一. Ubuntu Java8 的安装
添加ppa
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
安装oracle-java-installer
sudo apt-get install oracle-java8-installer
设置系统默认jdk
sudo update-java-alternatives -s java-8-oracle
java安装测试
java -version
javac -version
二、配置SSH
1. 安装ssh服务
进入shell命令,输入如下命令,查看是否已经安装好ssh服务,若没有,则使用如下命令进行安装:
sudo apt-get install ssh openssh-server
安装过程还是比较轻松加愉快的。
2. 使用ssh进行无密码验证登录
1.创建ssh-key,这里我们采用rsa方式,使用如下命令:
ssh-keygen -t rsa -P ""
2.出现一个图形,出现的图形就是密码,不用管它
cat ~/.ssh/id_rsa.pub >> authorized_keys(好像是可以省略的)
3.然后即可无密码验证登录了,如下:
ssh localhost
三、Hadoop的安装与配置
1. 下载Hadoop安装包
下载Hadoop安装也有两种方式
1.直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
2.使用shell进行下载,命令如下:
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
貌似第二种的方法要快点,经过漫长的等待,终于下载完成。

2. 解压缩Hadoop安装包
使用如下命令解压缩Hadoop安装包
tar -zxvf hadoop-2.7.7.tar.gz
解压缩完成后出现hadoop2.7.7的文件夹
3. 配置Hadoop中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml,所有的文件均位于hadoop2.7.7/etc/hadoop下面,具体需要的配置如下:
1.core-site.xml 配置如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
2.mapred-site.xml.template配置如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
3.hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zjp/hadoop-2.7.7/tmp/dfs/data</value>
</property>
</configuration>
其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
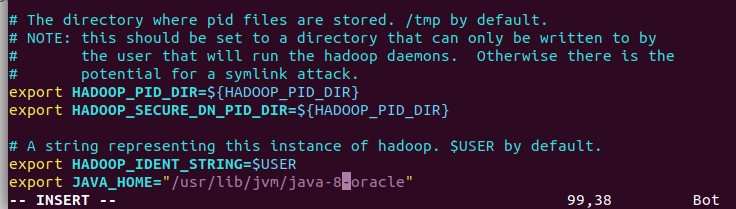
补充,如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop.env.sh里面,具体如下:
export JAVA_HOME="/usr/lib/jvm/java-8-oracle"
4.hadoop-env.sh
5.yarn-env.sh
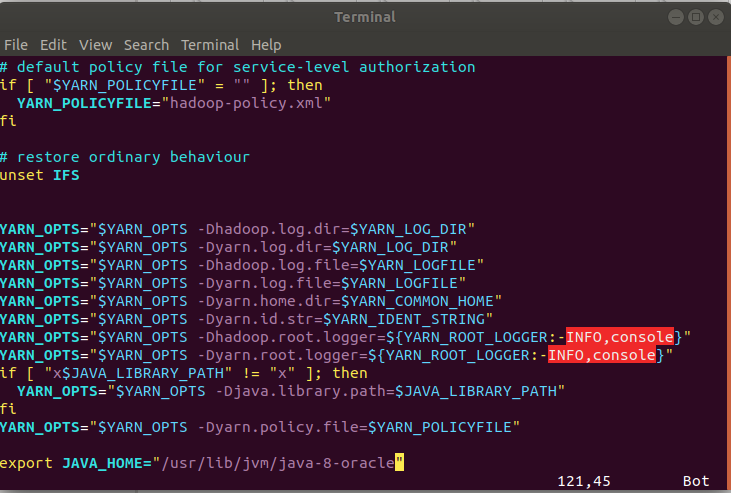
6./etc/profile

4. 运行Hadoop(截图为2.7.1版本的hadoop仅供参考)
在配置完成后,运行hadoop。
1.初始化HDFS系统
在hadop2.7.7目录下使用如下命令:
bin/hdfs namenode -format
截图如下:

过程需要进行ssh验证,之前已经登录了,所以初始化过程之间键入y即可。
成功的截图如下:

表示已经初始化完成。
2.开启NameNode和DataNode守护进程
使用如下命令开启:
sbin/start-dfs.sh,成功的截图如下:

3.查看进程信息
使用如下命令查看进程信息
jps,截图如下:

表示数据DataNode和NameNode都已经开启
4.查看Web UI
在浏览器中输入http://localhost:50070,即可查看相关信息,截图如下:
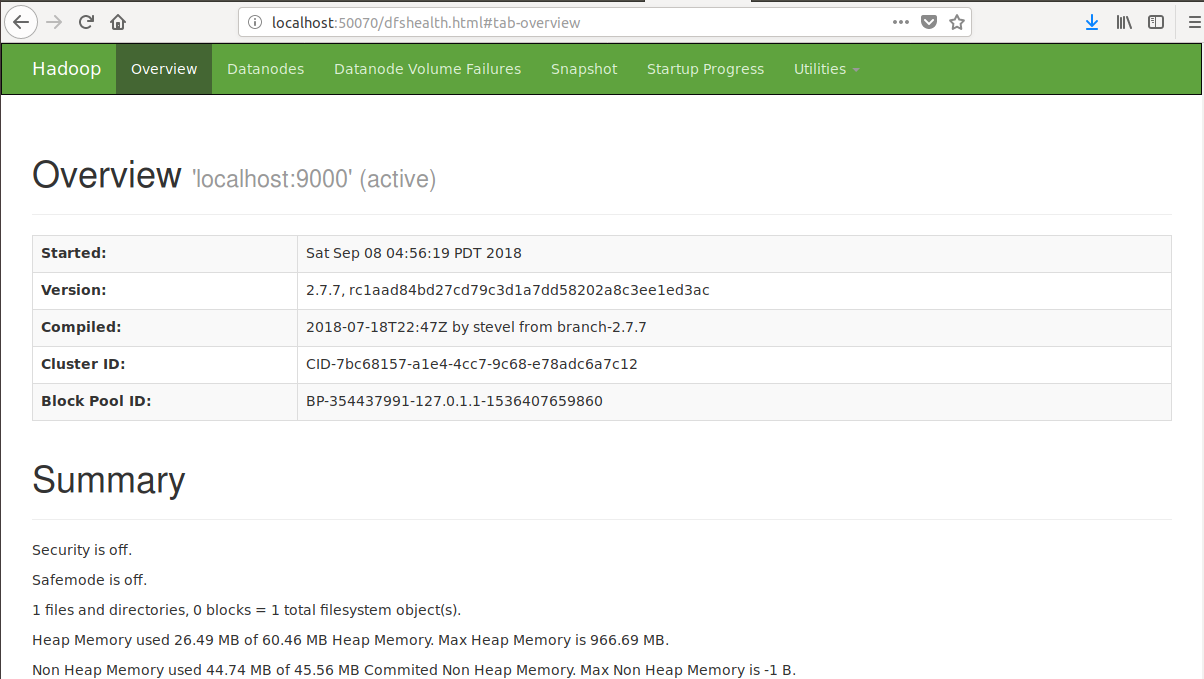
至此,hadoop的环境就已经搭建好了。
四. 备注:
1. ubantu中查看java的安装路径
有时候,使用apt-get install 安装了某个软件之后,却不知道这个软件的安装路径在哪里。 那怎么样去找出这个软件的安装路径呢?
1. 首先 java -version , 输出信息显示确实已经安装了java

2. whereis java , 输出信息看出路径在哪里

3. ls -l /usr/bin/java 看看这是否是个软连接,找出这个软连接指向的路径即可

发现输出的信息,显示还是个软连接,继续找出, ls -l /etc/alternatives/java

发现输出的信息,显示还是个软连接,继续找出,ls /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java

这个就是实实在在的文件路径了,到此,就找到了java的路径地址。
----------------------------------------------------------------------------------
参考:http://www.blogjava.net/paulwong/archive/2014/05/04/413199.html
有时候不知道java安装在哪里了 通过whereis java命令不能知道java真是的安装路径
可以通过 update-alternatives --config java 命令察看
There is only one alternative in link group java: /usr/lib/jvm/java-7-oracle/jre/bin/java
Nothing to configure.
zjp@ubuntu :~$
或者这种方法也可以:
进入到相应的目录:cd /usr/bin
查看java链接到了哪里:ls -l java
------------------------------------------------------------------------------
2. 解决hadoop启动时,没有启动Datanode
hadoop在多次运行下列指令
hadoop namenode -format
sbin/start-dfs.sh
经常会出现没有启动datanode的情况。
运行命令:jps 发现没有启动datanode线程,现给出原因和解决方案。
原因:
当我们使用hadoop namenode -format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。
解决方法:
第一种:如果dfs文件夹中没有重要的数据,那么删除dfs文件夹,再重新运行下列指令。(删除所有节点下的dfs文件夹,dfs目录在${HADOOP_HOME}/tmp/)
hadoop namenode -format
sbin/start-dfs.sh
第二种:如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中的clusterID的值替换成刚刚复制的clusterID的值即可。
总结:
其实每次运行结束Hadoop后,都应该关闭Hadoop
sbin/stop-dfs.sh
下次想重新运行Hadoop,不用再格式化namenode,直接启动Hadoop即可
sbin/start-dfs.sh