第一次个人编程作业
GitHub链接
计算模块接口的设计与实现过程
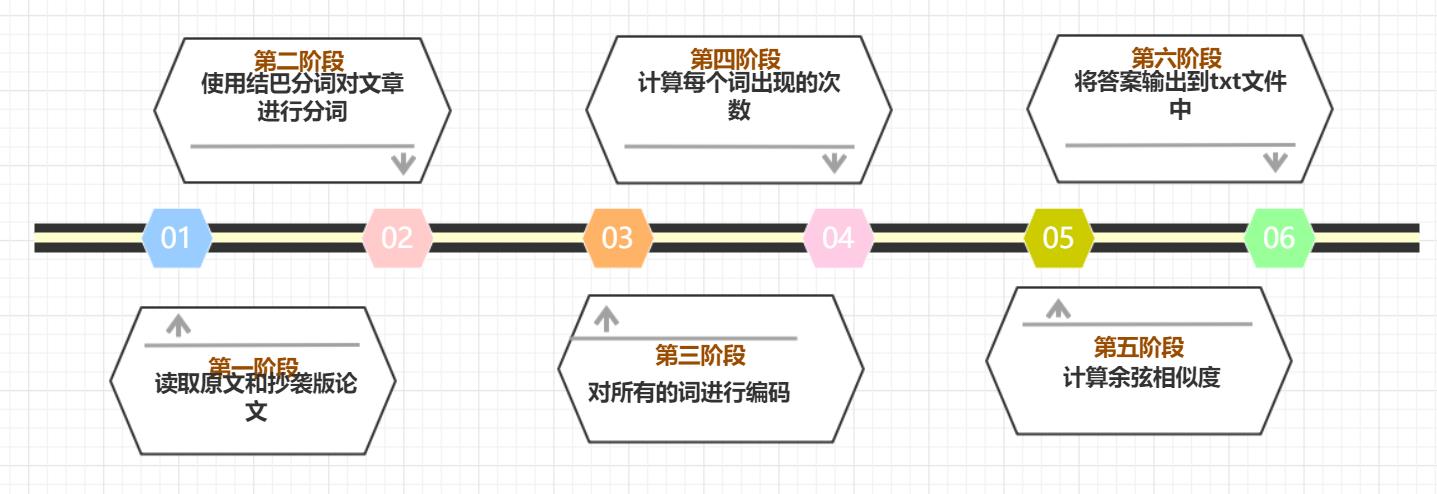
str1:去符号后的原文文件
str2:去符号后的抄袭版论文文件
alll_words:存放所有的词
str1_words_code/str2_words_code:记录str1,str2中每个词出现的次数
关键算法:
余弦相似度算法(计算个体间的相似度)
在三角形中,余弦函数的计算公式为:

在直角坐标系中,二维空间中余弦函数的计算公式为:
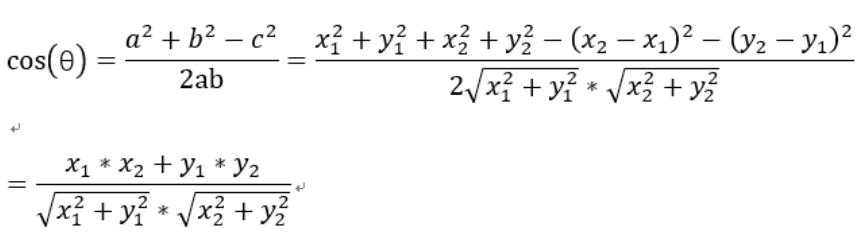
多维空间中余弦函数的计算公式为:
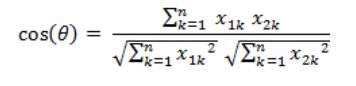
算法举例
str1:今天是星期天,天气晴,今天晚上我要去看电影
str2:今天是周天,天气晴朗,我晚上要去看电影
-
使用结巴分词和停用词表对两个句子进行分词
str1_words=['今天','是','星期天','天气','晴','今天','晚上','我','要','去','看','电影']
str2_words=['今天','是','周天','天气','晴朗','晚上','我','要','去','看','电影']
-
对所有的词进行编码
set={'今天','是','星期天',‘周天’,'天气','晴','晴朗',今天','晚上','我','要','去','看','电影'}
word_dict={'今天':0,'是':1,'星期天':2,‘周天’:3,'天气':4,'晴':5,'晴朗':6,今天':7,'晚上':8,'我':9,'要':10,'去':11,'看':12,'电影':13}
-
计算每个词出现的次数
str1_words_code=[1,1,1,0,1,1,0,1,1,1,1,1,1,1]
str2_words_code=[1,1,0,1,1,0,1,0,1,1,1,1,1,1]
-
计算余弦相似度
[cos(Θ)=frac{1*1+1*1+1*0+0*1+1*1+1*0+0*1+1*0+1*1+1*1+1*1+1*1+1*1+1*1}{sqrt{1^2+1^2+1^2+0^2+1^2+1^2+0^2+1^2+1^2+1^2+1^2+1^2+1^2+1^2}*sqrt{1^2+1^2+0^2+1^2+1^2+0^2+1^2+0^2+1^2+1^2+1^2+1^2+1^2+1^2}}=0.80 ]
余弦相似度:相似度越小,距离越大;相似度越大,距离越小。余弦值越接近1,表示两个向量越相似;余弦值越接近0,表示两个向量越不相似。
计算模块接口部分的性能改进
记录在改进计算模块性能上所花费的时间及改进的思路
改进计算模块性能上所花费的时间较少,主要是增加了try except语句的使用和对标点符号进行了处理(try:尝试执行的代码;except:出现错误的处理)
性能分析图
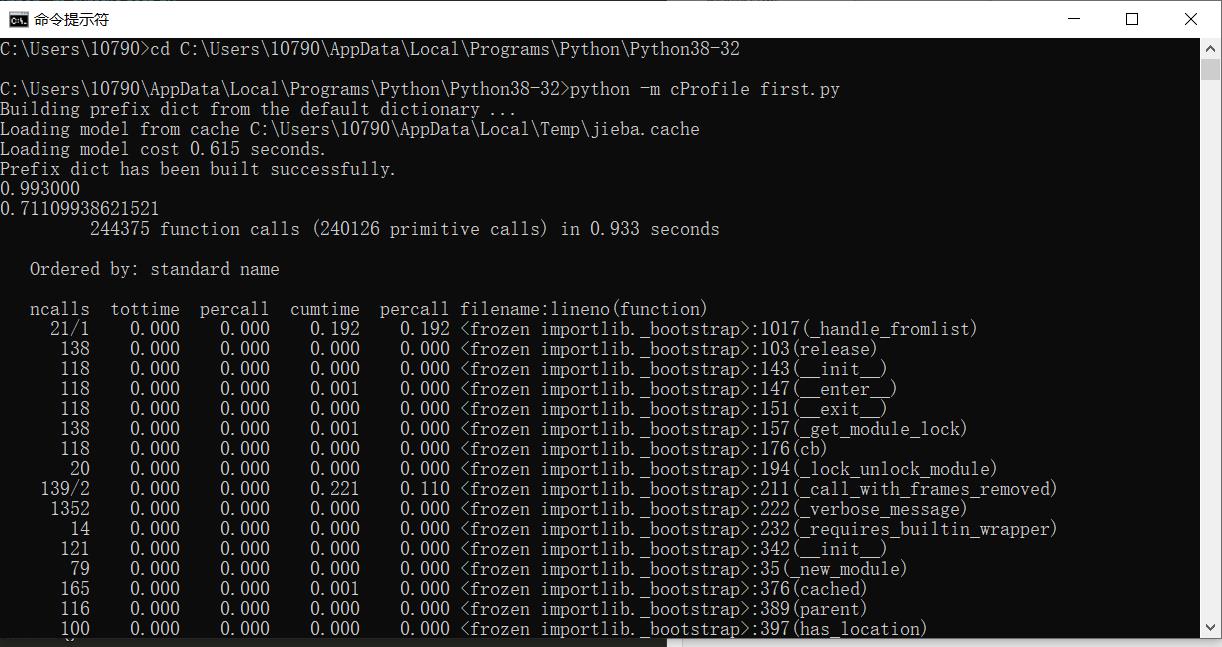
代码比较简单,没有包装成函数,所以没有展示消耗最大的函数。
计算模块部分单元测试展示
测试的函数
-
结巴分词
#使用结巴分词对str1,str2进行分词,将所有的词放在set中 cutwords = [] stops = open('stop_words.txt','r',encoding='utf-8-sig') for oneword in stops: oneword = re.sub(" ","",oneword) #将oneword中的' '替换为'' cutwords.append(oneword) #将该次放在cutwords的最后 stops.close() str1_words = [i for i in jieba.cut(str1,cut_all=True) if (i not in cutwords) and i!=''] str2_words = [i for i in jieba.cut(str2,cut_all=True) if (i not in cutwords) and i!=''] #全模式切分 all_words = set(str1_words).union(set(str2_words)) #集合 -
计算余弦值
改进前
#计算余弦值并输出结果 item1 = 0 item2 = 0 sum = 0 for i in range(len(str1_words_code)): sum += str1_words_code[i]*str2_words_code[i] item1 += pow(str1_words_code[i],2) item2 += pow(str2_words_code[i],2) answer = round(float(sum)/(math.sqrt(item1)*math.sqrt(item2)),3)#返回浮点数四舍五入的值 print("%f"%answer)改进后
#计算余弦值并输出结果 item1 = 0 item2 = 0 sum = 0 for i in range(len(str1_words_code)): sum += str1_words_code[i]*str2_words_code[i] item1 += pow(str1_words_code[i],2) item2 += pow(str2_words_code[i],2) try: answer = round(float(sum)/(math.sqrt(item1)*math.sqrt(item2)),3)#返回浮点数四舍五入的值 except ZeroDivisionError: #出现异常情况 answer = 0.00 data = open("ans.txt",'w+') print("%f"%answer,file=data) data.close()
测试的函数及构造测试数据的思路
测试的函数包括使用结巴分词进行分词,计算余弦值。使用结巴分词进行分词和计算余弦值是余弦相似度算法的核心,所以需要构造测试数据来观察和分析结巴分词后得到的结果。
先检查特例,输入相同文本时得到的重复率会不会是1,输入源文件和空白文档时能不能正常运行,结果就发现了会产生分母为0的现象,所以增加了try except语句的使用,之后便使用样例中的源文件和增删改后的抄袭版文件进行测试。
orig.txt
orig.txt
余弦相似度 = 1.000000
orig.txt
blank.txt
余弦相似度 = 0.000000
orig.txt
orig_0.8_add.txt
余弦相似度 = 0.995000
orig.txt
orig_0.8_del.txt
余弦相似度 = 0.997000
orig.txt
orig_0.8_dis_1.txt
余弦相似度 = 0.999000
orig.txt
orig_0.8_dis_3.txt
余弦相似度 = 0.998000
orig.txt
orig_0.8_dis_7.txt
余弦相似度 = 0.998000
orig.txt
orig_0.8_dis_10.txt
余弦相似度 = 0.997000
orig.txt
orig_0.8_dis_15.txt
余弦相似度 = 0.992000
orig.txt
orig_0.8_mix.txt
余弦相似度 = 0.998000
orig.txt
orig_0.8_rep.txt
余弦相似度 = 0.996000
测试覆盖率

计算模块部分异常处理说明
- 测试空白文档,产生了分母为0的现象,所以增加了try except语句的使用。

try:
answer = round(float(sum)/(math.sqrt(item1)*math.sqrt(item2)),3)#返回浮点数四舍五入的值
except ZeroDivisionError: #出现异常情况
answer = 0.00
PSP表格
| PSP2.1 | Personal Software Process Stages | 预计耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 60 | 40 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 1000 | 1200 |
| · Design Spec | · 生成设计文档 | 60 | 30 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 90 | 60 |
| · Coding | · 具体编码 | 300 | 720 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 360 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 120 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 30 |
| · 合计 | 1990 | 2640 |
总结
刚开始拿到这个题目的时候搜了一个下午的资料,毫无头绪...后面花了好长的时间去学Python,尽管最后写出来的东西不是那么满意,但是收获真的很大,拖延症晚期选手终于开始学Python了,希望接下来还能学到更多东西。冲冲冲!