原论文标题:FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks
文章是对FlowNet的进一步改进,主要贡献为如下三个方面:
- 训练数据集的调度对于模型的性能有较大的影响。
PS:光流的数据集都比较小,一般需要几个数据集一起train,故如何使用这些数据集是至关重要的。
- 使用中间光流warp图片,并以此作为一个监督信号辅助训练。
- 用一个子网络处理小位移。
经过这些改进,FlowNet 2.0只比前作慢了一点,却降低了50%的测试误差。
1. 数据集调度
最初的FlowNet使用FlyingChairs数据集训练,这个数据集只有二维平面上的运动。而FlyingThings3D是Chairs的加强版,包含了真实的3D运动和光照的影响,且object models的差异也较大。
作者作了如下设定:
- 使用前作中提出的两种网络结构:FlowNetS和FlowNetC,S代表simple,C代表complex,具体细节可参阅前作。
- 分别使用Chairs(22k)、Things3D(22k)、两者混合(从44k中sample出22k)以及用Chairs预训练再用Things3D finetune这四种数据集调度方案。
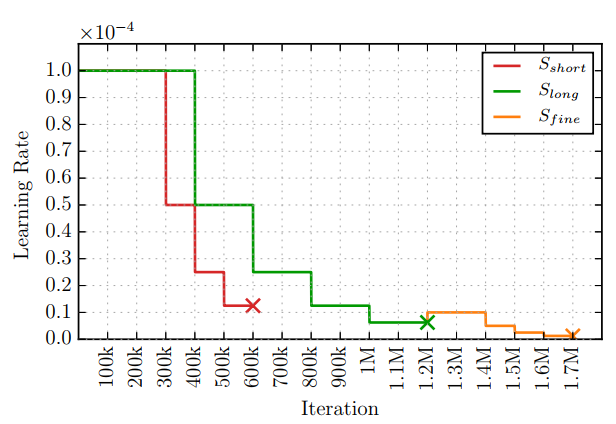
- 学习率调度策略使用Sshort和Slong+Sfine两种策略,如下图。
得出的实验结果如下图,图中的数字代表模型在Sintel数据集上的EPE,注意,Sintel是一个新的数据集,不包含在训练数据中。
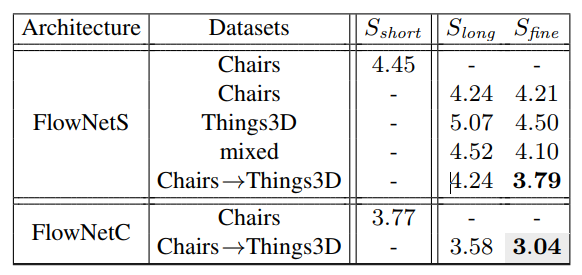
从实验结果中可以得出几个结论:
- 训练集的使用顺序很重要。即使Thins3D包含了更复杂的运动,但得出的结果却不如Chairs。(PS:根据笔者的经验,如果要在C数据集上测试的话,A和B数据集训练的模型哪个效果更好是比较玄学的,不是说哪个数据集更复杂,效果就越好。本质上还是取决于A与C和B与C之间的domain shift哪个更小。)最好的策略是现在Charis上预训练,再用Things3D fientune,这在笔者之前做过的一个Kaggle比赛中证实过,虽然任务不一样,但两种数据mixed同时训练确实效果极差。作者对此作出了猜测,Chairs帮助网络学习到颜色匹配这样的一般概念,而更复杂的3D和真实光照等信息不宜过早地强加给网络。这对于其他基于深度学习的任务也有一定的参考价值。
- FlowNetC比FlowNetS更好。
- 结果的提升。
2. Stacking Networks
传统的光流算法都依赖于迭代过程。作者尝试也使用多个模型stacking,逐步refine的手法来得到更好的结果。首先,stack两个模型。
第一个网络使用两张图片作为输入,第二个网络使用两张图片以及第一个网络预测出的光流场作为输入。
此外,作者尝试了另一种方法,如Figure 2所示,第二个网络除了上述的三个输入之外,又使用Image 2和Flow进行warp,这样,第二个网络就可以集中学习warped image和Image 1的差别,这是一种增量学习的思想。注意,作者将warped image和Image 1的误差图也显式地输入给了第二个网络。实验结果如Table 2所示。需要说明的是,warp的过程是用双线性插值,是可微的,故整个网络可以e2e训练。

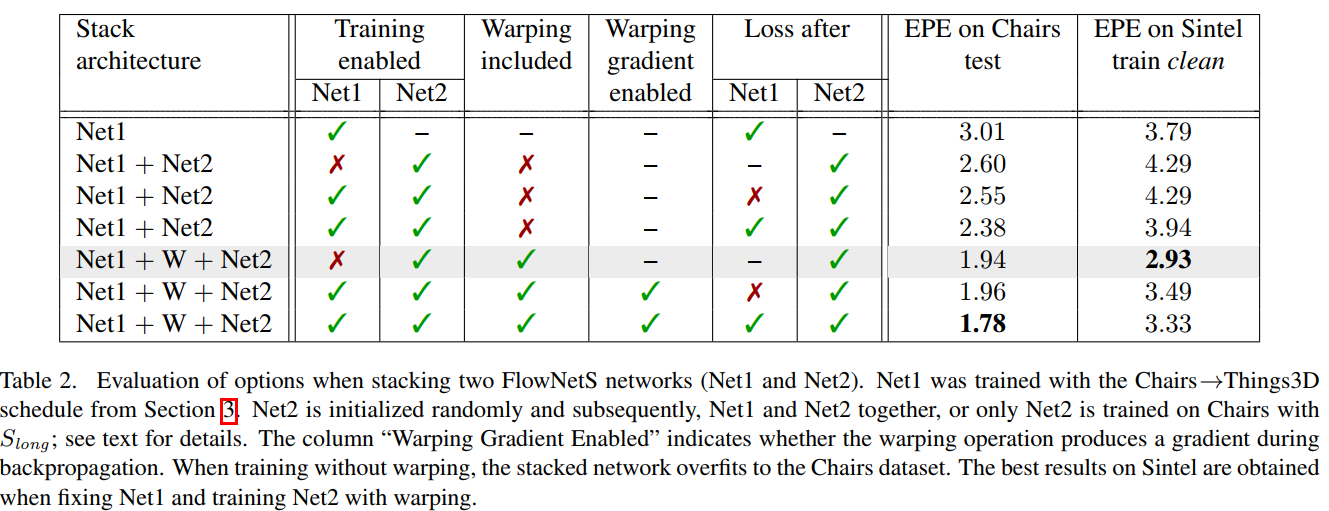
从表中可以看出,(1)仅stacking模型而不使用wrap后的图片在Chairs上有更好的结果,但在Sintel则不然;(2)Stacking with warping总是能提高结果;(3)e2e训练时,在Net1之后加中间loss是比较好的;(4)产生最好结果的做法是固定Net1,只训练Net2,当然,要加入warp操作。
出现这样的结果是符合直觉的,若e2e训练,参数量成倍增加,很容易overfitting,但分开train,参数量就没有那么大,能产生比较好的结果。
下面,作者尝试堆叠多个不同模型,即FlowNetC和FlowNetS混合使用,综合考虑速度和性能,CSS最为合理。另外,作者作了一些实验,尝试共享stacking前后模型的参数,发现没什么提升。
3. Small Displacements
上文中所用到的数据集所包含的运动往往比较快,而真实数据集如UCF101,帧间的运动往往比较小,大多在1px左右。所以,基于Chairs,作者按照UCF101的位移直方图构建了一个小位移数据集,称之为ChairsSDHom。
作者用FlowNet2-CSS网络在小位移数据上进一步训练。具体的,作者在Things3D和ChairsSDHom中分别采样了一些数据,具体的采样方法参见文章的补充材料,这里我就不去看了。经过这一轮训练,网络对于小位移的效果有了提高,而且并没有伤害大位移的效果。这个网络命名为FlowNet2-CSS-ft-sd。但是,对于subpixel motion(讲道理我不知道这是指什么,姑且理解为小于1px的运动吧),噪声仍然是个问题,作者猜测FlowNet的网络结构还是不适应这种运动。所以,作者对FlowNetS做了轻微的修改,第一层的步长2改为1,7*7改成5*5,使得网络能够更好地捕捉小位移,这个网络结构称为FlowNet2-SD。
最后,作者又设计了一个小网络来fuse FlowNet2-CSS-ft-sd以及FlowNet2-SD的结果,具体的结构没有说的太清楚,有需要的话可以去看代码。总的来看,结构还是非常复杂的,训练过程也很有讲究,改进的余地应该挺大的。
4. Experiments
这部分没有太多好说的,总之就是各种SOTA了。值得一提的是,作者还用了Motion Segmentation和Action Recognition两个任务来衡量光流的好坏,前者我了解不太多,后者就是用很常见的Two Stream模型,两个任务都需要光流作为输入。最后的结论当然是以FlowNet2得到的光流作为输入,效果最好喽!此处不再赘述。