ngrep 是grep(在文本中搜索字符串的工具)的网络版,他力求更多的grep特征,
用于搜寻指定的数据包
一: ngrep的安装 CentOS6.2 64位
wget http://nchc.dl.sourceforge.net/sourceforge/ngrep/ngrep-1.45.tar.bz2
下载下来是一个 bz2的包, 用bzip2命令加压成tar包,在用tar解压
bzip2 -d ngrep-1.45.tar.bz2
tar xf ngrep-1.45.tar
二:安装 ngrep
cd 进入目录 ngrep-1.45
./configure
make
make install
三:我这样安装的时候报错了, 如下:

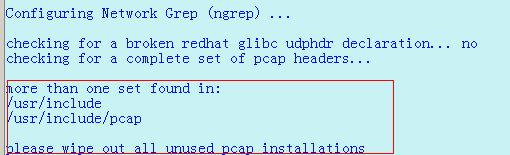
或者是这样的错误:

看错误说明,系统缺少 libpacp的包,那么yum安装 libpacp,
yum install libpcap libpcap-devel -y
重新安装ngrep
./configure --with-pcap-includes=/usr/local/include/pcap
make
make install
注意加上红色的部分,这样才正确的安装了
四:使用 http://blog.sina.com.cn/s/blog_4d14fb2b01012tqo.html
使用方法:()
usage: ngrep <-LhNXViwqpevxlDtTRM> <-IO pcap_dump> <-n num> <-d dev> <-A num>
<-s snaplen> <-S limitlen> <-W normal|byline|single|none> <-c cols>
<-P char> <-F file> <match expression> <bpf filter>
-h is help/usage
-V is version information
-q is be quiet (don't print packet reception hash marks)静默模式,如果没有此开关,未匹配的数据包都以“#”显示
-e is show empty packets 显示空数据包
-i is ignore case 忽略大小写
-v is invert match 反转匹配
-R is don't do privilege revocation logic
-x is print in alternate hexdump format 以16进制格式显示
-X is interpret match expression as hexadecimal 以16进制格式匹配
-w is word-regex (expression must match as a word) 整字匹配
-p is don't go into promiscuous mode 不使用混杂模式
-l is make stdout line buffered
-D is replay pcap_dumps with their recorded time intervals
-t is print timestamp every time a packet is matched在每个匹配的包之前显示时间戳
-T is print delta timestamp every time a packet is matched显示上一个匹配的数据包之间的时间间隔
-M is don't do multi-line match (do single-line match instead)仅进行单行匹配
-I is read packet stream from pcap format file pcap_dump 从文件中读取数据进行匹配
-O is dump matched packets in pcap format to pcap_dump 将匹配的数据保存到文件
-n is look at only num packets 仅捕获指定数目的数据包进行查看
-A is dump num packets after a match匹配到数据包后Dump随后的指定数目的数据包
-s is set the bpf caplen
-S is set the limitlen on matched packets
-W is set the dump format (normal, byline, single, none) 设置显示格式byline将解析包中的换行符
-c is force the column width to the specified size 强制显示列的宽度
-P is set the non-printable display char to what is specified
-F is read the bpf filter from the specified file 使用文件中定义的bpf(Berkeley Packet Filter)
-N is show sub protocol number 显示由IANA定义的子协议号
-d is use specified device (index) instead of the pcap default 使用哪个网卡,可以用-L选项查询
-L is show the winpcap device list index 查询网卡接口
五:应用示例:
1:捕获字符串".flv",比如要查看在Web Flash 视频中的flv文件的下载地址
ngrep -d3 -N -q .flv
interface: DeviceTNT_40_1_{670F6B50-0A13-4BAB-9D9E-994A833F5BA9} (10.132.0.0/2
55.255.192.0)
match: .flv
2:ngrep -W byline -d lo port 18080
捕捉cloudian:18080端口的request和response。-W byline用来解析包中的换行符,否则包里的所有数据都是连续的,可读性差。-d lo是监听本地网卡
ngrep -W byline -d eth0 port 80
捕捉amazon:80端口的request和response。-d eth0 是用来监听对外的网卡
3:可以用-d any来捕捉所有的包,这个很管用。
ngrep '[a-zA-Z]' -t -W byline -d any tcp port 18080
以下部分使用来自 这里:http://blog.58share.com/?p=37
4:ngrep -W byline -d lo port 18080
捕捉cloudian:18080端口的request和response。
-W byline : 用来解析包中的换行符,否则包里的所有数据都是连续的,可读性差。
-d lo : 是监听本地网卡
5:ngrep -W byline -d eth0 port 80
捕捉amazon:80端口的request和response。
-d eth0: 是用来监听对外的网卡
可以用-d any来捕捉所有的包,这个很管用。
6:ngrep ‘[a-zA-Z]‘ -t -W byline -d any tcp port 18080
抓取header头信息