必须满足下面3个条件。
- 这个备份副本之前不在分区的 ISR集合中,如果已经在I SR集合中,就不需要重复加入 。
- 这个备份副本必须在分区的AR集合中,只有属于分区的副本,才会加入到 ISR集合中 。
- 这个备份副本的偏移量必须大于或等于主副本的最高水位,才会加入到 ISR集合中 。
4. 偏移量 、最高水位 、 复制点
备份副本向主副本同步数据的过程中,备份副本自己会更新本地的日志偏移量,主副本所在的服务端也会更新对应备份副本的偏移量。 比如,
有 1个主副本和3个备份副本,主副本的偏移量是25, 3个备份副本的偏移量分别是[8,9,10] ,这些信息都可以通过分区对象的 assignedReplicaMap
成员变量获取。 这就意味着:当需要获取分区所有副本的日志偏移量时,直接查询分区的所有副本状态即可 。
如下图所示,备份副本同步数据时,除了更新副本的偏移量( LEO ),也会更新副本的最高水位(HW),具体步骤如下 。
(1 ) 生产者往主副本写数据,主副本的 LEO增加,初始时所有副本的HW都为0。
(2)备份副本拉取到数据,更新本地的 LEO 。 拉取响应带有主副本的 HW ,但主副本的 HW还是0 ,备份副本的HW也为0。
(3)备份副本再次拉取数据,会更新主副本的LEO。 主副本返回给备份副本的拉取响应包含最新的 HW。
(4)备份副本拉取到数据,更新本地的 LEO ,并且也会更新备份副本的 HW~
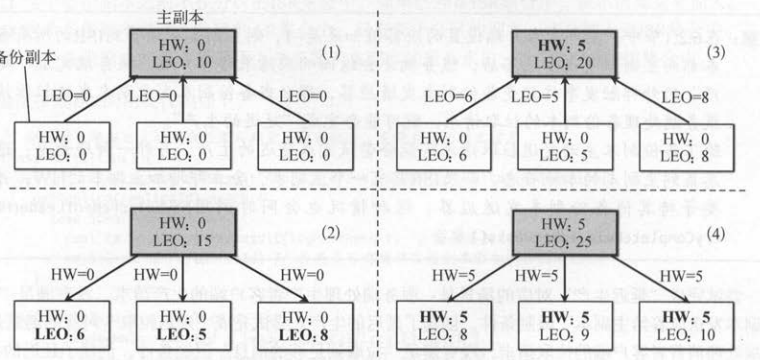
更新副本的偏移量有下面两种场景 : 更新本地日志的偏移量、更新远程的备份剧本偏移量。
- 追加消息到主副本的本地日志 、 备份副本拉取消息写到自己的本地日志,都会更新日志的偏移量。
- 主副本所在的服务端处理备份副本的拉取请求,也会更新分区中备份副本对应的偏移量 。
更新副本的最高水位也有下面两种场景 : 更新主副本的最高水位、更新备份副本的最高水位 。
- 主副本的最高水位取决于 ISR中所有副本的最小偏移量 。 最小值没有变化, 最高水位也不会变化。
- 备份副本的最高水位取决于主副本的最高水位和它自己 的偏移量 ,它会选择这两者的最小值。
备份副本的拉取线程( ReplicaFetcherThread ) 发送拉取请求 ,它在收到主副本所在服务端返回的拉取结果后,会将拉取到的消息追加到备份
副本向己的本地日志文件中,并且会更新日志的偏移量。同时,拉取结果中包含了主副本当前最新的最高水位,拉取线程会在备份副本的偏移量、主副本的最
高水位两者之间选择最小值 ,作为备份副本的最高水位。
延迟操作
Kafka的服务端处理客户端的请求,针对不同的请求 ,可能不会立 即返回响应结果给客户端 。 Kafka在处理这种类型的请求时,会将 “延迟操作”对象
( DelayedOperation )放入“延迟缓存队列”( DelayedOperationPurgatory )。 延迟的操作对象有两种方式可以从“延迟缓存队列”中完成,并从缓存队列中移除 。
- 延迟操作对应的外部事件发生时,外部事件会尝试完成延迟缓存中的延迟操作 。
- 如果外部事件仍然没有完成延迟操作,超时时间达到后,会强制完成延迟的操作 。
如下图 所示,服务端处理客户端请求,返回响应结果给客户端有下面3种情况。
- 读取或写入主副本的本地日志文件后,如果不需要延迟返回 ,立即返回 。
- 存在限制条件导致无法立即返回响应结果, 创建延迟操作 。 一旦超时时间到 了, 必须返回 。
- 外部事件发生时,判断是否可以解除限制条件 。 一旦满足条件, 可以返回 。
