从800个GPU训练几十天到单个GPU几小时,看神经架构搜索如何进化
神经架构搜索(NAS)取代了人类「第二阶」的调参工作,使我们能以两层黑箱的方式寻找最优神经网络。这一模式如果能物美价廉地应用,自然是很诱人,要知道「800 个 GPU 训练 28 天」基本不是个人承受得起的。在本文中,作者为我们介绍了 NAS 的进化史,即如何利用多种改进手段,将训练成本压缩到「凡人皆可染指」的程度。
神经架构搜索 (NAS) 改变了构建新神经网络架构的过程。这种技术可以自动地为特定问题找到最优的神经网络架构。「最优」的定义可以看成是对多个特征之间的权衡过程进行建模,例如网络的大小和准确率 。更令人印象深刻的是,现在 NAS 在单个 GPU 上仅需执行 4 个小时,过去在 800 个 GPU 上需要执行 28 天。而实现这一飞跃只花了两年时间,现在我们不需要成为 Google 员工就可以使用 NAS。
但是,研究人员如何实现这一性能飞跃呢?本文将介绍 NAS 的发展之路。
催化剂
NAS 的历史可以追溯到 1988 年的自组织网络思想 ,但直到 2017 年 NAS 才取得了首个重大突破。当时训练循环神经网络 (RNN) 来生成神经网络架构的想法出现了。

图 1:训练 NAS 控制器的迭代过程图示:训练控制器(RNN),以概率 p 采样架构 A,训练架构 A 的子网络得到准确率 R,计算 p 的梯度并且乘以 R 用于更新控制器。
简单地说,这个过程类似于人类手工寻找最佳架构的过程。基于最优操作和超参数的预定义搜索空间,控制器将测试不同的神经网络配置。在这种情况下,测试配置意味着组装、训练和评估神经网络,以观察其性能。
经过多次迭代后,控制器将了解哪些配置能够构成搜索空间内的最佳神经网络。不幸的是,在搜索空间中找出最优架构所需的迭代次数非常大,因此该过程十分缓慢。
其部分原因是搜索空间遭受了组合爆炸的影响,即搜索空间中可能的网络数量随着添加到搜索空间的组件数量而大大增加。然而,这种方法确实能够找到当前最佳 (SOTA) 网络,该网络现在被称为 NASnet ,但它需要在 800 个 GPU 上训练 28 天。如此高的计算成本使得搜索算法对大多数人来说都是不切实际的。
那么,如何改进这一想法使其更容易使用呢?在 NAS 训练过程中,大部分耗时来自于训练和评估控制器建议的网络。使用多个 GPU 可以并行训练模型,但它们的单独训练过程所耗时间仍然相当长。减少训练和评估神经网络的计算成本将对 NAS 的总搜索时间产生很大的影响。
这就引出了一个问题:如何在不对 NAS 算法产生负面影响的情况下,降低训练和评估神经网络的计算成本?
降低保真度估计
众所周知,较小的神经网络比较大的神经网络训练速度更快。原因很简单,较小网络的计算成本较低。然而,就准确率而言,较小的神经网络通常比较大的神经网络性能更差。NAS 的目标是找到 SOTA 网络架构,那么是否有方法可以在不牺牲最终性能的情况下,在搜索算法中使用较小的模型呢?
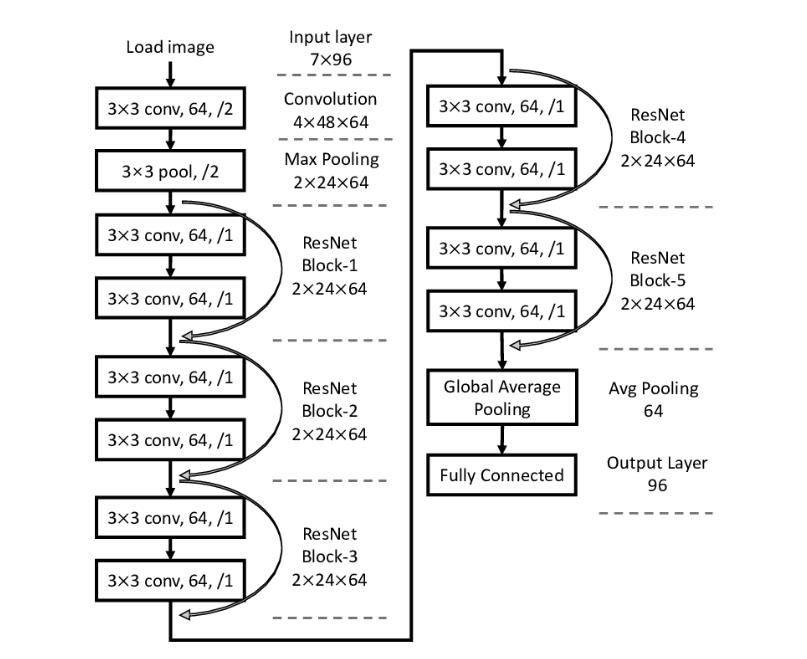
图 2:ResNet 架构示例,其中残差块表示为「ResNet Block」。
答案可以在最著名的计算机视觉架构 ResNet 中找到。在 ResNet 架构中,我们可以观察到同一组操作被一遍又一遍地重复。这些操作构成残差块,是 ResNet 的构建块。这种设计模式使得研究者可以通过改变堆叠残差块的数量,来创建同一模型的更深或更浅的变体。
此架构设计中隐含的假设是,可以通过迭代地堆叠结构良好的构建块,来创建高性能的更大型网络,这种做法完全适合 NAS。在 NAS 的语境下,这意味着先训练和评估小模型,然后扩展该神经网络。例如,先在 ResNet18 上执行 NAS,然后通过重复得到的构建块来构建 ResNet50。
用搜索构建块替代搜索整个架构,以及训练和评估较小的模型,可以极大地提高速度,研究者实现了在 450 块 GPU 上仅耗费 3-4 天的搜索时间 [5]。此外,即使只搜索构建块,该技术也能够找到 SOTA 架构。
然而,尽管这是一项巨大改进,但整个过程仍然相当缓慢,并且要想投入实际应用,训练所需的 GPU 数量必须减少。无论模型大小如何,从零开始训练神经网络始终是一个耗时的过程。有没有一种方法可以重用以前训练好的网络中的权重呢?
权重继承
如何避免从头开始训练神经网络?答案是使用权重继承,即从另一个已经训练过的网络中借用权重。在 NAS 中,搜索是在特定的目标数据集上进行的,并且有多个架构同时训练。为什么不重用权重,只更改架构呢?毕竟,搜索过程的目的是寻找架构而不是权重。为了实现重用权重,我们需要用更严格的结构定义来限制搜索空间。
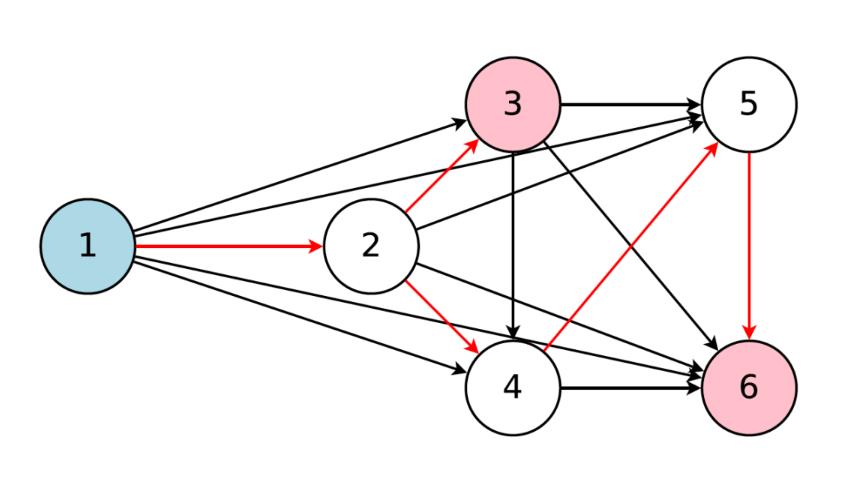
图 3:NAS 单元被建模为有向无环图(Directed Acyclic Graph),其中边表示操作,节点表示计算单元,计算单元转换并组合先前节点来创建新的隐藏状态。
通过定义允许在搜索构建块中存在的隐藏状态的数量,搜索空间变得非常有限。换句话说,构建块内操作的可能组合数量较大,但并非无限。如果将隐藏状态排序,并将它们的拓扑预定义为有向无环图 (DAG),则搜索空间如图 3 所示。
使用这个搜索空间,我们可以把控制器建议的架构看作是来自更大网络的子网络,其中较大的网络和子网络共享相同的隐藏状态(节点)。
当控制器建议使用某个网络架构时,这意味着选择一组连接(边)的子集,并为隐藏状态(节点)分配新的操作。这种形式意味着很容易以编码方式保存节点上操作的权重,从而实现权重继承。在 NAS 设置中,这意味着以前架构的权重可以用作下一个采样网络的初始化 。众所周知,初始化可以很好地独立于任务或操作运行,且由于没有从头开始训练模型,因此可以进行更快的训练。
既然现在已经不再需要从零开始训练每个模型了,那么网络的训练和评估就会快得多。在单个 GPU 上 NAS 只需要 0.45 天的训练时间,相比之前实现了约 1000 倍的提速 [6]。优化技术的结合大大提高了基于强化学习的 NAS 的速度。
这些改进都集中在更快地评估单个架构上。然而,强化学习方法并不是最快的学习方法。是否存在一个替代性搜索过程,可以更高效地遍历搜索空间?
在基于强化学习的 NAS 过程中,需要训练多个模型以便从中找到最佳模型。那么有没有办法避免训练所有的模型,而只训练一个模型呢?
可微性
在搜索空间的 DAG 形式中,训练的网络是较大网络的子网络。那么是否可以直接训练这个更大的网络,并以某种方式了解哪些操作贡献最大呢?答案是肯定的。
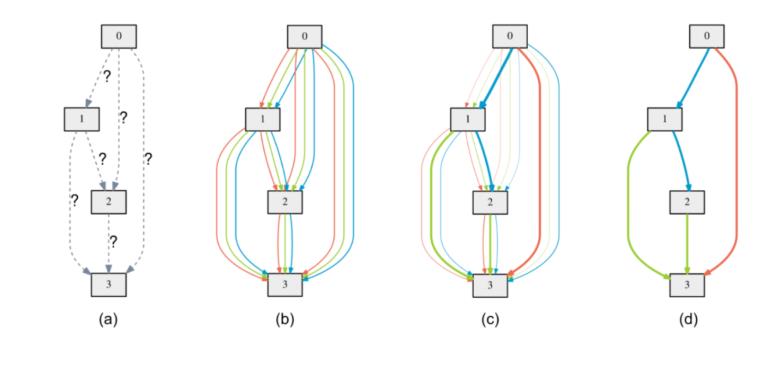
图 4:a) 边上的操作最初是未知的。b) 通过在每个边上放置候选操作的混合来连续释放搜索空间。c) 在双层优化过程(bilevel optimization)中,有些权重增加,而有些下降。d) 最终的架构通过在两个节点之间具备最大权重的边来构建 。
如果移除控制器,并将边更改为表示所有可能的操作,则搜索空间可微分。在这个密集的架构中,所有可能的操作都在每个节点上以加权和的形式组合起来。加权和是可学习参数,使得网络能够缩放不同的操作。这意味着可以缩小不利于性能的操作,扩大「良好」的操作。训练较大的网络后,剩下要做的就是观察权重并选择对应较大权重的操作。
通过对搜索空间求微分和训练更大的网络(通常称为「超级网络」),我们不再需要训练多个架构,并且可以使用标准梯度下降优化器。NAS 的可微性为未来发展开辟了许多可能性。其中一个例子是 NAS 中的可微分采样 [9],由于每个前向传播和反向传播在搜索中需要使用的操作减少,因此该方法将搜索时间缩短到只要 4 个小时。
结语
NAS 训练时间如何从多天缩短到几个小时的故事先到此为止吧。在这篇文章中,我试图概述驱动 NAS 发展的最重要想法。现在,NAS 技术已经足够高效,任何有 GPU 的人都可以使用它,你还在等什么?