刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度、谷歌他们的搜索引擎就是个爬虫。
现在大二。再次燃起对爬虫的热爱,查阅资料,知道常用java、python语言编程,这次我选择了java。在网上查找的
代码在本地跑大部分都不能使用,查找相关的资料教程也没有适合的。实在头疼、、、
现在自己写了一个简单爬取网页图片的代码,先分析一下自己写的代码吧
//获得html文本内容 String HTML = cm.getHtml(URL); //获取图片标签 List<String> imgUrl = cm.getImageUrl(HTML); //获取图片src地址 List<String> imgSrc = cm.getImageSrc(imgUrl); //下载图片 cm.Download(imgSrc);
简单分为四个功能方法(函数),首先是要获取html文本
//获取HTML内容 private String getHtml(String url)throws Exception{ URL url1=new URL(url);//使用java.net.URL URLConnection connection=url1.openConnection();//打开链接 InputStream in=connection.getInputStream();//获取输入流 InputStreamReader isr=new InputStreamReader(in);//流的包装 BufferedReader br=new BufferedReader(isr); String line; StringBuffer sb=new StringBuffer(); while((line=br.readLine())!=null){//整行读取 sb.append(line,0,line.length());//添加到StringBuffer中 sb.append(' ');//添加换行符 } //关闭各种流,先声明的后关闭 br.close(); isr.close(); in.close(); return sb.toString(); }
然后在获取的html文本中寻找图片,根据html标记语言不难发现图片通常带有<img>,所以
写一个关于img的正则表达式
// 获取img标签正则 private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
接着是获取img标签信息,大部分涉及的是集合接口和正则表达式的知识
//获取ImageUrl地址 private List<String> getImageUrl(String html){ Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html); List<String>listimgurl=new ArrayList<String>(); while (matcher.find()){ listimgurl.add(matcher.group()); } return listimgurl; }
然后获取img标签信息中找取图片的地址信息,需要构造图片地址的正则表达式
// 获取src路径的正则 private static final String IMGSRC_REG = "[a-zA-z]+://[^\s]*";
接着是获取图片地址的信息,大部分涉及的也是集合接口和正则表达式的知识
//获取ImageSrc地址 private List<String> getImageSrc(List<String> listimageurl){ List<String> listImageSrc=new ArrayList<String>(); for (String image:listimageurl){ Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image); while (matcher.find()){ listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1)); } } return listImageSrc; }
最后通过图片地址信息下载图片
//下载图片 private void Download(List<String> listImgSrc) { try { //开始时间 Date begindate = new Date(); for (String url : listImgSrc) { //开始时间 Date begindate2 = new Date(); String imageName = url.substring(url.lastIndexOf("/") + 1, url.length()); URL uri = new URL(url); InputStream in = uri.openStream(); FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName));//文件输出流 byte[] buf = new byte[1024]; int length = 0; System.out.println("开始下载:" + url); while ((length = in.read(buf, 0, buf.length)) != -1) { fo.write(buf, 0, length); } //关闭流 in.close(); fo.close(); System.out.println(imageName + "下载完成"); //结束时间 Date overdate2 = new Date(); double time = overdate2.getTime() - begindate2.getTime(); System.out.println("耗时:" + time / 1000 + "s"); } Date overdate = new Date(); double time = overdate.getTime() - begindate.getTime(); System.out.println("总耗时:" + time / 1000 + "s"); } catch (Exception e) { System.out.println("下载失败"); } }
展示一下运行结果:
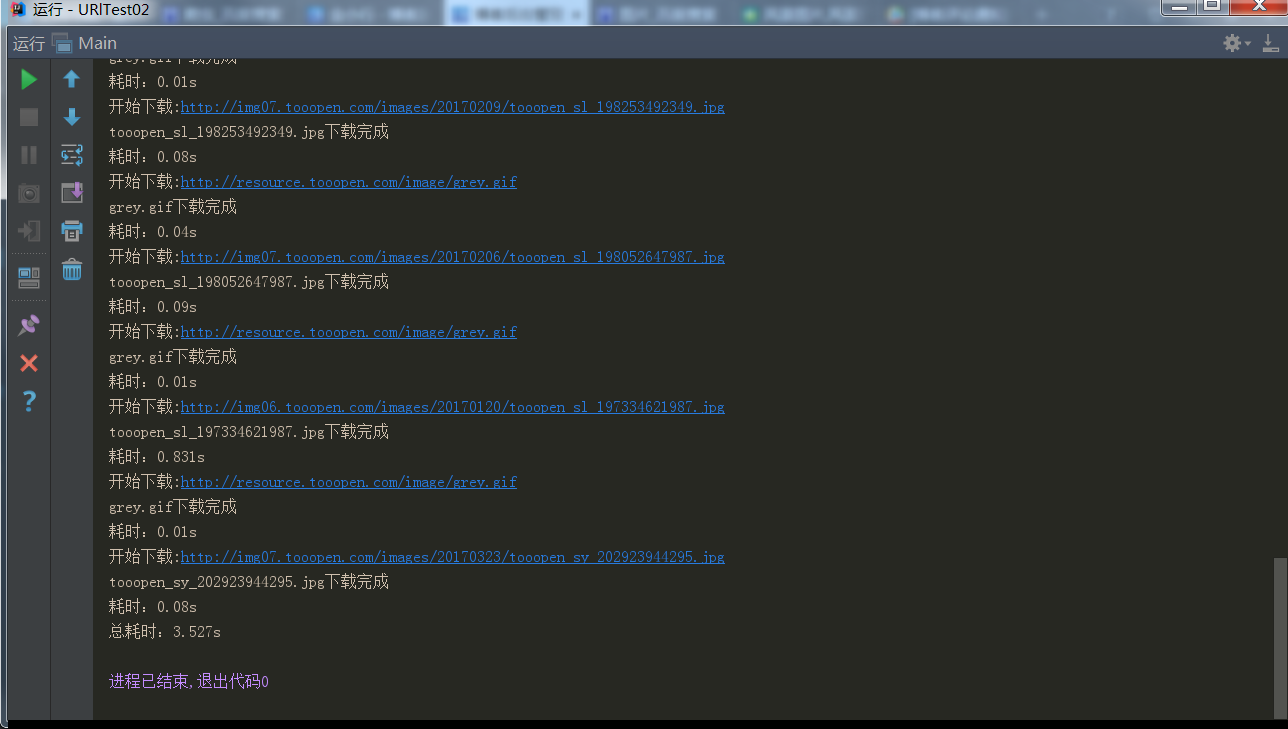
上一下全部代码:
import java.io.*; import java.net.URL; import java.net.URLConnection; import java.util.*; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Main { // 地址 private static final String URL = "http://www.tooopen.com/view/1439719.html"; // 获取img标签正则 private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>"; // 获取src路径的正则 private static final String IMGSRC_REG = "[a-zA-z]+://[^\s]*"; public static void main(String[] args) { try { Main cm=new Main(); //获得html文本内容 String HTML = cm.getHtml(URL); //获取图片标签 List<String> imgUrl = cm.getImageUrl(HTML); //获取图片src地址 List<String> imgSrc = cm.getImageSrc(imgUrl); //下载图片 cm.Download(imgSrc); }catch (Exception e){ System.out.println("发生错误"); } } //获取HTML内容 private String getHtml(String url)throws Exception{ URL url1=new URL(url); URLConnection connection=url1.openConnection(); InputStream in=connection.getInputStream(); InputStreamReader isr=new InputStreamReader(in); BufferedReader br=new BufferedReader(isr); String line; StringBuffer sb=new StringBuffer(); while((line=br.readLine())!=null){ sb.append(line,0,line.length()); sb.append(' '); } br.close(); isr.close(); in.close(); return sb.toString(); } //获取ImageUrl地址 private List<String> getImageUrl(String html){ Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html); List<String>listimgurl=new ArrayList<String>(); while (matcher.find()){ listimgurl.add(matcher.group()); } return listimgurl; } //获取ImageSrc地址 private List<String> getImageSrc(List<String> listimageurl){ List<String> listImageSrc=new ArrayList<String>(); for (String image:listimageurl){ Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image); while (matcher.find()){ listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1)); } } return listImageSrc; } //下载图片 private void Download(List<String> listImgSrc) { try { //开始时间 Date begindate = new Date(); for (String url : listImgSrc) { //开始时间 Date begindate2 = new Date(); String imageName = url.substring(url.lastIndexOf("/") + 1, url.length()); URL uri = new URL(url); InputStream in = uri.openStream(); FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName)); byte[] buf = new byte[1024]; int length = 0; System.out.println("开始下载:" + url); while ((length = in.read(buf, 0, buf.length)) != -1) { fo.write(buf, 0, length); } in.close(); fo.close(); System.out.println(imageName + "下载完成"); //结束时间 Date overdate2 = new Date(); double time = overdate2.getTime() - begindate2.getTime(); System.out.println("耗时:" + time / 1000 + "s"); } Date overdate = new Date(); double time = overdate.getTime() - begindate.getTime(); System.out.println("总耗时:" + time / 1000 + "s"); } catch (Exception e) { System.out.println("下载失败"); } } }
本人还是java初学者,能力有限,如有更好的代码或者教程可以留言,我们可以交流学习。
以上还有不足或者不对之处请指出,非常感谢个位。