让TensorFlow飞一会儿
面对大型的深度神经网络训练工程,训练的时间非常重要。训练的时间长短依赖于计算处理器也就是GPU,然而单个GPU的计算能力有限,利用多个GPU进行分布式部署,同时完成一个训练任务是一个很好的办法。对于caffe来说,由于NCCL的存在,可以直接在slover中指定使用的GPU。然而对于Tensorflow,虽然Contrib库中有NCCL,但是我并没有找到相关的例子,所以,还是靠双手成就梦想。
原理简介
TensorFlow支持指定相应的设备来完成相应的操作,所以如何分配任务是很关键的一环。GPU擅长大量计算,所以整个Inference和梯度的计算就交给GPU来做,更新参数的小事情就交给CPU来做。这就比如校长要知道整个年级的平均成绩,就把改卷子的任务分配给每个班的老师,每个班的老师批改完卷子以后,把各自班级的成绩上交给校长,校长计算个平均数就行。在这里,校长就是CPU,每个班级的老师就是GPU。
下面放出一张图来说明问题。
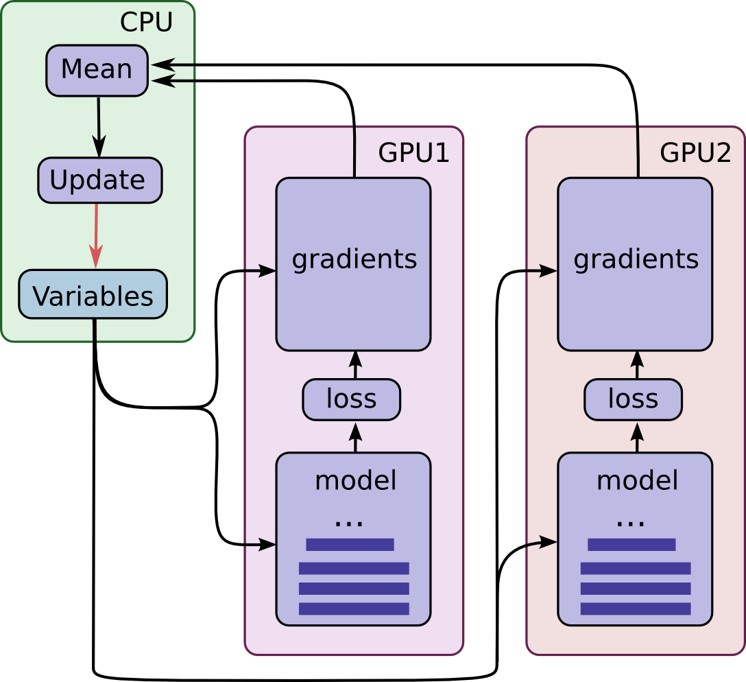
我们可以清楚的看到CPU中保存变量,GPU们计算整个model和gradients,然后把得到的梯度送回CPU中,CPU计算各个GPU送回来梯度的平均值作为本次step的梯度对参数进行更新。从图中我们可以看到只有当所有的GPU完成梯度计算以后,CPU才能求平均值,所以,整个神经网络的迭代速度将取决于最慢的一个GPU,这也就是同步更新。那能不能异步更新呢?当然是可以的把更新参数这个操作也放回到GPU上,但是异步更新会造成训练不稳定,有的快有的慢,你说到底听谁的…
在上图中我们可以看到有几个关键点需要注意:
- 在CPU上定义变量
- 在GPU上分别定义model和gradients操作,得到每个GPU中的梯度
- 又回到CPU中计算平均平均梯度,并进行参数更新
Talk is cheap, show me the code!!
好,下面放代码。
示例代码
示例代码分如下几个部分:
- 读入数据
- 在cpu中定义变量
- 搭建Inference
- 定义loss
- 定义训练过程
读入数据
由于是在不同的GPU上进行运算,所以我们采用TF官方的数据格式tfrecords作为输入,tfrecords的MNIST数据集格式可以在网上很轻易的找到。读入数据的时候我们就用标准的tfrecords数据集读入的格式。
def read_and_decode(filename_queue): reader = tf.TFRecordReader() _, serialized_example = reader.read(filename_queue) features = tf.parse_single_example( serialized_example, # Defaults are not specified since both keys are required. features={ 'image_raw': tf.FixedLenFeature([], tf.string), 'label': tf.FixedLenFeature([], tf.int64), }) image = tf.decode_raw(features['image_raw'], tf.uint8) image.set_shape([IMAGE_PIXELS]) image = tf.cast(image, tf.float32) * (1. / 255) - 0.5 label = tf.cast(features['label'], tf.int32) return image, label
这段函数会返回一个图像和标签,我们需要按照Batch的方式读入
def inputs(train, batch_size, num_epochs): if not num_epochs: num_epochs = None filename = os.path.join(FLAGS.data_dir, TRAIN_FILE if train else VALIDATION_FILE) with tf.name_scope('input'): filename_queue = tf.train.string_input_producer( [filename], num_epochs=num_epochs) image, label = read_and_decode(filename_queue) images, sparse_labels = tf.train.shuffle_batch( [image, label], batch_size=batch_size, num_threads=2, capacity=1000 + 3 * batch_size, min_after_dequeue=1000) return images, sparse_labels
到这里我们可以读入batch图像和标签。
在CPU中定义变量
我们需要把weight和biases定义在CPU中,以便进行参数的更新。注意
```Python def _variable_on_cpu(name, shape, initializer): """Helper to create a Variable stored on CPU memory. Args: name: name of the variable shape: list of ints initializer: initializer for Variable Returns: Variable Tensor """ with tf.device('/cpu:0'): dtype = tf.float32 var = tf.get_variable(name, shape, initializer=initializer, dtype=dtype) return var
构建Inference
构建Inference采用的的是卷积神经网络的架构,需要注意的是初始化的时候需要将变量定义在CPU中。
def inference(images): """Build the MNIST model. Args: images: Images returned from MNIST or inputs(). Returns: Logits. """ x_image = tf.reshape(images, [-1, 28, 28, 1]) # conv1 with tf.variable_scope('conv1') as scope: kernel = _variable_on_cpu('weights',shape=[5,5,1,32], initializer = tf.truncated_normal_initializer(stddev=5e-2)) biases = _variable_on_cpu('biases', [32], tf.constant_initializer(0.0)) conv = tf.nn.conv2d(x_image, kernel, strides=[1, 1, 1, 1], padding='SAME') pre_activation = tf.nn.bias_add(conv, biases) conv1 = tf.nn.relu(pre_activation, name=scope.name) # pool1 pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool1') # conv2 with tf.variable_scope('conv2') as scope: kernel = _variable_on_cpu('weights',shape=[5,5,32,64], initializer = tf.truncated_normal_initializer(stddev=5e-2)) conv = tf.nn.conv2d(pool1, kernel, strides=[1, 1, 1, 1], padding='SAME') biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.1)) pre_activation = tf.nn.bias_add(conv, biases) conv2 = tf.nn.relu(pre_activation, name=scope.name) # pool2 pool2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool2') # local3 with tf.variable_scope('local3') as scope: # Move everything into depth so we can perform a single matrix multiply. reshape = tf.reshape(pool2, [-1, 7 * 7 * 64]) dim = reshape.get_shape()[1].value weights = _variable_on_cpu('weights',shape=[dim,1024], initializer = tf.truncated_normal_initializer(stddev=0.04)) biases = _variable_on_cpu('biases', [1024], tf.constant_initializer(0.1)) local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name) # local4 with tf.variable_scope('local4') as scope: weights = _variable_on_cpu('weight',shape=[1024,10], initializer = tf.truncated_normal_initializer(stddev=0.04)) biases = _variable_on_cpu('biases', [10], tf.constant_initializer(0.1)) local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name=scope.name) # linear layer(WX + b), # We don't apply softmax here because # tf.nn.sparse_softmax_cross_entropy_with_logits accepts the unscaled logits # and performs the softmax internally for efficiency. with tf.variable_scope('softmax_linear') as scope: weights = _variable_on_cpu('weight',[10,10], initializer = tf.truncated_normal_initializer(stddev=1 / 192.0)) biases = _variable_on_cpu('biases', [10], tf.constant_initializer(0.0)) softmax_linear = tf.add(tf.matmul(local4, weights), biases, name=scope.name) return softmax_linear
定义Loss
定义loss的时候和单GPU的形式不同,因为我们不仅要定义损失函数,还要定义每个GPU的损失函数值和其梯度,最后再计算平均梯度。
def loss(logits, labels): """Add L2Loss to all the trainable variables. Add summary for "Loss" and "Loss/avg". Args: logits: Logits from inference(). labels: Labels from distorted_inputs or inputs(). 1-D tensor of shape [batch_size] Returns: Loss tensor of type float. """ # Calculate the average cross entropy loss across the batch. labels = tf.cast(labels, tf.int64) cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=labels, logits=logits, name='cross_entropy_per_example') cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy') tf.add_to_collection('losses', cross_entropy_mean) # The total loss is defined as the cross entropy loss plus all of the weight # decay terms (L2 loss). return tf.add_n(tf.get_collection('losses'), name='total_loss') def tower_loss(scope): """Calculate the total loss on a single tower running the MNIST model. Args: scope: unique prefix string identifying the MNIST tower, e.g. 'tower_0' Returns: Tensor of shape [] containing the total loss for a batch of data """ # Input images and labels. images, labels = inputs(train=True, batch_size=FLAGS.batch_size, num_epochs=FLAGS.num_epochs) # Build inference Graph. logits = inference(images) # Build the portion of the Graph calculating the losses. Note that we will # assemble the total_loss using a custom function below. _ = loss(logits, labels) # Assemble all of the losses for the current tower only. losses = tf.get_collection('losses', scope) # Calculate the total loss for the current tower. total_loss = tf.add_n(losses, name='total_loss') # Attach a scalar summary to all individual losses and the total loss; do # the same for the averaged version of the losses. if FLAGS.tb_logging: for l in losses + [total_loss]: # Remove 'tower_[0-9]/' from the name in case this is a multi-GPU # training session. This helps the clarity of presentation on # tensorboard. loss_name = re.sub('%s_[0-9]*/' % TOWER_NAME, '', l.op.name) tf.summary.scalar(loss_name, l) return total_loss def average_gradients(tower_grads): """Calculate average gradient for each shared variable across all towers. Note that this function provides a synchronization point across all towers. Args: tower_grads: List of lists of (gradient, variable) tuples. The outer list is over individual gradients. The inner list is over the gradient calculation for each tower. Returns: List of pairs of (gradient, variable) where the gradient has been averaged across all towers. """ average_grads = [] for grad_and_vars in zip(*tower_grads): # Note that each grad_and_vars looks like the following: # ((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN)) grads = [] for g, _ in grad_and_vars: # Add 0 dimension to the gradients to represent the tower. expanded_g = tf.expand_dims(g, 0) # Append on a 'tower' dimension which we will average over below. grads.append(expanded_g) # Average over the 'tower' dimension. grad = tf.concat(grads, 0) grad = tf.reduce_mean(grad, 0) # Keep in mind that the Variables are redundant because they are shared # across towers. So .. we will just return the first tower's pointer to # the Variable. v = grad_and_vars[0][1] grad_and_var = (grad, v) average_grads.append(grad_and_var) return average_grads
定义训练过程
训练过程的需要注意把不同的环节放在不同的devices下面。
def train(): with tf.Graph().as_default(), tf.device('/cpu:0'): # Create a variable to count the number of train() calls. This equals # the number of batches processed * FLAGS.num_gpus. global_step = tf.get_variable( 'global_step', [], initializer=tf.constant_initializer(0), trainable=False) # opt = tf.train.MomentumOptimizer(lr,0.9,use_nesterov=True,use_locking=True) opt = tf.train.MomentumOptimizer(INITIAL_LEARNING_RATE,0.9,use_nesterov=True,use_locking=True) # Calculate the gradients for each model tower. tower_grads = [] with tf.variable_scope(tf.get_variable_scope()): for i in xrange(FLAGS.num_gpus): with tf.device('/gpu:%d' % i): with tf.name_scope( '%s_%d' % (TOWER_NAME, i)) as scope: # Calculate the loss for one tower of the CIFAR model. # This function constructs the entire CIFAR model but # shares the variables across all towers. loss = tower_loss(scope) # Reuse variables for the next tower. tf.get_variable_scope().reuse_variables() # Retain the summaries from the final tower. summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope) # Calculate the gradients for the batch of data on this # MNIST tower. grads = opt.compute_gradients(loss, gate_gradients=0) # Keep track of the gradients across all towers. tower_grads.append(grads) # We must calculate the mean of each gradient. Note that this is the # synchronization point across all towers. grads = average_gradients(tower_grads) train_op = opt.apply_gradients(grads, global_step=global_step) # The op for initializing the variables. init_op = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()) # Start running operations on the Graph. allow_soft_placement must be # set to True to build towers on GPU, as some of the ops do not have GPU # implementations. sess = tf.Session(config=tf.ConfigProto( allow_soft_placement=True, log_device_placement=FLAGS.log_device_placement)) sess.run(init_op) # Start input enqueue threads. coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) try: step = 0 while not coord.should_stop(): start_time = time.time() # Run one step of the model. The return values are # the activations from the `train_op` (which is # discarded) and the `loss` op. To inspect the values # of your ops or variables, you may include them in # the list passed to sess.run() and the value tensors # will be returned in the tuple from the call. _, loss_value = sess.run([train_op, loss]) duration = time.time() - start_time # assert not np.isnan( # loss_value), 'Model diverged with loss = NaN' # Print an overview fairly often. if step % 100 == 0: num_examples_per_step = FLAGS.batch_size * FLAGS.num_gpus examples_per_sec = num_examples_per_step / duration sec_per_batch = duration / FLAGS.num_gpus format_str = ( '%s: step %d, loss = %.2f (%.1f examples/sec; %.3f ' 'sec/batch)') print(format_str % (datetime.now(), step, loss_value, examples_per_sec, sec_per_batch)) step += 1 except tf.errors.OutOfRangeError: print('Done training for %d epochs, %d steps.' % ( FLAGS.num_epochs, step)) finally: # When done, ask the threads to stop. coord.request_stop() # Wait for threads to finish. coord.join(threads) sess.close()
最后就可以调用Train()函数进行训练了。训练函数分配GPU的时候有for循环,所以可以支持不同数量的GPU。
单机多卡服务器进行深度学习的训练,构建代码比较复杂,并且需要手动分配devices,相比于NCCL的高级库好的一点就是可以针对不同的任务进行定制化的分配,以实现最大程度的优化,工作量比较大,效果也非常好。搭建的时候需要平衡一下效率和开发速度。后续还会尝试多机多卡的情况,目前还在尝试。